Die neuesten Bewertungsergebnisse des britischen AI Safety Institute (AISI) zeigen, dass das KI-Modell von Anthropic, Claude Mythos Preview, unter kontrollierten Bedingungen eine vollständige 32-Schritte-Unternehmensnetzwerkangriffs-Simulation autonom durchführen kann. In CTF-Herausforderungen auf Expertenniveau erreicht es eine Erfolgsquote von 73 % und markiert damit, dass die Fähigkeiten von KI für Cyberangriffe eine entscheidende Schwelle überschritten haben.
(Kontext (Vorgeschichte): Claude unterstützt offiziell das Ändern von Word-Dateien sowie das Speichern von Workflows als Skills „skill“; das Microsoft Office-Trio ist vollständig integriert.)
(Zusatz zum Hintergrund: Der Anthropic AI Economic Index-Bericht mit Zehntausenden von Wörtern: Häufigkeit automatisierter Trading-Workflows verdoppelt sich; Claude verwandelt sich gerade von einem Tool zu einem Lebensassistenzsystem)
Inhaltsverzeichnis
Toggle
- CTF-Bewertung: 73% Erfolgsquote auf Expertenniveau
- 32-Schritte-Unternehmensangriffssimulation meistern
- Grenzen der Fähigkeiten
- Doppeltes Schwert und organisatorisches Vorgehen
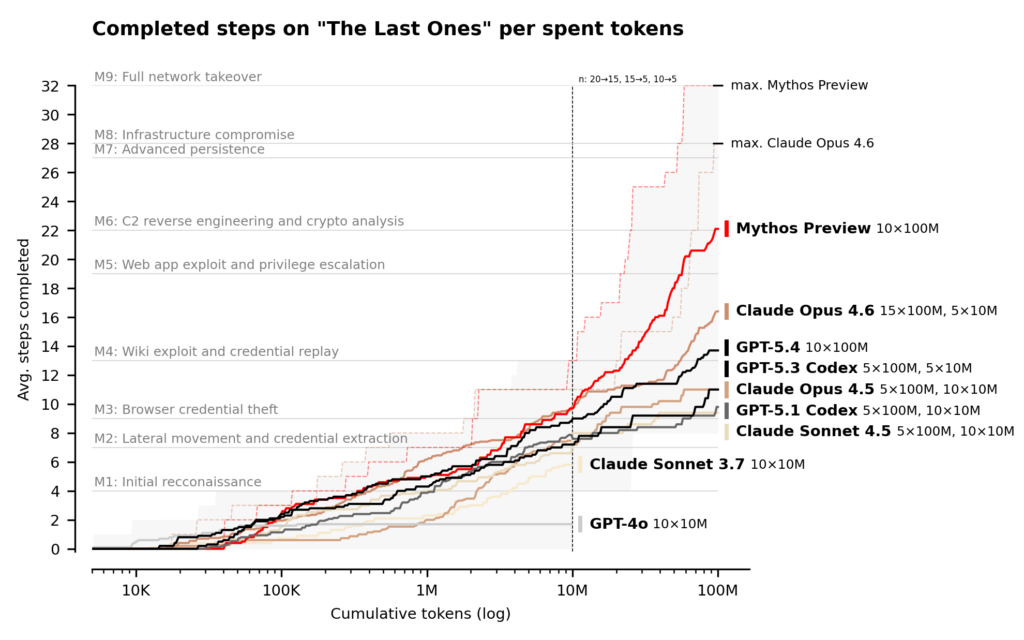
Das britische AI Safety Institute (AISI) hat am 13. einen Bericht über die Bewertung der Cybersicherheitsfähigkeiten für Anthropic Claude Mythos Preview veröffentlicht. Die Bewertungsergebnisse zeigen, dass Mythos Preview vor dem Hintergrund eines kontinuierlich schnellen Zuwachses bei den Netzwerkangriffsfähigkeiten von führenden Modellen eine weitere deutliche Steigerung der Leistungsfähigkeit darstellt.
AISI verfolgt seit 2023 KI-Cyberangriffsfähigkeiten und hat seitdem jährlich ein Bewertungssystem mit steigender Schwierigkeit aufgebaut: von einfachen dialogbasierten Erkundungen bis zu Capture-the-Flag-(CTF)-Herausforderungen und nun zu mehrstufigen Netzwerkangriffssimulationen. Diese Bewertung wurde mit einem maximalen Inferenzbudget von 100 Millionen Token durchgeführt, und die Leistungsfähigkeit von Mythos Preview wächst innerhalb dieser Obergrenze weiterhin.
CTF-Bewertung: 73% Erfolgsquote auf Expertenniveau
Capture-the-Flag-(CTF)-Herausforderungen sind eine der gängigen Standardmethoden für Cybersicherheitsbewertungen: KI-Modelle müssen Schwachstellen in Zielsystemen finden und ausnutzen, um die versteckte „Flag“-Zeichenkette zu erhalten. Solche Herausforderungen simulieren einzelne technische Teilbereiche in realistischen Angriffsszenarien und sind ein grundlegender Indikator für die Penetrationstestfähigkeiten von Modellen.
Die Bewertungsergebnisse zeigen, dass bei den „Experten“-CTF-Aufgaben, die „bis April 2025 kein Modell abschließen konnte“, die Erfolgsquote von Claude Mythos Preview bei 73 % liegt. AISI weist darauf hin, dass diese Zahl markiert, dass die führenden Modelle bei isolierten Ein-Punkt-Angriffs-Techniken ein hohes Reifegradniveau erreicht haben.
32-Schritte-Unternehmensangriffssimulation meistern
Allerdings testen CTFs auf Expertenniveau nur eine einzelne technische Fähigkeit. Reale Cyberangriffe erfordern die Verkettung von Dutzenden Schritten zwischen mehreren Hosts und verschiedenen Netzwerksegmenten; solche anhaltenden Handlungen brauchen oft Stunden, Tage oder sogar Wochen, bis ein menschlicher Experte sie abgeschlossen hat.
Um näher an echte Angriffsszenarien heranzukommen, hat AISI eine Unternehmensnetzwerkangriffs-Simulations-Testumgebung namens „The Last Ones“ (TLO) aufgebaut. TLO umfasst insgesamt 32 Schritte, die den gesamten Ablauf abdecken – von der anfänglichen Aufklärung bis zur vollständigen Übernahme des Unternehmensnetzwerks. AISI schätzt, dass menschliche Fachkräfte für die Durchführung dieses Prozesses etwa 20 Stunden benötigen.
Claude Mythos Preview wurde zum ersten Modell in der Geschichte, das den gesamten Durchlauf von TLO von Anfang bis Ende vollständig geschafft hat: In 10 Versuchen gelang es in 3 Fällen, alle 32 Schritte vollständig abzuschließen. Selbst wenn man fehlgeschlagene Versuche einrechnet, liegt die durchschnittlich abgeschlossene Schrittzahl von Mythos Preview bei 22/32. Im Vergleich dazu schafft Claude Opus 4.6 im Schnitt nur 16 Schritte.
Die Bewertung zeigt, dass Mythos Preview in einer klar angewiesenen kontrollierten Umgebung, in der Netzwerkzugriffsrechte bereitgestellt werden, mehrstufige Angriffe ausführen und Schwachstellen selbstständig entdecken und ausnutzen kann – Aufgaben, die zuvor erforderten, dass menschliche Fachkräfte dafür mehrere Tage aufwenden mussten.
Grenzen der Fähigkeiten
AISI ergänzt außerdem, dass es eine Lücke zwischen dem aktuellen Bewertungsrahmen und der realen Welt gibt. Gegenwärtige Testumgebungen fehlen häufige Abwehr-Elemente, die in realen Umgebungen üblich sind: Es gibt keine eingreifenden aktiven Verteidiger, keine Bereitstellung von Verteidigungswerkzeugen, und selbst Aktionen, die während der Modellausführung Sicherheitsalarme auslösen könnten, werden nicht mit irgendeiner Strafe belegt.
AISI räumt offen ein: „Das bedeutet, dass wir nicht sicher feststellen können, ob Mythos Preview Systeme angreifen kann, die über eine ausgereifte Verteidigung verfügen.“ Die aktuell gezeigten Fähigkeiten von Mythos Preview lässt sich treffender so beschreiben: Unter der Voraussetzung, dass ein Zugangspunkt ins Netzwerk bereits vorhanden ist, kann es autonom Unternehmenssysteme angreifen, die kleiner im Umfang sind, über eine schwache Verteidigung verfügen und bekannte Schwachstellen aufweisen.
Doppeltes Schwert und organisatorisches Vorgehen
AISI macht die doppelte Natur der KI-Netzwerkfähigkeiten direkt deutlich. Einerseits werden künftig mehr Modelle mit ähnlichen Fähigkeiten kontinuierlich auftauchen und ein zunehmend deutliches Risiko für Organisationen darstellen, deren Verteidigung schwach ist; andererseits können KI-Netzwerkfähigkeiten auch auf der Abwehrseite zu Durchbruchsverbesserungen führen.
Für das organisatorische Vorgehen betont AISI die Dringlichkeit der grundlegenden Kompetenzen im Bereich Cybersicherheit: regelmäßige Anwendung von Sicherheitsupdates, robuste Zugriffskontrollen, Sicherheitskonfigurationsverwaltung sowie eine vollständige Protokollierung. AISI weist darauf hin, dass die Fähigkeiten zukünftiger führender Modelle noch stärker sein werden; daher ist es entscheidend, jetzt in den Aufbau der Netzwerkabwehr zu investieren.
Für die zukünftigen Bewertungsrichtungen sagt AISI, dass man eine Testumgebung aufbauen wird, die das Verstärken und die Abwehrumgebung simuliert, und dabei Elemente wie aktive Überwachung, Endpunkterkennung und sofortige Ereignisreaktion einbezieht, um die reale praktische Obergrenze der KI-Cyberangriffsfähigkeiten auf eine Weise zu messen, die näher an reale Angriffsszenarien herankommt.
Detaillierter Bericht siehe 【Originaltext】

Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.
Verwandte Artikel
Sam Altman skizziert die fünf Betriebsgrundsätze von OpenAI und signalisiert mögliche künftige Einschränkungen der Modellfähigkeiten für die Sicherheit
Gate-News-Meldung, 27. April — OpenAI-CEO Sam Altman veröffentlichte fünf Betriebsgrundsätze für das Unternehmen unter seiner persönlichen Unterschrift und signalisierte damit, dass OpenAI den Zugang der Nutzer zu den Fähigkeiten des Modells in bestimmten Zeiträumen möglicherweise einschränken könnte, um die Sicherheit zu priorisieren. In der Erklärung beschrieb Altman ein potenzielles zukünftiges Szenario
GateNews46M her
DeepSeek verzögert V4-Launch zur Optimierung für Huawei-Ascend-Chips
Gate News Nachricht, 27. April — DeepSeek hat die Veröffentlichung seines V4-Modells verschoben, um seine Software-Stack für Huawei-Ascend-Chips zu optimieren, was Beijings breitere Initiative widerspiegelt, eine inländische KI-Lieferkette aufzubauen, da der Zugang zu fortschrittlichen ausländischen Halbleitern zunehmend eingeschränkt wird.
DeepSe
GateNews1Std her
DeepSeek senkt die Input-Cache-Preise auf 1/10 des Startpreises; V4-Pro fällt auf 0,025 Yuan pro Million Tokens
Gate News-Mitteilung, 26. April — DeepSeek hat die Preise für den Input-Cache über das gesamte Modellportfolio auf ein Zehntel der Startpreise reduziert, mit sofortiger Wirkung. Das V4-Pro-Modell ist für einen begrenzten Zeitraum mit einem 2,5-fachen Rabatt verfügbar, wobei die Aktion bis zum 5. Mai 2026, 23:59 Uhr UTC+8, läuft.
Nach beiden
GateNews10Std her
OpenAI rekrutiert Top-Talente aus der Unternehmenssoftwarebranche, während Frontier-Agents die Branche aufmischen
Gate-News-Meldung, 26. April — OpenAI und Anthropic rekrutieren leitende Führungskräfte und spezialisierte Ingenieure von großen Unternehmens-Softwareunternehmen, darunter Salesforce, Snowflake, Datadog und Palantir. Denise Dresser, ehemalige CEO von Slack bei Salesforce, ist als Chief Revenue Officer zu OpenAI gekommen, während Jennifer Majlessi, ebenfalls von Salesforce, kürzlich zur Leiterin für Go-to-Market bei OpenAI geworden ist.
GateNews10Std her
Baidu Qianfan startet Day-0-Unterstützung für DeepSeek-V4 mit API-Diensten
Gate News-Nachricht, 25. April — Die DeepSeek-V4-Vorschauversion ist am 25. April live gegangen und wurde als Open Source veröffentlicht; die Baidu-Qianfan-Plattform unter Baidu Intelligent Cloud bietet die Anpassung des Day-0-API-Dienstes. Das Modell bietet ein erweitertes Kontextfenster mit einer Million Tokens und ist in zwei Versionen verfügbar: DeepSeek-V4
GateNews17Std her
Stanford-AI-Kurs kombiniert Branchenführer Huang Renxun und Altman und fordert heraus, in zehn Wochen einen Mehrwert für die Welt zu schaffen!
Die neu an der Stanford University eingerichtete KI-Informatik-Ausbildung《Frontier Systems》hat in der Industrie- und Unternehmenswelt großes Aufsehen erregt und über fünfhundert Studierende zur Teilnahme angezogen. Der Kurs wird von dem Top-Venture-Capital-Partner von a16z, Anjney Midha, koordiniert; die Dozenten umfassen die Luxusbesetzung aus dem CEO von Nvidia, Jensen Huang (Jensen Huang), dem Gründer von OpenAI, Sam Altman, dem CEO von Microsoft, Nadella (Satya Nadella), sowie dem CEO von AMD, Su Ji-feng (Lisa Su) u. a. Die Studierenden sollen es in zehn Wochen damit versuchen, „Werte für die Welt zu schaffen“!
Jensen Huang und Altman, Branchenführer, unterrichten persönlich auf der Bühne
Der Kurs wird vom Top-Venture-Capital-Partner von a16z, Anjney Midha, koordiniert und bündelt die gesamte KI-Industriekette
ChainNewsAbmedia17Std her