我的電腦可以本地運行 AI 模型嗎?CanIRun.ai 幫你快速分析
動區BlockTempo
AI 工具 CanIRun.ai 能透過瀏覽器自動偵測用戶硬體規格,替使用者估算能執行哪些 LLM 模型與推論速度,有興趣的用戶可以試試瞭解一下。
(前情提要:Clawdbot 封神,一個讓 Mac mini 賣斷貨的 7×24 小時 AI 管家)
(背景補充:別盲目跟風 OpenClaw,小龍蝦 AI 很強,但不一定適合你)
本文目錄
Toggle
- Canirun.ai 的小缺點
- 命令列替代方案 llmfit 登場
- 社群最想要的
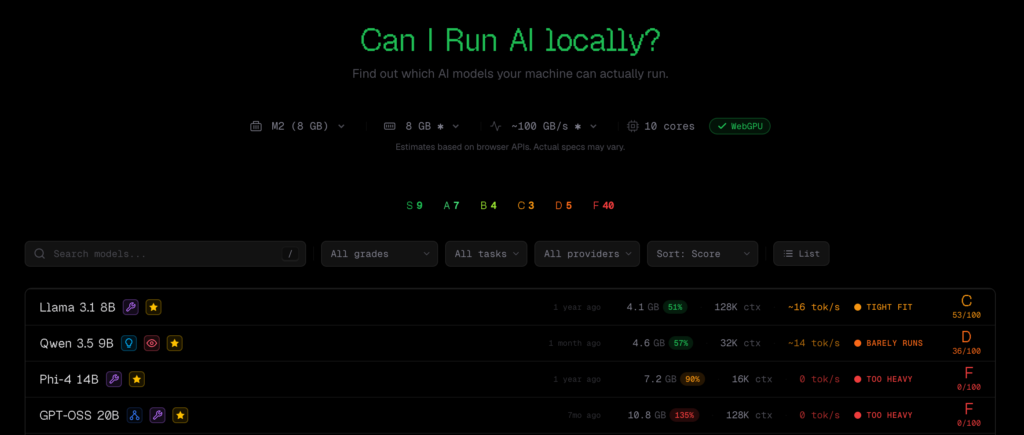
你想要在本地端自行安裝 LLM 大語言模型嗎?新手最常遇到的第一個問題是:**我的電腦,到底能跑什麼模型?**本文就為您介紹一個最近在 Hacker News 社群引發討論的工具 CanIRun.ai。
CanIRun.ai 是一個純網頁工具,操作很簡單:你只要打開瀏覽器,它就會自動透過 WebGPU API 自動偵測你的 GPU 型號與記憶體規格,再根據各模型的參數量、量化等級(Q4_K_M、Q8_0、F16 等)以及記憶體頻寬,估算每個模型的可執行性與推論速度(token/s),並以 S 到 F 的等級評分呈現結果。
涵蓋範圍從 0.8B 參數的超輕量模型,一路到 1T 參數的巨型 MoE(Mixture of Experts,混合專家架構)模型,資料來源包括 llama.cpp、Ollama 和 LM Studio 等主流本地推論工具。
Canirun.ai 的小缺點
雖然工具本身的概念獲得社群肯定,但方便的同時也有一點批。主要集中在兩個方向:硬體覆蓋不全,以及估算結果與實測差距。
硬體清單的缺漏是最常被提及的問題。RTX Pro 6000、RTX 5060 Ti 16GB、各家筆電版 GPU,目前榜上無名。Apple 晶片方面雖有列出,但最高僅到 192GB 記憶體配置,M3 Ultra 實際上可支援到 512GB。
估算誤差的問題則是,有使用者實測的結果與 CanIRun.ai 判定的結果不符。這類「實際能跑但網站說不行」的案例在討論串中反覆出現,讓部分使用者直接放棄參考其結果。
雖然該網站還有不少地方可以改進,不過如果是對新手小白來說,仍然可以快速確認自己的設備。
命令列替代方案 llmfit 登場
同時,社群中有人推薦替代工具 llmfit:這是一個命令列程式,能直接呼叫系統工具(包括 nvidia-smi)取得精確的 GPU 資訊,不依賴瀏覽器 API,許多人認為它比網頁版更實用、也更準確。
不過 llmfit 也帶來另一個話題:有使用者對它能在不請求任何明確權限的情況下,精確辨識 GPU 型號感到驚訝。這觸動了社群對瀏覽器指紋辨識與硬體隱私的敏感神經:如果一個網頁工具能透過 WebGPU API 偵測到你用什麼顯示卡,那這份資料會被怎麼運用?
有使用者建議,這類功能最理想的歸宿是直接整合進 Ollama,讓使用者從命令列就能根據本機硬體自動篩選可用模型,省去手動查找的麻煩。
社群最想要的
綜合社群反饋,CanIRun.ai 目前面臨的核心侷限不只是估算精確度,更在於評估維度太單一。使用者真正想知道的問題是:在我的硬體上,品質最好且速度可接受的模型是哪個?目前工具只能回答「能不能跑得起來」,卻沒有辦法回答「跑起來夠不夠好」。
社群希望未來能加入模型能力的基準評分,結合硬體估算,提供更完整的選擇依據。 其他技術面的改進方向包括:納入 CPU 記憶體共用策略(讓記憶體不足的 GPU 能借用系統記憶體)、支援 KV cache 卸載技巧,以及修正 MoE 模型的計算邏輯。
總的來說,工具的方向是對的,市場需求也確實存在:本地 AI 的門檻對一般使用者來說仍然偏高,能快速判斷「我的機器適合跑什麼」是剛需。CanIRun.ai 點到了這個痛點,只是現在還需要更多打磨。

免責聲明:本頁面資訊可能來自第三方,不代表 Gate 的觀點或意見。頁面顯示的內容僅供參考,不構成任何財務、投資或法律建議。Gate 對資訊的準確性、完整性不作保證,對因使用本資訊而產生的任何損失不承擔責任。虛擬資產投資屬高風險行為,價格波動劇烈,您可能損失全部投資本金。請充分了解相關風險,並根據自身財務狀況和風險承受能力謹慎決策。具體內容詳見聲明。
留言
0/400
暫無留言