DeepSeek V4-Pro 以比 GPT-5.5 Pro 低 98% 的成本推出
DeepSeek 于 2026 年 4 月 24 日发布了 DeepSeek-V4-Pro 和 DeepSeek-V4-Flash 的预览版本,二者都是开放权重模型,拥有一百万 token 上下文窗口,并且定价显著低于可比的西方替代方案。根据该公司的官方规格说明,V4-Pro 模型的费用为:每百万输入 token $1.74,每百万输出 token $3.48——大约是 Claude Opus 4.7 价格的 1/20,并且比 GPT-5.5 Pro 低 98%。
模型架构与规模
DeepSeek-V4-Pro 具有 1.6 万亿个总参数,使其成为截至目前 LLM 市场中规模最大的开源模型。然而,每次推理仅激活 490 亿个参数,采用 DeepSeek 所称的 Mixture-of-Experts(混合专家)方案,并自 V3 以来进行了精炼。该设计使得完整模型保持休眠状态,仅在任何给定请求中激活相关切片,从而降低计算成本,同时维持知识容量。
DeepSeek-V4-Flash 以更小的规模运行,总参数 2840 亿,激活参数为 130 亿。根据 DeepSeek 的基准测试,其“在给定更大的思考预算时,在推理能力上能达到与 Pro 版本相当的水平”。
两种模型都支持一百万 token 的上下文,作为标准功能——大约 750,000 个词,或基本相当于“指环王”三部曲的全部内容,再加上额外文本。
技术创新:大规模注意力机制
DeepSeek 通过发明两种新的注意力类型来解决长上下文处理固有的计算扩展问题,具体细节见公司在 GitHub 上提供的技术论文。
标准的 AI 注意力机制面临严峻的扩展问题:每当上下文长度翻倍,计算成本大约就会增加 4 倍。DeepSeek 的解决方案包含两种互补的方法:
压缩稀疏注意力(Compressed Sparse Attention) 分两步进行。它首先压缩 token 分组——例如把每 4 个 token 压缩成一个条目。然后,不再对所有压缩条目进行关注,而是使用“Lightning Indexer(闪电索引器)”为任意给定查询只选择最相关的结果。这样可将模型的注意力范围从一百万 token 缩减到更小的、重要片段集合。
高强度压缩注意力(Heavily Compressed Attention) 采取更激进的策略:在不进行稀疏选择的情况下,把每 128 个 token 折叠成一个条目。尽管这会丢失细粒度细节,但它能提供极其廉价的全局视图。这两种注意力类型以交替层的方式运行,使得模型既能保持细节也能保留概览。
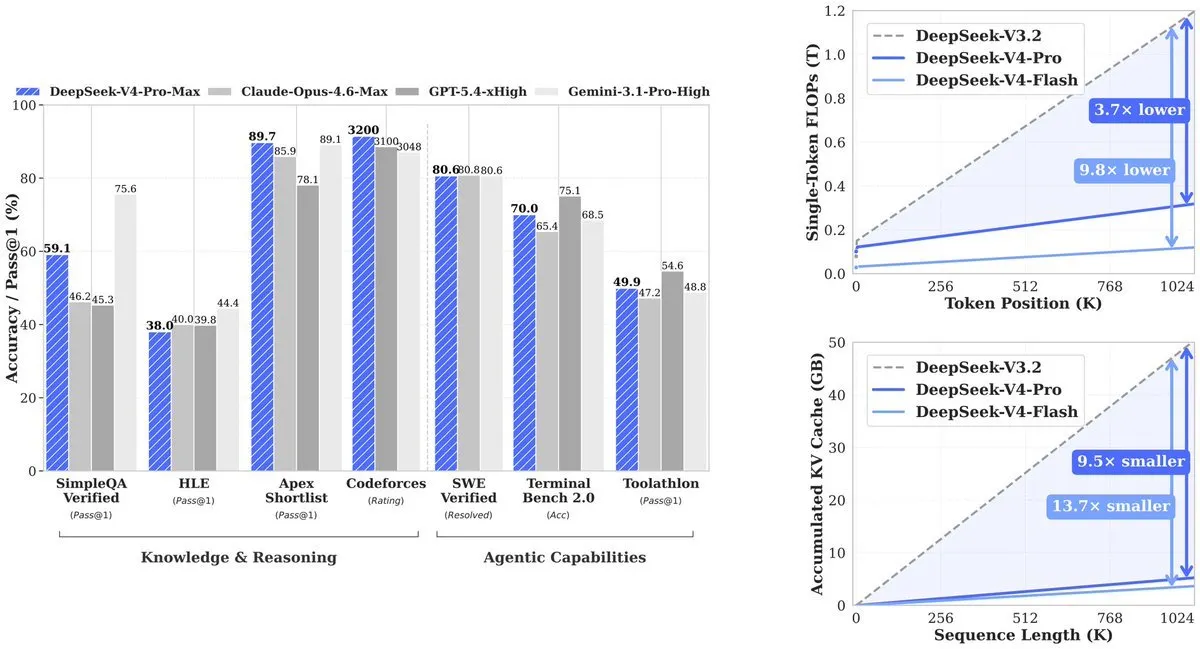
结果:V4-Pro 使用了其前代 (V3.2) 所需计算量的 27%。KV cache(追踪上下文所需的内存)降至 V3.2 的 10%。V4-Flash 进一步提升效率:相较于 V3.2,其计算为 10%,内存为 7%。
基准性能与竞争地位
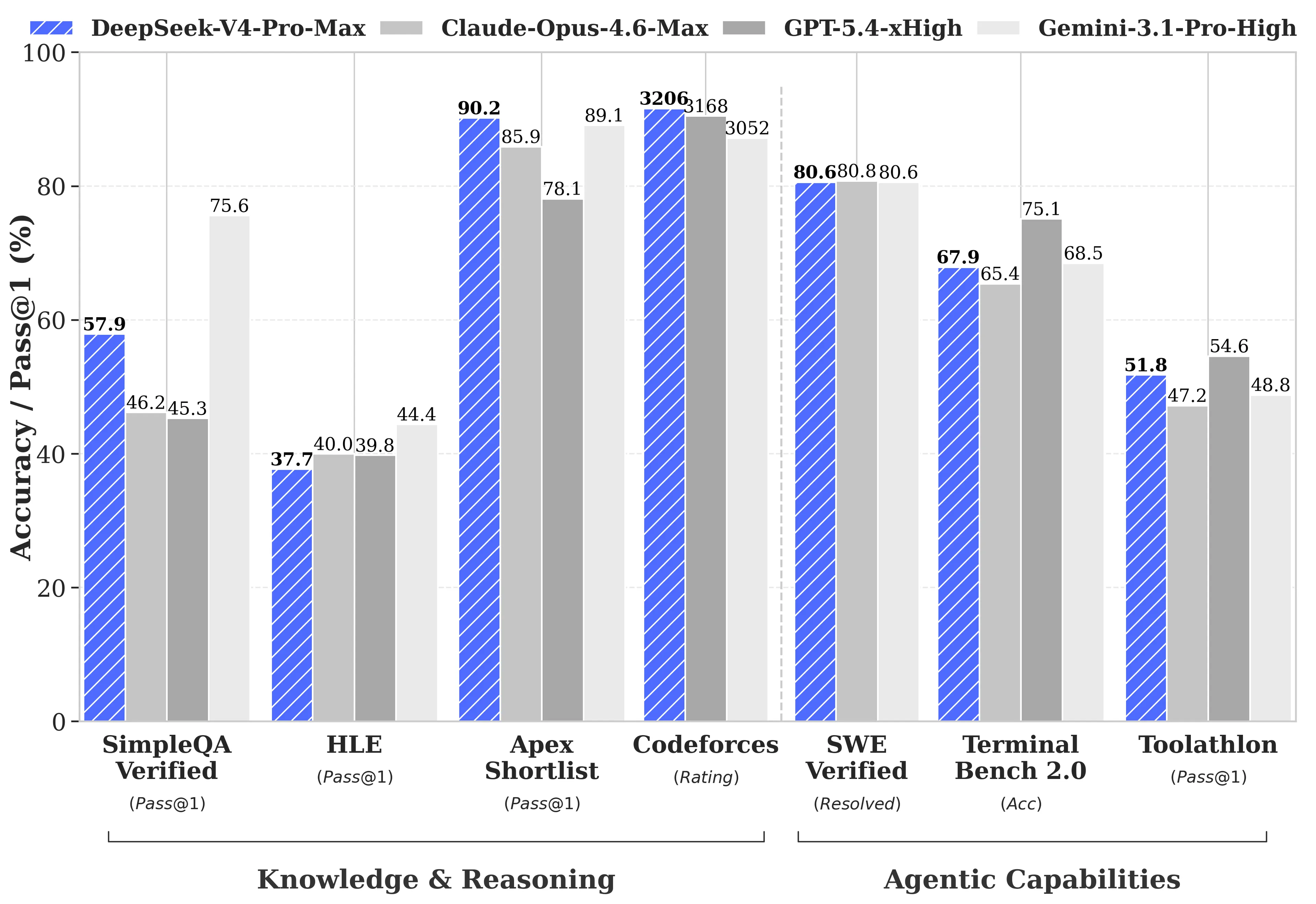
DeepSeek 发布了针对 GPT-5.4 和 Gemini-3.1-Pro 的全面基准对比,包括 V4-Pro 落后于竞争对手的领域。在推理任务上,根据 DeepSeek 的技术报告,V4-Pro 的推理能力大约比 GPT-5.4 和 Gemini-3.1-Pro 落后三到六个月。
V4-Pro 领先之处:
- Codeforces (竞赛型编程):V4-Pro 得分 3,206,在实际人类竞赛参与者中排名约第 23
- Apex Shortlist (精选数学与 STEM 题目):通过率 90.2%,而 Opus 4.6 为 85.9%,GPT-5.4 为 78.1%
- SWE-Verified (GitHub 问题解决):80.6%,与 Claude Opus 4.6 保持一致
V4-Pro 落后之处:
- MMLU-Pro (多任务):Gemini-3.1-Pro 为 91.0%,而 V4-Pro 为 87.5%
- GPQA Diamond (专家知识):Gemini 为 94.3,而 V4-Pro 为 90.1
- Humanity’s Last Exam (研究生级别):Gemini-3.1-Pro 为 44.4%,而 V4-Pro 为 37.7%
在长上下文任务上,V4-Pro 领先开源模型,并且在 CorpusQA (模拟真实文档分析(在一百万 tokens 的上下文中)) 上击败 Gemini-3.1-Pro,但在 MRCR 上落后于 Claude Opus 4.6;MRCR 用于衡量在长文本深处检索特定信息的能力。
Agentic 与编码能力
V4-Pro 可以在 Claude Code、OpenCode 以及其他 AI 编码工具中运行。根据 DeepSeek 对 85 名开发者的内部调查——这些开发者将 V4-Pro 作为主要编码代理——其中 52% 表示它已经准备好作为默认模型,39% 倾向于“是”,且少于 9% 的人表示“否”。DeepSeek 的内部测试显示,V4-Pro 在 agentic 编码任务上优于 Claude Sonnet,并且接近 Claude Opus 4.5。
Artificial Analysis 在 GDPval-AA 上将 V4-Pro 排在所有开放权重模型的第一位;GDPval-AA 是一个基准,用于测试在金融、法律与研究任务中具有经济价值的知识工作。V4-Pro-Max 的 Elo 分数为 1,554,领先于 GLM-5.1 (1,535) 以及 MiniMax 的 M2.7 (1,514)。同一基准下,Claude Opus 4.6 得分 1,619。
V4 引入了“交错式思考(interleaved thinking)”,能够在工具调用之间保留完整的思维链。在先前的模型中,当代理进行多次工具调用——例如先搜索网页,再运行代码,然后再次搜索——模型的推理上下文会在回合之间被清空。V4 则在步骤之间保持推理连续性,避免在复杂的自动化工作流中出现上下文丢失。
竞争格局与定价背景
V4 的发布正值 AI 领域出现大量重大进展。Anthropic 在 2026 年 4 月 16 日发布了 Claude Opus 4.7。OpenAI 的 GPT-5.5 于 2026 年 4 月 23 日上线;其中 GPT-5.5 Pro 的定价为:$30 每百万输入 token $$180 与 (每百万输出 token $)。根据用于测试复杂命令行代理工作流的 Terminal Bench 2.0,GPT-5.5 在该基准上以 (82.7%) 对比 70.0%$1 领先 V4-Pro。
小米在 2026 年 4 月 22 日发布了 MiMo V2.5 Pro,提供完整的多模态能力 $3 image, audio, video(,其定价为每百万 token 的 )input 和 output。腾讯在同一天(与 GPT-5.5 上线日期一致)发布了 Hy3。
从定价角度来看:Cline CEO Saoud Rizwan 指出,如果 Uber 使用的是 DeepSeek 而不是 Claude,那么其 2026 年的 AI 预算——据称足够支撑四个月的使用——将会持续七年。
![Pricing comparison and Uber budget analysis]https://img-cdn.gateio.im/social/moments-0ee5a4bf95-cbc5686e31-8b7abd-badf29
部署与可用性
V4-Pro 和 V4-Flash 都采用 MIT 许可,并可在 Hugging Face 上获得。就目前而言,这些模型仅支持文本;DeepSeek 表示它正在开发多模态能力。这两种模型都可以在本地硬件上免费运行,或者根据公司需求进行定制。
DeepSeek 现有的 deepseek-chat 和 deepseek-reasoner 端点已经分别在非思考模式和思考模式下将请求路由到 V4-Flash。旧的 deepseek-chat 与 deepseek-reasoner 端点将于 2026 年 7 月 24 日退役。
DeepSeek 在训练 V4 的过程中部分使用了华为 Ascend 芯片,从而绕开了美国的出口限制。该公司表示,一旦在 2026 年后续上线 950 个新的超节点,Pro 模型的已然很低的价格还会进一步下降。
实际影响
对于企业而言,定价结构可能会改变成本-收益的计算方式。以每百万输入 token $1.74 的价格在开源基准上领先的模型,使得大规模文档处理、法务审查和代码生成流水线比六个月前便宜得多。一百万 token 的上下文使得整个代码库或监管文件可以在一次请求中处理,而不是在多个调用中进行分块。
对于开发者与独立构建者而言,V4-Flash 是主要考虑对象。以每百万 token 的输入 $0.14、输出 $0.28 的价格,它比一年前被视为预算选项的模型更便宜,同时仍能处理 Pro 版本管理的大多数任务。