DeepSeek veröffentlichte am 24. April 2026 Vorschauversionen von DeepSeek-V4-Pro und DeepSeek-V4-Flash, beides Open-Weight-Modelle mit Ein-Million-Token-Context-Fenstern und Preisen, die deutlich unter vergleichbaren westlichen Alternativen liegen. Das V4-Pro-Modell kostet $1.74 pro Million Input-Tokens und $3.48 pro Million Output-Tokens – ungefähr 1/20 des Preises von Claude Opus 4.7 und 98% weniger als GPT-5.5 Pro, laut den offiziellen Spezifikationen des Unternehmens.
Modellarchitektur und -umfang
DeepSeek-V4-Pro verfügt über 1,6 Billionen insgesamt Parameter und ist damit das größte Open-Source-Modell auf dem LLM-Markt bis dato. Allerdings werden nur 49 Milliarden Parameter pro Inferenz-Pass aktiviert, wobei das zum Einsatz kommt, was DeepSeek den Mixture-of-Experts-Ansatz nennt, der seit V3 verfeinert wurde. Dieses Design ermöglicht es, dass das vollständige Modell inaktiv bleibt, während nur die relevanten Teilbereiche für jede gegebene Anfrage aktiviert werden, wodurch die Rechenkosten gesenkt werden, bei gleichzeitiger Beibehaltung der Wissenskapazität.
DeepSeek-V4-Flash arbeitet in kleinerem Maßstab mit 284 Milliarden gesamten Parametern und 13 Milliarden aktiven Parametern. Laut DeepSeeks Benchmarks „erreicht es vergleichbare Reasoning-Leistung wie die Pro-Version, wenn es mit einem größeren Thinking-Budget ausgestattet wird.“
Beide Modelle unterstützen standardmäßig einen Kontext von einer Million Tokens – ungefähr 750.000 Wörter, oder ungefähr die gesamte „Lord of the Rings“-Trilogie plus zusätzlichen Text.
Technologische Innovation: Attention-Mechanismen im großen Maßstab
DeepSeek löste das dem Problem der rechnerischen Skalierung zugrunde liegende Problem, das bei der Verarbeitung von Long-Contexts entsteht, indem es zwei neue Attention-Typen erfand, wie im technischen Paper des Unternehmens beschrieben, das auf GitHub verfügbar ist.
Standardmäßige KI-Attention-Mechanismen stehen vor einem brutalen Skalierungsproblem: Jedes Mal, wenn sich die Kontextlänge verdoppelt, steigen die Rechenkosten grob um das Vierfache. DeepSeeks Lösung umfasst zwei komplementäre Ansätze:
Compressed Sparse Attention funktioniert in zwei Schritten. Zuerst komprimiert es Gruppen von Tokens – zum Beispiel jedes 4. Token – zu einem einzigen Eintrag. Dann nutzt es, statt allen komprimierten Einträgen Aufmerksamkeit zu schenken, einen „Lightning Indexer“, um nur die relevantesten Ergebnisse für eine gegebene Anfrage auszuwählen. Dadurch wird der Attention-Umfang des Modells von einer Million Tokens auf eine viel kleinere Menge wichtiger Chunks reduziert.
Heavily Compressed Attention geht aggressiver vor und kollabiert jeweils 128 Tokens zu einem einzigen Eintrag, ohne Sparse-Auswahl. Zwar geht dabei feingranulare Detailtreue verloren, dafür liefert es eine extrem günstige globale Übersicht. Die zwei Attention-Typen laufen in alternierenden Schichten, sodass das Modell sowohl Detail als auch Überblick beibehält.
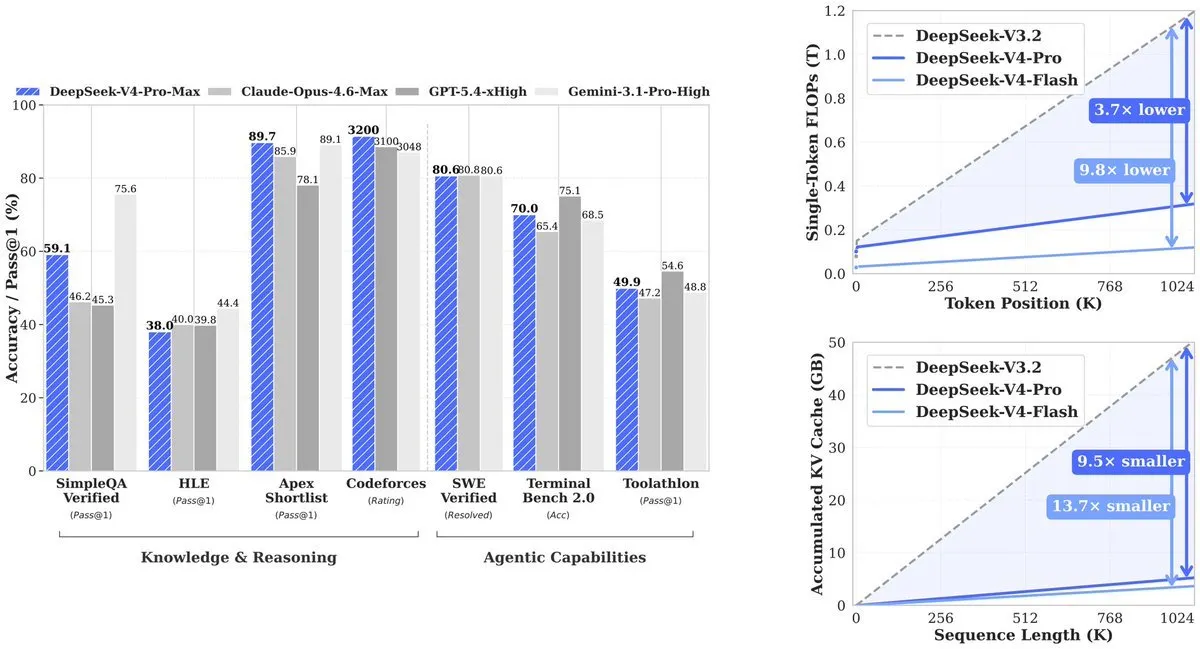
Das Ergebnis: V4-Pro nutzt 27% der Rechenleistung, die sein Vorgänger (V3.2) benötigte. KV-Cache – der Speicher, der benötigt wird, um den Kontext nachzuverfolgen – fällt auf 10% von V3.2. V4-Flash treibt die Effizienz noch weiter: 10% Rechenleistung und 7% Speicher im Vergleich zu V3.2.
Benchmark-Leistung und wettbewerbsfähige Position
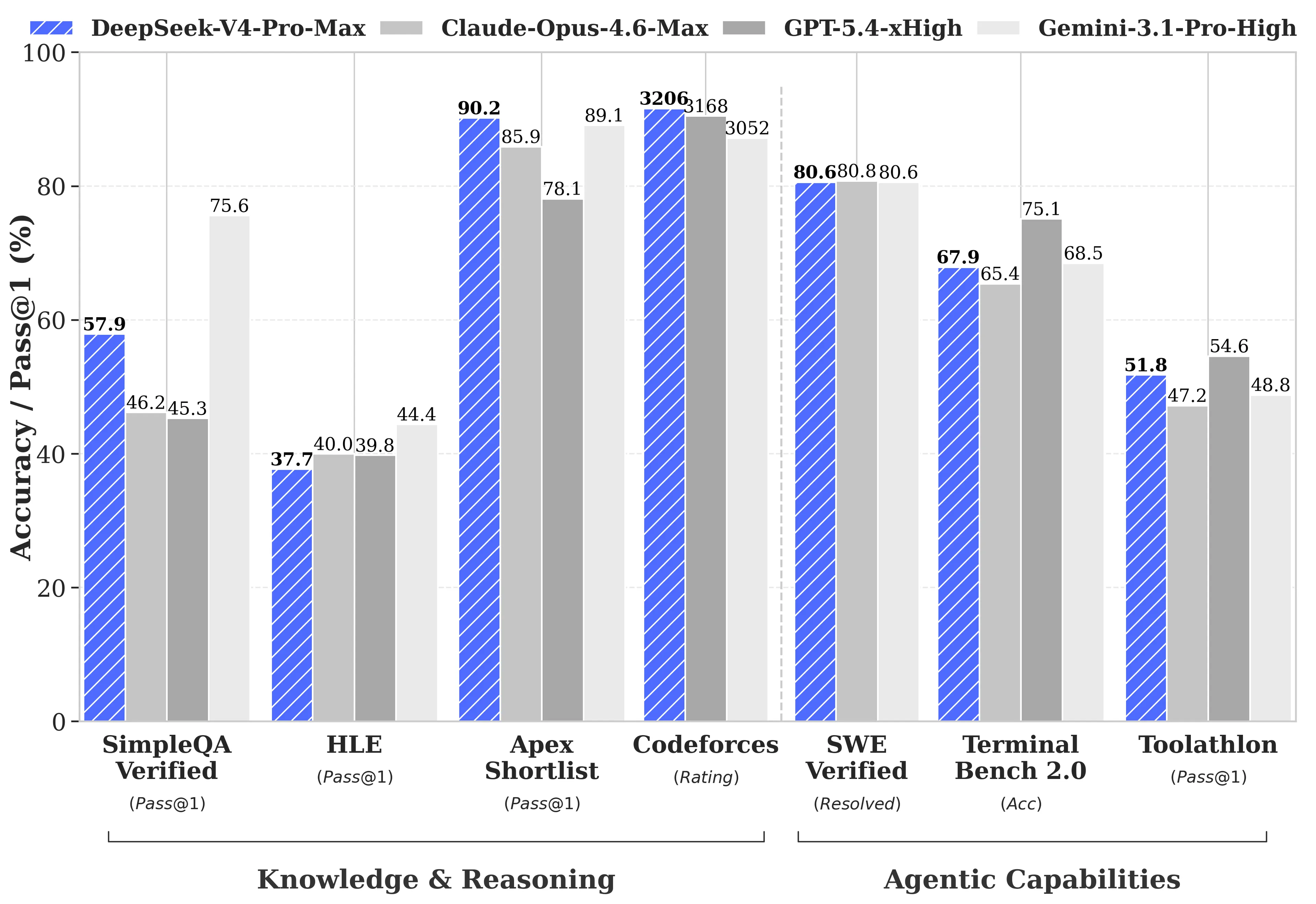
DeepSeek veröffentlichte umfassende Benchmark-Vergleiche gegen GPT-5.4 und Gemini-3.1-Pro, einschließlich Bereichen, in denen V4-Pro hinter den Wettbewerbern zurückliegt. Bei Reasoning-Aufgaben liegt das Reasoning von V4-Pro laut DeepSeeks technischem Bericht etwa drei bis sechs Monate hinter GPT-5.4 und Gemini-3.1-Pro zurück.
Wo V4-Pro führt:
- Codeforces (kompetitives Programmieren): V4-Pro erzielte 3.206 und lag damit etwa auf Platz 23 unter den tatsächlichen menschlichen Contest-Teilnehmern
- Apex Shortlist (kuratierte Mathe- und STEM-Probleme): 90,2% Pass-Rate gegenüber Opus 4.6 mit 85,9% und GPT-5.4 mit 78,1%
- SWE-Verified (GitHub-Issue-Auflösung): 80,6%, passend zu Claude Opus 4.6
Wo V4-Pro zurückliegt:
- MMLU-Pro (Multitasking): Gemini-3.1-Pro bei 91,0% vs. V4-Pro bei 87,5%
- GPQA Diamond (Expertenwissen): Gemini bei 94,3 vs. V4-Pro bei 90,1
- Humanity’s Last Exam (Abschlussniveau): Gemini-3.1-Pro bei 44,4% vs. V4-Pro bei 37,7%
Bei Long-Context-Aufgaben führt V4-Pro Open-Source-Modelle an und schlägt Gemini-3.1-Pro auf CorpusQA (Simulation einer realen Dokumentenanalyse bei einer Million Tokens), verliert jedoch gegen Claude Opus 4.6 auf MRCR, das die Abrufung spezifischer Informationen misst, die tief in langem Text verborgen sind.
Agentic- und Coding-Fähigkeiten
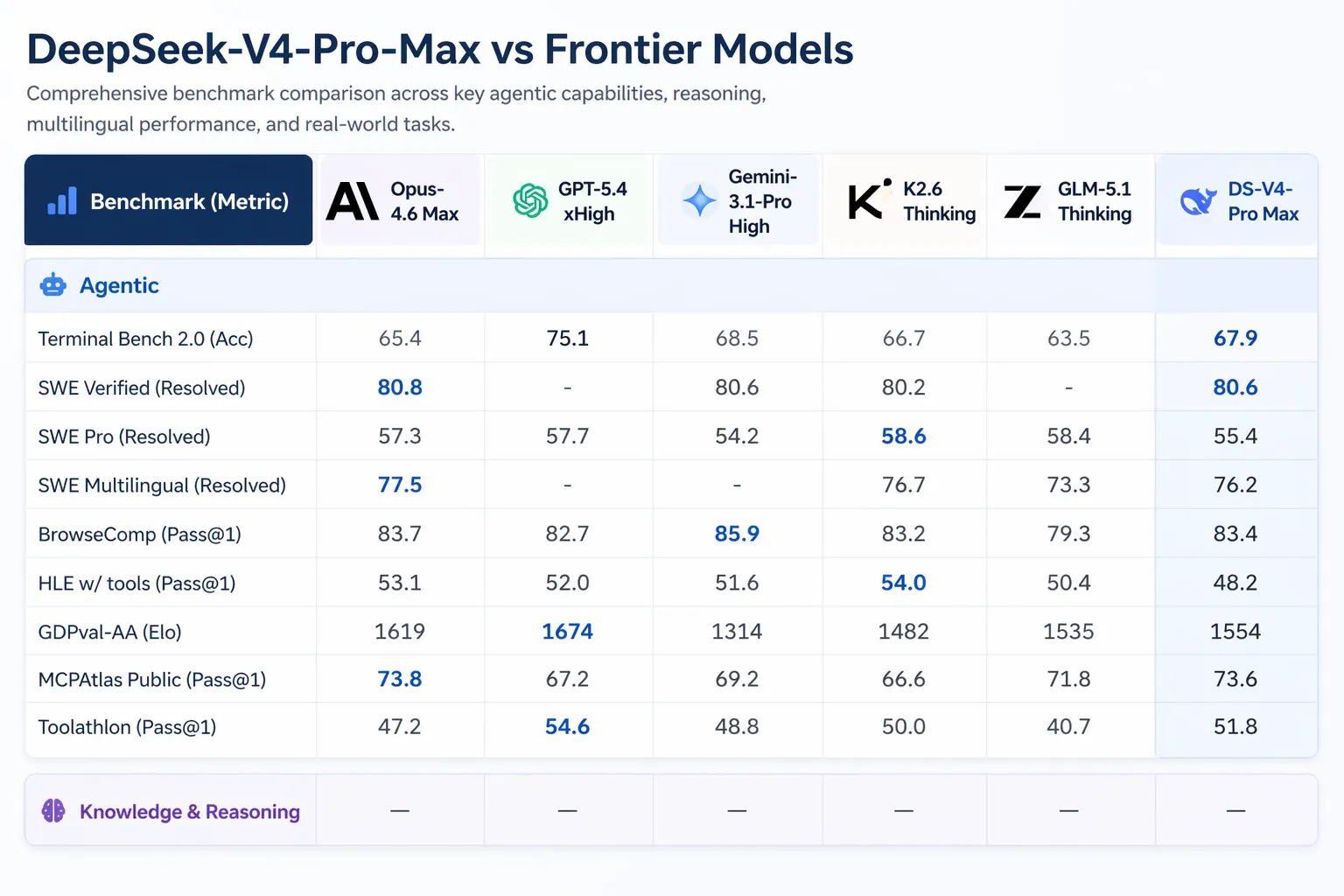
V4-Pro kann in Claude Code, OpenCode und anderen KI-Coding-Tools laufen. Laut DeepSeeks interner Umfrage unter 85 Entwicklern, die V4-Pro als ihren primären Coding-Agent genutzt haben, sagten 52%, es sei bereit, ihr Standardmodell zu sein, 39% tendierten zu „Ja“, und weniger als 9% sagten „Nein“. DeepSeeks interne Tests zeigten, dass V4-Pro bei agentischem Coding Vorkommen besser abschneidet als Claude Sonnet und an Claude Opus 4.5 heranreicht.
Artificial Analysis stufte V4-Pro als Erstes unter allen Open-Weight-Modellen auf GDPval-AA ein, einem Benchmark, der wirtschaftlich wertvolle Wissensarbeit über Finance-, Legal- und Research-Aufgaben testet. V4-Pro-Max erzielte 1.554 Elo, vor GLM-5.1 (1.535) und MiniMax’s M2.7 (1.514). Claude Opus 4.6 erzielt 1.619 auf demselben Benchmark.
V4 führt „interleaved thinking“ ein, das die vollständige Kette des Denkens über Tool-Calls hinweg beibehält. In früheren Modellen wurde, wenn ein Agent mehrere Tool-Calls machte – wie das Durchsuchen des Webs, das Ausführen von Code und dann das erneute Durchsuchen –, der Reasoning-Kontext des Modells zwischen den Runden geleert. V4 hält die Reasoning-Kontinuität über Schritte hinweg aufrecht und verhindert Kontextverlust bei komplexen automatisierten Workflows.
Wettbewerbslage und Preiskontext
Das V4-Release kommt inmitten bedeutender Aktivität im KI-Bereich. Anthropic lieferte Claude Opus 4.7 am 16. April 2026 aus. OpenAI brachte GPT-5.5 am 23. April 2026 auf den Markt, wobei GPT-5.5 Pro mit $30 pro Million Input-Tokens und $180 pro Million Output-Tokens bepreist wurde. GPT-5.5 schlägt V4-Pro auf Terminal Bench 2.0 (82,7% gegenüber 70,0%), das komplexe Command-Line-Agent-Workflow testet.
Xiaomi veröffentlichte MiMo V2.5 Pro am 22. April 2026 und bot vollständige Multimodal-Fähigkeiten (image, audio, video) zu $1 input und $3 output pro Million Tokens an. Tencent veröffentlichte Hy3 am selben Tag wie GPT-5.5.
Für eine Einordnung der Preisgestaltung: Cline-CEO Saoud Rizwan bemerkte, dass, wenn Uber statt Claude DeepSeek verwendet hätte, sein KI-Budget für 2026 – Berichten zufolge ausreichend für vier Monate Nutzung – sieben Jahre lang gereicht hätte.
Bereitstellung und Verfügbarkeit
Sowohl V4-Pro als auch V4-Flash sind unter der MIT-Lizenz verfügbar und auf Hugging Face erhältlich. Die Modelle sind derzeit nur textbasiert; DeepSeek erklärte, es arbeite an Multimodal-Fähigkeiten. Beide Modelle können kostenlos auf lokaler Hardware betrieben werden oder basierend auf den Anforderungen des Unternehmens angepasst werden.
DeepSeeks bestehende deepseek-chat- und deepseek-reasoner-Endpunkte routen bereits jeweils in Nicht-Thinking- und Thinking-Modi zu V4-Flash. Die alten deepseek-chat- und deepseek-reasoner-Endpunkte werden am 24. Juli 2026 auslaufen.
DeepSeek trainierte V4 teilweise auf Huawei-Ascend-Chips und umging damit US-Exportbeschränkungen. Das Unternehmen erklärte, dass, sobald später im Jahr 2026 950 neue Supernodes online gehen, der bereits niedrige Preis des Pro-Modells weiter sinken wird.
Praktische Implikationen
Für Unternehmen kann sich die Preisstruktur auf die Kosten-Nutzen-Berechnungen auswirken. Ein Modell, das Open-Source-Benchmarks mit $1.74 pro Million Input-Tokens anführt, macht große Dokumentverarbeitung, juristische Prüfung und Code-Generierungspipelines erheblich günstiger als noch vor sechs Monaten. Das Kontextfenster von einer Million Tokens ermöglicht, dass komplette Codebasen oder regulatorische Einreichungen in einer einzigen Anfrage verarbeitet werden, statt sie über mehrere Calls aufzuteilen.
Für Entwickler und Einzelbauer ist V4-Flash die wichtigste Überlegung. Für $0.14 Input und $0.28 Output pro Million Tokens ist es günstiger als Modelle, die vor einem Jahr als Budgetoptionen betrachtet wurden, und bewältigt dabei die meisten Aufgaben, die auch die Pro-Version übernimmt.