AI Agent 的運作方式:從模型到執行機制
本課將深入解析 AI Agent 的運作邏輯,介紹模型、記憶、規劃、工具調用及回饋機制,並說明智能體如何完成複雜任務。
在上一課中,我們探討了 AI Agent 的基本定義,並明確區分了其與聊天機器人、AI 助手以及自動化腳本的差異。最核心的結論是:AI Agent 的價值不僅在於「能回答問題」,更在於「能夠圍繞目標主動採取行動」。然而,當我們談到 Agent 能執行任務時,也會衍生出新的疑問:它究竟如何完成這些任務?其「智能」來源於何處?為何既比一般模型強大,卻又明顯存在侷限?
要解答這些問題,我們需深入拆解 AI Agent 的內部架構。雖然不同產品和框架的實現方式各異,但從基本原理來看,大多數 AI Agent 均可理解為由模型、記憶、規劃、工具調用與反饋機制共同構成的任務系統。正是這些要素的協同,使 Agent 從單純語言生成模型,升級為能在數位環境中推動任務進展的執行者。
一、AI Agent 的核心組成
表面上看,許多 Agent 產品僅僅是一個具備對話框的應用介面,但在對話背後,實則包含多個彼此協作的模組。理解這些模組,有助於我們洞悉 Agent 的真實運作方式。
1. 模型:負責理解、推理與生成
模型是 Agent 的「大腦」。目前大多數 Agent 均建立於大型語言模型基礎上,這類模型具備優越的語言理解、知識整合、邏輯組織及指令執行能力。用戶輸入目標後,模型首先需理解任務意圖、判斷應執行的內容,並生成後續行動建議。
舉例來說,當用戶提出「請協助梳理某公鏈生態的熱門項目」時,模型需先辨識數個關鍵問題:任務需蒐集資訊,來源可能包括項目官網、社交平台或鏈上數據;結果不應僅為羅列,而需經過篩選與歸納;最終輸出形式或為結構化摘要。可見,模型的職責並非直接給出最終答案,而是作為任務理解與推理的中樞。
然而,僅有模型仍遠遠不足。再強大的模型也無法天然連結實時世界,無法自動讀取網頁、主動調用錢包或自發查詢資料庫。若要真正「做事」,還需其他模組配合。
2. 記憶:讓 Agent 保持上下文連貫
記憶機制決定了 Agent 能否在長鏈任務中維持一致性。缺乏記憶的系統,每次互動都像首次接觸,只能針對局部問題作答;具備記憶能力的 Agent,則能記錄用戶目標、執行進度、關鍵約束與過往結果,於多輪互動中持續推進任務。
記憶通常分為兩類:一種是短期記憶,即當前任務上下文中的資訊,如用戶剛給的需求、已完成步驟及中間結論;另一種是長期記憶,更像隨時更新的知識庫,用於儲存用戶偏好、常見任務模式或重要經驗。
在區塊鏈場景下,記憶尤其關鍵。許多鏈上任務並非一次性動作,而需持續監控、反覆判斷與分階段執行。例如,Agent 需記住用戶關注的協議、風險偏好、資產分布與操作習慣,才能提供更貼合需求的後續服務。
3. 規劃:將目標拆解為可執行步驟
規劃能力是 Agent 與傳統問答系統的關鍵分野。現實任務往往非一步可成,而需多個子任務協作。Agent 必須將抽象目標拆解為一系列可執行步驟,並根據執行結果持續修正路徑。
例如,「分析某賽道發展趨勢」這一簡單指令,實際上可能涵蓋明確研究範圍、蒐集相關項目、篩選代表性樣本、對比數據變化、提煉主要結論等多個階段。規劃模組的作用,是讓 Agent 不會將複雜任務簡化為一次性文本生成,而能像專業執行者般逐步推展。
當然,目前大多數 Agent 在規劃能力上仍有限。短鏈條任務表現尚可,但一旦任務過於複雜、路徑過長或依賴條件過多,計畫便容易偏離。這也是許多 Agent 看似「聰明」,但在長任務中仍易出錯的根本原因。
4. 工具調用:將語言能力轉化為行動力
工具調用是 Agent 能否真正落地的核心。若無工具,模型僅能停留於語言世界;有了工具,Agent 才能連結外部環境並採取實際行動。
常見工具包括搜尋引擎、資料庫、檔案系統、瀏覽器、API 介面、程式執行環境等。在區塊鏈領域,工具還涵蓋錢包、簽名服務、鏈上資料介面、智能合約調用介面、預言機及交易執行系統等。
工具調用的意義在於,將「知道該做什麼」與「實際去做了什麼」連結起來。Agent 可先憑模型判斷應查詢的資訊類型,再藉由工具獲取數據,根據結果決定是否繼續操作,最終形成閉環。因此,Agent 的競爭力不僅取決於模型本身,更取決於其連結的工具與執行權限。
5. 反饋機制:讓 Agent 執行過程中能修正方向
真實環境下的任務並非總能順利完成。搜尋結果可能不全、介面可能報錯、鏈上交易可能失敗、目標條件也可能中途變化。若無反饋機制,Agent 只能如腳本般失敗即終止。
反饋機制的作用,是讓 Agent 能讀取執行結果,據此決定是否繼續、重試、修正路徑或請求人工作確認。這一過程讓 Agent 由靜態系統轉為動態系統,不僅是「執行命令」,更是在執行中不斷檢查是否偏離目標。
本質上,反饋機制讓 Agent 更接近一種循環系統:理解任務、執行動作、獲取結果、修正下一步。循環越穩定,Agent 的可用性越高。
二、一個 AI Agent 如何完成任務?
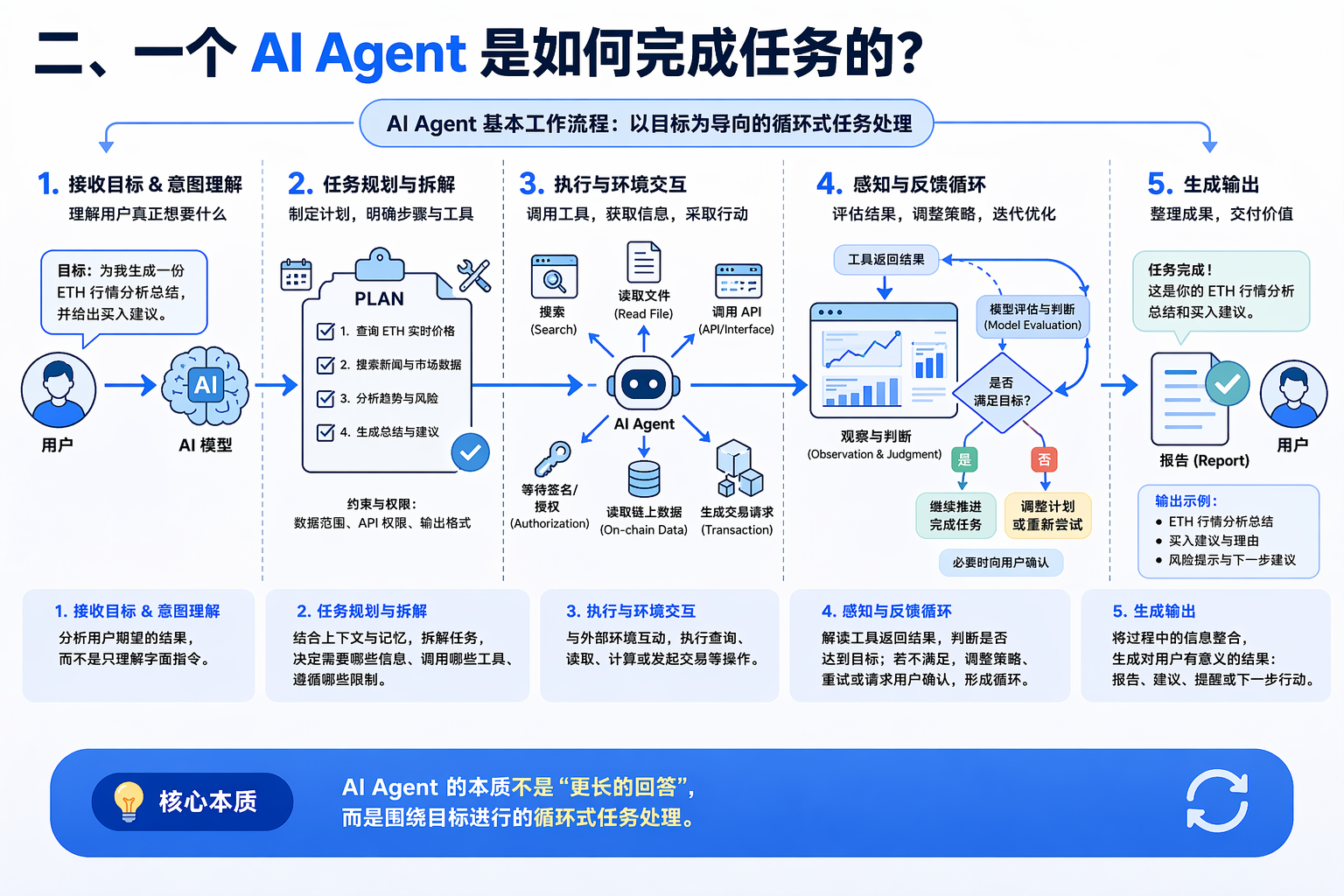
將上述模組整合後,便能清晰呈現 Agent 的基本工作流程。儘管不同產品實現細節各異,整體邏輯一般可歸納為以下幾個階段:
- Agent 接收用戶目標,並由模型完成意圖理解,分析用戶真正想達成的結果,而非僅僅執行字面指令。
- Agent 結合上下文與記憶資訊,對任務進行拆解,形成初步計畫,判斷所需資訊、應調用工具、權限限制及最終輸出形式。
- Agent 開始調用外部工具,與環境互動,可能搜尋資料、讀取文件、訪問介面、檢查帳戶狀態,或於區塊鏈場景下讀取鏈上數據、生成交易請求、等待簽名授權。
- 系統讀取工具返回結果,並由模型進行解釋與判斷。若結果符合要求,任務繼續推進;若結果不全或出錯,Agent 可調整策略、重試,或請用戶確認。
- 當任務達成目標時,Agent 會將過程資訊整理為用戶可用的輸出,如總結報告、執行結果、風險提示或後續建議。
因此,Agent 的本質並非「更長的回答」,而是「圍繞目標循環推進的任務處理」。
三、單 Agent 與多 Agent 的區別
隨著 Agent 架構演進,單 Agent 與多 Agent 的根本區分在於任務複雜度的選擇:單 Agent 適合路徑明確、風險較低的任務,如行情分析、資訊整合或簡單交易執行,可由單一系統完成閉環;而在 Crypto 場景下,若涉及多步驟、高資金風險或跨鏈操作(如自動化交易、資產調度、DAO 資金管理),則更適合多 Agent 分工,將數據監控、策略判斷、執行與風控分配給不同角色協作。但多 Agent 並非天然優於單 Agent,因為會帶來更高的溝通與系統複雜度,因此目前大多數實際應用仍以單 Agent 為主,多 Agent 則用於複雜策略或進階工作流。
示例
於 DeFi 自動套利場景下,僅需「發現價差 → 下單」時,單 Agent 即可勝任。
但若涉及「跨鏈尋找價差 → 計算 Gas 與滑點 → 評估橋風險 → 控管倉位 → 執行後複核」,則更適合多 Agent 分工:一個負責監控行情,一個負責效益計算,一個執行交易,一個負責風控審核。
本質上,這是從「一人作業」升級為「團隊協作」。
四、AI Agent 的能力邊界
理解 Agent 的運作方式,也意味著須認識其出錯原因。許多用戶誤將「可自主執行任務」等同於「可穩定完成所有任務」,這是一種極危險的認知偏誤。
- Agent 的推理與判斷仍依賴模型,而模型本身可能出現幻覺、誤讀上下文或邏輯偏差。即便表面條理清晰,結論亦未必正確。
- 工具調用雖擴展了 Agent 能力,但工具並非總可靠。外部資料可能過時,介面可能異常,鏈上狀態瞬息萬變。Agent 若處理不當,結果自然偏離預期。
- 規劃能力不等同於人類級理解。許多 Agent 能順利完成結構明確的任務,但面對模糊目標、衝突約束或長期任務時,常出現路徑混亂、執行中斷或重複操作。
- 權限與安全始終是 Agent 落地的核心邊界。尤其在區塊鏈場景下,Agent 一旦操作錢包、資產或合約,錯誤不僅僅是「答錯問題」,更可能造成實際損失。因此,目前多數可靠的鏈上 Agent 不追求完全自治,而更強調「可控自動化」與「關鍵環節人工作確認」。
五、本課小結
本課核心在於幫助我們理解,AI Agent 並非神祕黑箱,而是由模型、記憶、規劃、工具調用與反饋機制協同構成的任務系統——模型負責理解推理,記憶確保連貫,規劃拆解目標,工具連結環境,反饋則讓執行過程得以修正方向。
理解這一機制至關重要,因為它直接決定了 Agent 為何優於一般聊天機器人,也解釋了其尚未被神化的原因。Agent 的價值源於「模型能力 + 工具能力 + 執行機制」的結合,侷限亦來自這些環節的不穩定與複雜性。
下一課我們將進一步探討另一核心問題:為何區塊鏈成為 AI Agent 的理想應用場景?屆時將看到開放、可編程且可驗證的鏈上環境,如何為 Agent 提供獨特的執行空間。
相關課程

加密貨幣領域的身份驗證項目概覽

主要加密貨幣衍生品項目概覽

主節點代幣

去中心化身份基礎

加密領域自主研究指南(DYOR)
