DeepSeek выпустила превью-версии DeepSeek-V4-Pro и DeepSeek-V4-Flash 24 апреля 2026 года — обе это модели с открытыми весами с контекстным окном в один миллион токенов и ценами значительно ниже сопоставимых западных альтернатив. Модель V4-Pro стоит $1.74 за миллион входных токенов и $3.48 за миллион выходных токенов — примерно 1/20 от цены Claude Opus 4.7 и на 98% меньше, чем GPT-5.5 Pro, согласно официальным спецификациям компании.
Архитектура модели и масштаб
DeepSeek-V4-Pro имеет 1.6 трлн общих параметров, что делает его крупнейшей открытой LLM на рынке на сегодняшний день. Однако в каждом проходе вывода активируются только 49 млрд параметров, используя то, что DeepSeek называет подходом Mixture-of-Experts, усовершенствованным начиная с V3. Эта конструкция позволяет всей модели оставаться бездействующей, пока активируются лишь релевантные фрагменты для любого заданного запроса, снижая вычислительные затраты при сохранении объёма знаний.
DeepSeek-V4-Flash работает на меньшем масштабе: 284 млрд общих параметров и 13 млрд активных параметров. Согласно бенчмаркам DeepSeek, он «достигает сопоставимой с версией Pro производительности рассуждений, когда получает больший бюджет на размышления».
Обе модели поддерживают один миллион токенов контекста как стандартную функцию — примерно 750,000 слов, или примерно вся трилогия «Властелин колец» плюс дополнительный текст.
Технические инновации: механизмы внимания в масштабе
DeepSeek решил проблему вычислительного масштабирования, присущую обработке длинного контекста, изобретя два новых типа внимания, как подробно описано в технической статье компании, доступной на GitHub.
Стандартные механизмы внимания в ИИ сталкиваются с жесткой проблемой масштабирования: каждый раз, когда длина контекста удваивается, вычислительная стоимость примерно четверуется. Решение DeepSeek включает два взаимодополняющих подхода:
Compressed Sparse Attention работает в два шага. Сначала она сжимает группы токенов — например, каждый 4 токена — в одну запись. Затем, вместо того чтобы уделять внимание всем сжатым записям, она использует «Lightning Indexer», чтобы выбрать только самые релевантные результаты для любого заданного запроса. Это сужает область внимания модели с миллиона токенов до гораздо меньшего набора важных чанков.
Heavily Compressed Attention использует более агрессивный подход: она сворачивает каждые 128 токенов в одну запись без разреженного выбора. Хотя это теряет детальную информацию, это обеспечивает чрезвычайно дешевый глобальный обзор. Оба типа внимания работают в чередующихся слоях, позволяя модели сохранять и детальность, и обзор.
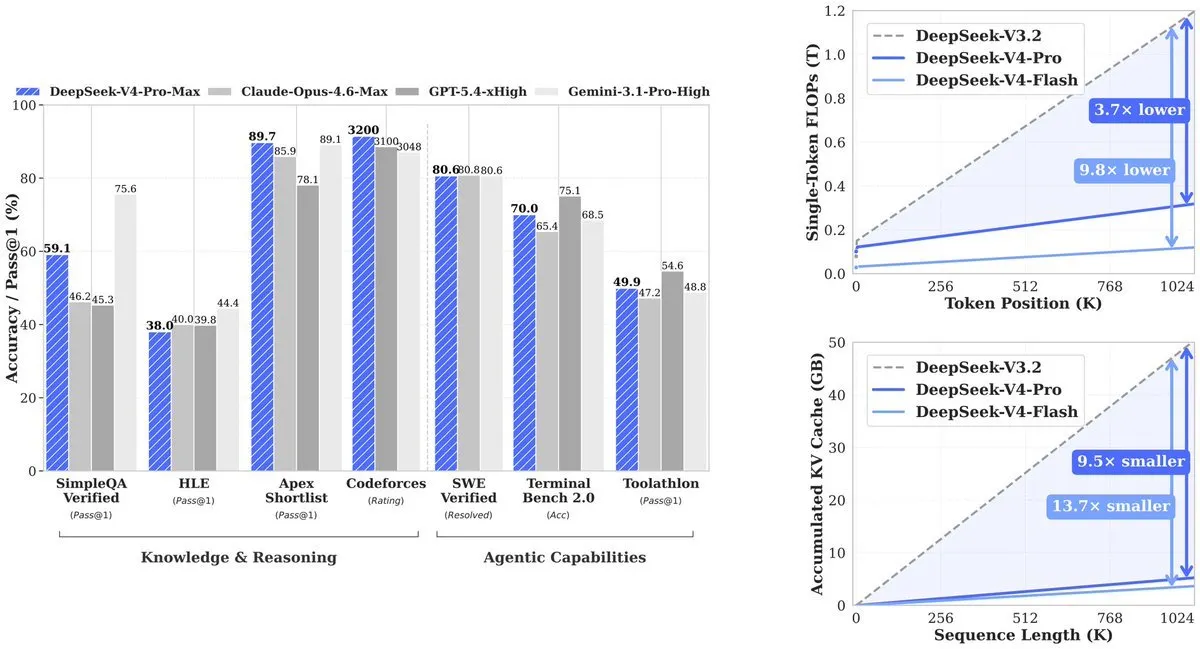
Итог: V4-Pro использует 27% вычислений, которые требовались предшественнику (V3.2). KV cache — память, необходимая для отслеживания контекста — падает до 10% от V3.2. V4-Flash продвигает эффективность дальше: 10% вычислений и 7% памяти по сравнению с V3.2.
Производительность в бенчмарках и конкурентные позиции
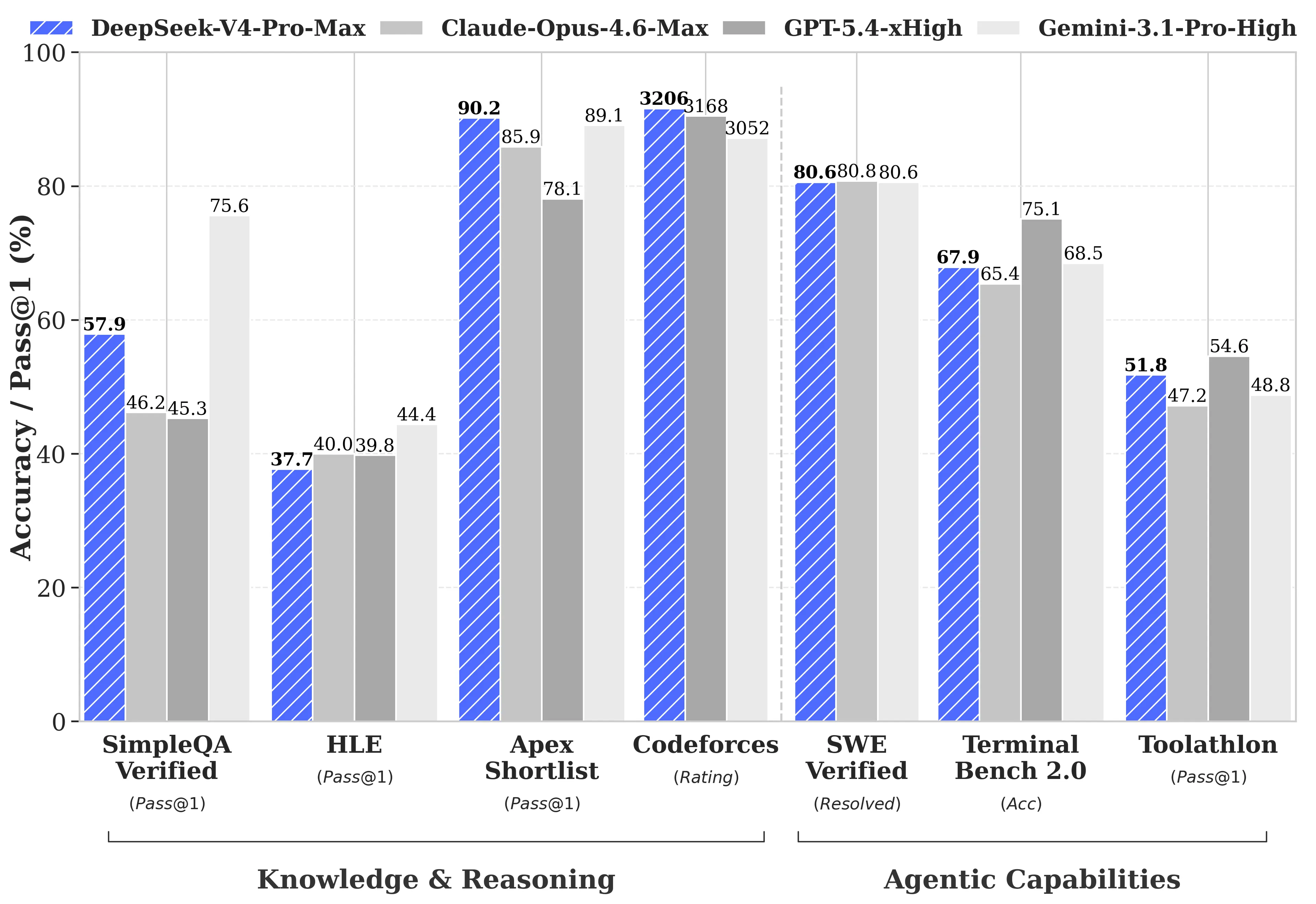
DeepSeek опубликовала исчерпывающие сравнения бенчмарков с GPT-5.4 и Gemini-3.1-Pro, включая области, где V4-Pro уступает конкурентам. В задачах на рассуждения, по данным технического отчета DeepSeek, отставание рассуждений V4-Pro от GPT-5.4 и Gemini-3.1-Pro составляет примерно три–шесть месяцев.
Где V4-Pro лидирует:
- Codeforces (соревновательное программирование): V4-Pro набрала 3,206, что соответствует примерно 23-му месту среди реальных участников человеческих контестов
- Apex Shortlist (отобранные задачи по математике и STEM): 90.2% проходного результата против 85.9% у Opus 4.6 и 78.1% у GPT-5.4
- SWE-Verified (разрешение GitHub issue): 80.6%, вровень с Claude Opus 4.6
Где V4-Pro уступает:
- MMLU-Pro (многозадачность): Gemini-3.1-Pro на 91.0% против 87.5% у V4-Pro
- GPQA Diamond (экспертные знания): Gemini на 94.3 против 90.1 у V4-Pro
- Последний экзамен человечества (уровня выпускника): Gemini-3.1-Pro на 44.4% против 37.7% у V4-Pro
В задачах с длинным контекстом V4-Pro лидирует среди моделей с открытыми весами и обгоняет Gemini-3.1-Pro на CorpusQA (имитируя реальный анализ документов на одном миллион токенов), но уступает Claude Opus 4.6 на MRCR — метрике, измеряющей извлечение конкретной информации, глубоко спрятанной в длинном тексте.
Агентные и кодинговые возможности
V4-Pro может работать в Claude Code, OpenCode и других инструментах для ИИ-программирования. Согласно внутреннему опросу DeepSeek среди 85 разработчиков, которые использовали V4-Pro как основного агента для кодинга, 52% сказали, что он готов стать их моделью по умолчанию, 39% склонялись к «да», и менее 9% ответили «нет». Внутреннее тестирование DeepSeek показало, что V4-Pro превосходит Claude Sonnet и приближается к Claude Opus 4.5 в задачах агентного кодинга.
Artificial Analysis поставила V4-Pro на первое место среди всех моделей с открытыми весами на GDPval-AA — бенчмарке, тестирующем экономически ценную работу со знаниями в областях финансов, права и исследований. V4-Pro-Max набрала 1,554 Elo, опередив GLM-5.1 (1,535) и MiniMax M2.7 (1,514). Claude Opus 4.6 набирает 1,619 на том же бенчмарке.
V4 вводит «переплетенное мышление», которое сохраняет полную цепочку рассуждений во всех вызовах инструментов. В предыдущих моделях, когда агент выполнял несколько вызовов инструментов — например, поиск в веб, запуск кода, затем снова поиск — контекст рассуждений модели сбрасывался между раундами. V4 сохраняет непрерывность рассуждений между шагами, предотвращая потерю контекста в сложных автоматизированных рабочих процессах.
Конкурентный ландшафт и контекст ценообразования
Релиз V4 выходит на фоне заметной активности в сфере ИИ. Anthropic выпустила Claude Opus 4.7 16 апреля 2026 года. OpenAI выпустила GPT-5.5 23 апреля 2026 года, а GPT-5.5 Pro стоит $30 за миллион входных токенов и $180 за миллион выходных токенов. GPT-5.5 обходит V4-Pro на Terminal Bench 2.0 (82.7% против 70.0%) — этот тест оценивает сложные сценарии рабочих процессов агент-ориентированного командного интерфейса.
Xiaomi выпустила MiMo V2.5 Pro 22 апреля 2026 года, предложив полный мультимодальный функционал (изображение, аудио, видео) с $1 за $3 вход и (за )выход по миллиону токенов. Tencent выпустила Hy3 в тот же день, что и GPT-5.5.
Для перспектив по цене: CEO Cline Сауд Ризван отметил, что если бы Uber использовал DeepSeek вместо Claude, то его бюджет на ИИ в 2026 году — как сообщается, достаточный для четырех месяцев использования — растянулся бы на семь лет.
![Pricing comparison and Uber budget analysis]https://img-cdn.gateio.im/social/moments-0ee5a4bf95-cbc5686e31-8b7abd-badf29
Развертывание и доступность
Обе модели V4-Pro и V4-Flash имеют лицензию MIT и доступны на Hugging Face. Сейчас модели текстовые; DeepSeek заявила, что работает над мультимодальными возможностями. Обе модели можно запускать бесплатно на локальном оборудовании или адаптировать под потребности компании.
Существующие endpoints deepseek-chat и deepseek-reasoner от DeepSeek уже маршрутизируют запросы к V4-Flash в режимах non-thinking и thinking соответственно. Старые endpoints deepseek-chat и deepseek-reasoner будут сняты с эксплуатации 24 июля 2026 года.
DeepSeek частично обучала V4 на чипах Huawei Ascend, обходя ограничения экспорта США. Компания заявила, что после запуска 950 новых супернодов позже в 2026 году цена Pro — и так уже низкая — снизится еще сильнее.
Практические последствия
Для предприятий структура ценообразования может изменить расчеты «стоимость-выгода». Модель, лидирующая среди открытых бенчмарков по цене $1.74 за миллион входных токенов, делает крупномасштабную обработку документов, юридическую проверку и конвейеры генерации кода существенно дешевле по сравнению с шестью месяцами назад. Контекст на миллион токенов позволяет обрабатывать целые кодовые базы или регуляторные подачи одним запросом вместо нарезки на фрагменты через несколько вызовов.
Для разработчиков и независимых энтузиастов V4-Flash — основной вариант. При цене $0.14 за вход и $0.28 за выход на миллион токенов, он дешевле моделей, которые год назад считались «бюджетными», при этом обрабатывает большинство задач, с которыми справляется версия Pro.
Отказ от ответственности: Информация на этой странице может поступать от третьих лиц и не отражает взгляды или мнения Gate. Содержание, представленное на этой странице, предназначено исключительно для справки и не является финансовой, инвестиционной или юридической консультацией. Gate не гарантирует точность или полноту информации и не несет ответственности за любые убытки, возникшие от использования этой информации. Инвестиции в виртуальные активы несут высокие риски и подвержены значительной ценовой волатильности. Вы можете потерять весь инвестированный капитал. Пожалуйста, полностью понимайте соответствующие риски и принимайте разумные решения, исходя из собственного финансового положения и толерантности к риску. Для получения подробностей, пожалуйста, обратитесь к
Отказу от ответственности.