讀懂黃仁勳的Physical AI:為什麼說Crypto的機會也藏在“犄角旮旯”裡?
PANews

在達沃斯論壇上,黃仁勳到底說了什麼?
表面看,他在推銷機器人,實際上,他其實在進行一場大膽的‘自我革命’。他用一席話終結了“堆顯卡”的舊時代,卻意外地為 Crypto 赛道預設了一個千載難逢的入場券?
昨天,在達沃斯論壇上,老黃指出AI應用層正在爆發,算力需求將從“訓練側”全面轉向“推理側”和“Physical AI(物理AI)側”。
這就很有意思了。
英偉達作為AI 1.0時代“算力軍備競賽”的最大贏家,現在主動喊出“推理側”和“Physical AI”的轉向,其實傳遞了一個非常直白的信號:過去靠堆卡訓練大模型的“大力出奇跡”時代過去了,以後AI競爭會圍繞應用場景落地的“應用為王”來角逐。
換句話說,Physical AI是 Generative AI的下半程。
因為LLM已經讀完了人類幾十年在互聯網上沉澱的所有數據,但它依然不懂如何像人一樣拧開一個瓶蓋。Physical AI就是要解決AI智力之外的“知行合一”問題。
因為,物理AI不可能依賴遠端雲伺服器的“長反射弧”,邏輯很簡單,讓ChatGPT生成文字慢一秒你只是會覺得卡,可一個雙足機器人如果因為網路延遲慢了一秒,它可能就會從樓梯上摔下去。
不過,Physical AI看似是生成式AI的延續,實則面臨著完全不同的三大新課題:
1)空間智能:讓AI擁有三維世界的理解力。
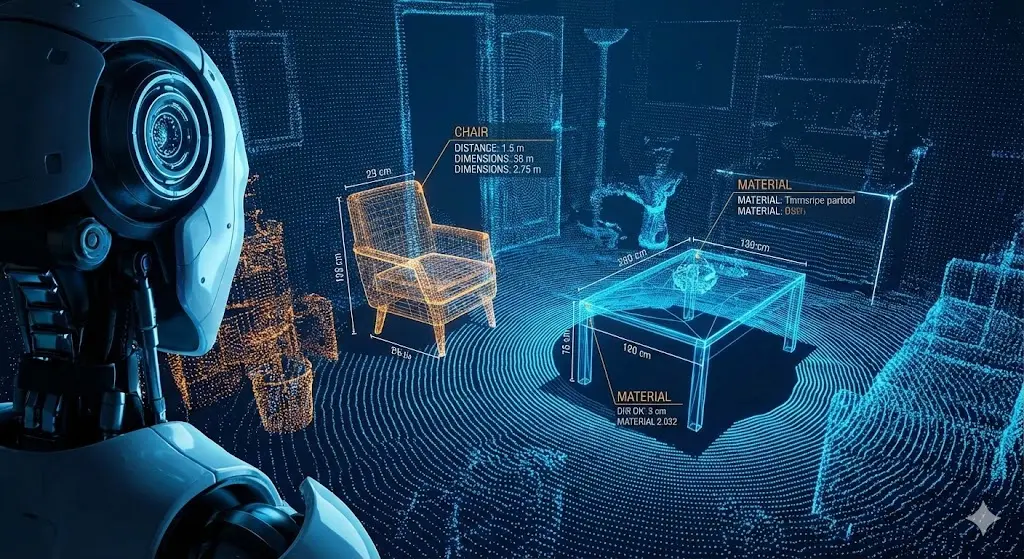
李飛飛教授曾提出,空間智能是AI進化的下一個北極星。機器人要動,首先得“看懂”環境。這不僅僅是識別出“這是一把椅子”,而是要理解“這把椅子在三維空間的位置、結構以及我該用多大的力氣去搬動它”。
這需要的是海量的、實時的、覆蓋室內室外每一個角落的3D環境數據;
2)虛擬訓練場:讓AI在模擬世界裡試錯訓練。

黃仁勳提到的Omniverse其實就是一種“虛擬訓練場”。機器人在進入真實物理世界前,需要在虛擬環境裡訓練“摔倒一萬次”才能學會走路,這個過程叫Sim-to-Real即從模擬到現實。如果直接讓機器人在現實中試錯,硬體損耗成本將會是可怕的天文數字。
這個過程,對物理引擎模擬和渲染算力的吞吐量要求,是指數級的;
3)電子皮膚:“觸覺數據”一個待挖的數據金礦。

Physical AI要想具備“手感”,需要電子皮膚來感知溫度、壓力、質感。這些“觸覺數據”是以前從未被規模化採集過的全新資產。這可能需要大規模的傳感器採集,CES上Ensuring公司展示的“量產皮膚”一只密密麻麻手上就集成了1,956個傳感器,所以才能有機器人撥雞蛋的神奇效果。
這些“觸覺數據”是以前從未被規模化採集過的全新資產。
看完這些,你一定會覺得,Physical AI論調的出現給了很多可穿戴設備以及人形機器人等硬體設備很大的冒頭機會,要知道,這些在幾年前都基本被詬病為“大號玩具”的存在。
其實我想說,在Physical AI的全新版圖裡,Crypto賽道其實也有絕佳的生態補位機會。我隨便舉幾個例子:
1、AI巨頭們可以派街景車掃描世界的每一個主街道,但是卻沒法採集到街頭、小區內部、地下室的犄角旮旯,而利用DePIN網路設備提供的Token激勵,動員全球用戶用隨身設備去補齊這些數據,就有可能完成補位;
2、前面說了,機器人不能依賴雲端算力,但要短期大規模的利用邊緣計算和分散式渲染能力,尤其是完成很多模擬到現實的數據。利用分散式算力網路,把閒置的消費級硬體集結起來,進行分發和調度,不就可以派上用場了;
3、“觸覺數據”,除了規模化的傳感器應用外,一聽名字就知道會極其隱私,如何調度大眾把這些涉及隱私的數據共享給AI巨頭呢,可行的路徑就是讓貢獻數據的人能得到數據確權和分紅。
總結一下:
Physical AI這是老黃喊出的web2 AI賽道的下半場,對於web3 AI +Crypto賽道諸如DePIN、DeAI、DeData等板塊又何嘗不是?你覺得呢?
免責聲明:本頁面資訊可能來自第三方,不代表 Gate 的觀點或意見。頁面顯示的內容僅供參考,不構成任何財務、投資或法律建議。Gate 對資訊的準確性、完整性不作保證,對因使用本資訊而產生的任何損失不承擔責任。虛擬資產投資屬高風險行為,價格波動劇烈,您可能損失全部投資本金。請充分了解相關風險,並根據自身財務狀況和風險承受能力謹慎決策。具體內容詳見聲明。
留言
0/400
暫無留言