DeepSeek เปิดตัวตัวอย่าง (preview) ของ DeepSeek-V4-Pro และ DeepSeek-V4-Flash ในวันที่ 24 เมษายน 2026 โดยทั้งสองเป็นโมเดลแบบ open-weight ที่มีหน้าต่างคอนเท็กซ์ต์หนึ่งล้านโทเค็น และมีราคาต่ำกว่าทางเลือกของฝั่งตะวันตกอย่างมีนัยสำคัญ โมเดล V4-Pro มีค่าใช้จ่าย $1.74 ต่ออินพุตโทเค็นหนึ่งล้านโทเค็น และ $3.48 ต่อเอาต์พุตโทเค็นหนึ่งล้านโทเค็น—ประมาณ 1/20 ของราคา Claude Opus 4.7 และต่ำลง 98% เมื่อเทียบกับ GPT-5.5 Pro ตามสเปกอย่างเป็นทางการของบริษัท
สถาปัตยกรรมโมเดลและขนาด
DeepSeek-V4-Pro มีพารามิเตอร์รวมทั้งหมด 1.6 ล้านล้าน (1.6 trillion) พารามิเตอร์ ทำให้เป็นโมเดลโอเพนซอร์สที่ใหญ่ที่สุดในตลาด LLM ณ ปัจจุบัน อย่างไรก็ตาม มีเพียง 49 พันล้านพารามิเตอร์ที่ถูกเปิดใช้งานต่อรอบการอนุมาน (inference pass) โดยใช้สิ่งที่ DeepSeek เรียกว่าแนวทาง Mixture-of-Experts ซึ่งได้รับการปรับปรุงต่อเนื่องตั้งแต่ V3 การออกแบบนี้ทำให้โมเดลทั้งก้อนสามารถยังคงอยู่เฉยๆ ได้ ขณะที่มีเพียงส่วนที่เกี่ยวข้องเท่านั้นที่จะถูกเปิดใช้งานสำหรับคำขอใดๆ ลดต้นทุนการคำนวณในขณะที่ยังคงความสามารถด้านความรู้ไว้
DeepSeek-V4-Flash ทำงานในระดับที่เล็กกว่า โดยมีพารามิเตอร์รวมทั้งหมด 284 พันล้านพารามิเตอร์ และพารามิเตอร์ที่เปิดใช้งานอยู่ 13 พันล้าน ตามเกณฑ์มาตรฐานของ DeepSeek มัน “ทำผลงานด้านการให้เหตุผลเทียบเคียงได้กับเวอร์ชัน Pro เมื่อให้ทรัพยากรงบคิด (thinking budget) ที่มากกว่า”
ทั้งสองโมเดลรองรับคอนเท็กซ์ต์หนึ่งล้านโทเค็นเป็นฟีเจอร์มาตรฐาน—ประมาณ 750,000 คำ หรือราวกับทั้งไตรภาค “Lord of the Rings” พร้อมข้อความเพิ่มเติมอีกส่วนหนึ่ง
นวัตกรรมเชิงเทคนิค: กลไก Attention ในระดับสเกล
DeepSeek แก้ปัญหาการขยายตัวเชิงการคำนวณ (computational scaling problem) ที่มีอยู่ในงานประมวลผลคอนเท็กซ์ต์ระยะยาว โดยการประดิษฐ์ attention ประเภทใหม่ 2 แบบ ตามรายละเอียดในเอกสารเชิงเทคนิคของบริษัทที่มีให้บน GitHub
กลไก attention ของ AI ทั่วไปเผชิญกับปัญหาการสเกลที่โหดร้าย: ทุกครั้งที่ความยาวคอนเท็กซ์ต์เพิ่มเป็นสองเท่า ต้นทุนการคำนวณจะเพิ่มขึ้นประมาณสี่เท่า วิธีแก้ของ DeepSeek ประกอบด้วยแนวทางสองส่วนที่เสริมกัน:
Compressed Sparse Attention ทำงานเป็นสองขั้นตอน ขั้นแรกจะบีบอัดกลุ่มของโทเค็น—เช่น ทุกๆ 4 โทเค็น—ให้เป็นรายการเดียว จากนั้นแทนที่จะให้ความสนใจกับรายการที่ถูกบีบอัดทั้งหมด จะใช้ “Lightning Indexer” เพื่อคัดเลือกเฉพาะผลลัพธ์ที่เกี่ยวข้องที่สุดสำหรับคำถามที่กำหนด วิธีนี้จะลดขอบเขตของ attention จากหนึ่งล้านโทเค็นให้กลายเป็นชุดที่เล็กลงมากของชิ้นส่วนที่สำคัญ
Heavily Compressed Attention ใช้วิธีที่เข้มงวดกว่า โดยยุบทุกๆ 128 โทเค็นให้เป็นรายการเดียว โดยไม่ทำการคัดเลือกแบบ sparse แม้ว่าจะทำให้รายละเอียดเชิงละเอียดหายไป แต่จะให้มุมมองภาพรวมทั่วโลกที่ราคาถูกมาก attention ทั้งสองแบบจะทำงานสลับกันในเลเยอร์ที่ต่อเนื่องกัน ทำให้โมเดลสามารถคงทั้งรายละเอียดและภาพรวมเอาไว้
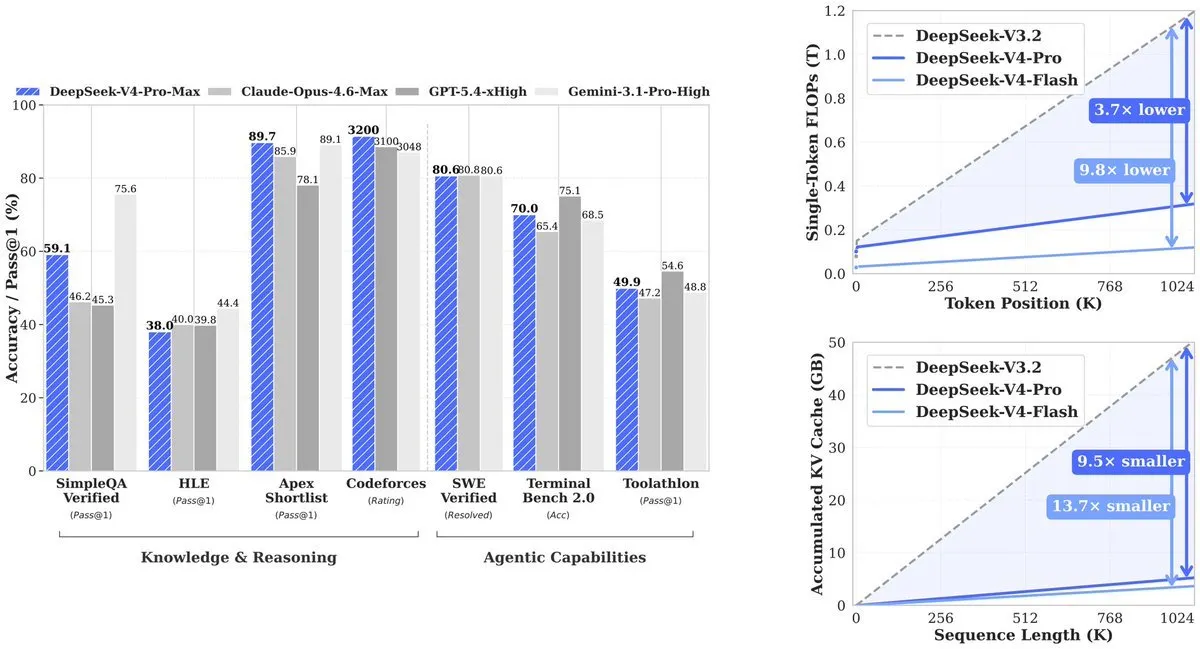
ผลลัพธ์: V4-Pro ใช้พลังการคำนวณ 27% ของที่รุ่นก่อน (V3.2) ต้องใช้ KV cache—หน่วยความจำที่จำเป็นต่อการติดตามคอนเท็กซ์ต์—ลดลงเหลือ 10% ของ V3.2 V4-Flash ดันประสิทธิภาพให้สูงขึ้นอีก: ใช้พลังการคำนวณ 10% และหน่วยความจำ 7% เมื่อเทียบกับ V3.2
ผลการทดสอบ (Benchmark) และตำแหน่งการแข่งขัน
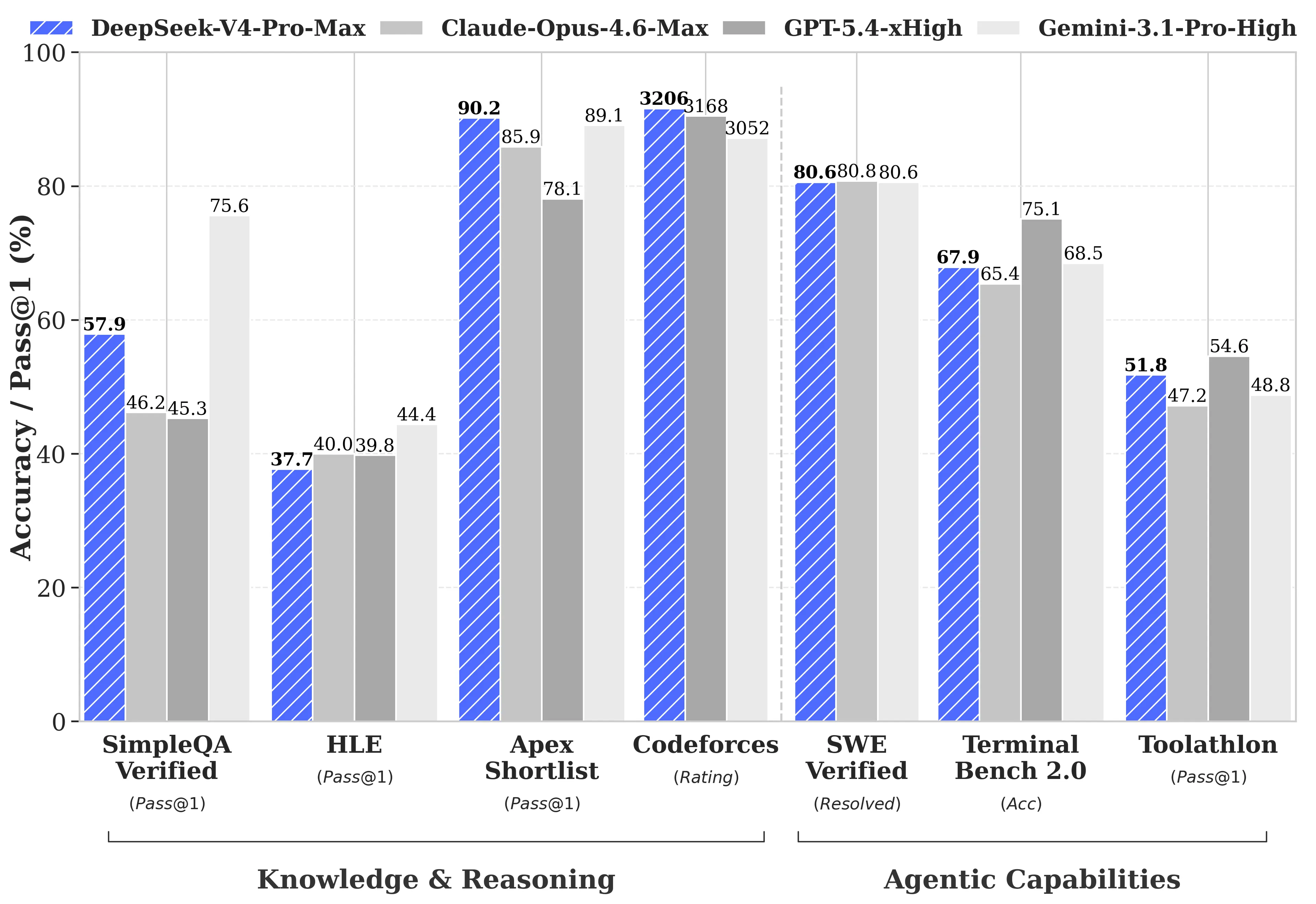
DeepSeek เผยแพร่การเปรียบเทียบ benchmark อย่างครอบคลุมกับ GPT-5.4 และ Gemini-3.1-Pro รวมถึงหมวดที่ V4-Pro ตามหลังคู่แข่ง ในงานด้านการให้เหตุผล (reasoning) V4-Pro ตามหลัง GPT-5.4 และ Gemini-3.1-Pro ประมาณสามถึงหกเดือน ตามรายงานเชิงเทคนิคของ DeepSeek
จุดที่ V4-Pro นำหน้า:
- Codeforces (การแข่งขันเขียนโปรแกรมเชิงยุทธวิธี (competitive programming)): V4-Pro ได้ 3,206 คะแนน ทำให้ราวอันดับที่ 23 จากผู้เข้าร่วมการแข่งขันที่เป็นมนุษย์จริง
- Apex Shortlist (ชุดโจทย์คณิตศาสตร์และ STEM ที่คัดสรร): อัตราผ่าน 90.2% เทียบกับ Opus 4.6 ที่ 85.9% และ GPT-5.4 ที่ 78.1%
- SWE-Verified (การแก้ปัญหา issue บน GitHub): 80.6% เท่ากับ Claude Opus 4.6
จุดที่ V4-Pro ตามหลัง:
- MMLU-Pro (การทำงานแบบหลายภารกิจ (multitasking)): Gemini-3.1-Pro ที่ 91.0% เทียบกับ V4-Pro ที่ 87.5%
- GPQA Diamond (ความรู้เชิงผู้เชี่ยวชาญ): Gemini ที่ 94.3 เทียบกับ V4-Pro ที่ 90.1
- Humanity’s Last Exam (ระดับบัณฑิตศึกษา): Gemini-3.1-Pro ที่ 44.4% เทียบกับ V4-Pro ที่ 37.7%
ในงานคอนเท็กซ์ต์ระยะยาว V4-Pro นำหน้าโมเดลโอเพนซอร์ส และเอาชนะ Gemini-3.1-Pro บน CorpusQA (การจำลองการวิเคราะห์เอกสารจริงด้วยคอนเท็กซ์ต์หนึ่งล้านโทเค็น) แต่แพ้ให้กับ Claude Opus 4.6 ใน MRCR ซึ่งวัดการดึงข้อมูลเฉพาะที่ถูกฝังอยู่ลึกในข้อความระยะยาว
ความสามารถด้านเอเจนต์และการเขียนโค้ด
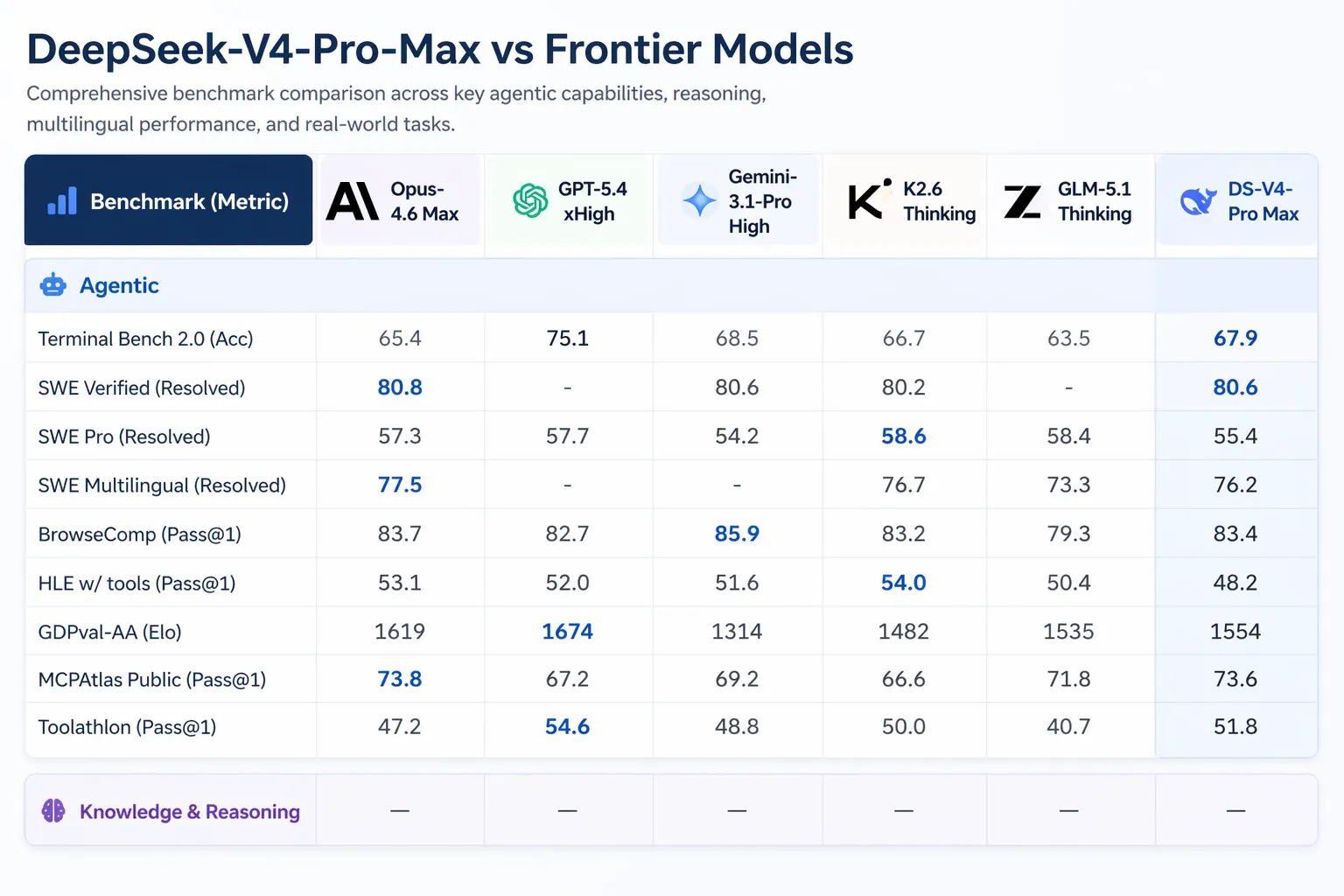
V4-Pro สามารถรันใน Claude Code, OpenCode และเครื่องมือเขียนโค้ด AI อื่นๆ ได้ ตามแบบสำรวจภายในของ DeepSeek เกี่ยวกับนักพัฒนา 85 คนที่ใช้ V4-Pro เป็นเอเจนต์เขียนโค้ดหลักของพวกเขา 52% กล่าวว่า “พร้อม” ที่จะให้เป็นโมเดลค่าเริ่มต้น, 39% เอียงไปทางใช่ และมีน้อยกว่า 9% ที่บอกว่าไม่ DeepSeek ยังทดสอบภายในและพบว่า V4-Pro ทำผลงานได้ดีกว่า Claude Sonnet และใกล้เคียงกับ Claude Opus 4.5 ในงานเขียนโค้ดแบบเชิงเอเจนต์ (agentic coding tasks)
Artificial Analysis จัดอันดับให้ V4-Pro เป็นอันดับหนึ่งในบรรดาโมเดล open-weight ทั้งหมดบน GDPval-AA ซึ่งเป็น benchmark สำหรับการทดสอบงานด้านความรู้ที่มีคุณค่าทางเศรษฐกิจ ครอบคลุมงานด้านการเงิน กฎหมาย และการวิจัย V4-Pro-Max ได้ 1,554 Elo นำหน้า GLM-5.1 (1,535) และ M2.7 ของ MiniMax (1,514) Claude Opus 4.6 ได้ 1,619 ใน benchmark เดียวกัน
V4 แนะนำ “interleaved thinking” ซึ่งคงโซ่ความคิดทั้งหมด (full chain of thought) ไว้ตลอดการเรียกใช้เครื่องมือ (tool calls) ในโมเดลก่อนหน้า เมื่อเอเจนต์ทำการเรียกใช้เครื่องมือหลายครั้ง—เช่น ค้นหาเว็บ รันโค้ด แล้วค่อยค้นหาอีกครั้ง—คอนเท็กซ์ต์ด้านการให้เหตุผลของโมเดลจะถูกล้างระหว่างรอบ V4 รักษาความต่อเนื่องของการให้เหตุผลข้ามขั้นตอน ป้องกันการสูญเสียคอนเท็กซ์ต์ในเวิร์กโฟลว์อัตโนมัติที่ซับซ้อน
ภูมิทัศน์การแข่งขันและบริบทด้านราคา
การเปิดตัว V4 เกิดขึ้นท่ามกลางกิจกรรมที่มีนัยสำคัญในสายงาน AI Anthropic ส่ง Claude Opus 4.7 ออกในวันที่ 16 เมษายน 2026 OpenAI เปิดตัว GPT-5.5 ในวันที่ 23 เมษายน 2026 โดย GPT-5.5 Pro มีราคา $30 ต่ออินพุตโทเค็นหนึ่งล้านโทเค็น และ $180 ต่อเอาต์พุตโทเค็นหนึ่งล้านโทเค็น GPT-5.5 เอาชนะ V4-Pro ใน Terminal Bench 2.0 (82.7% เทียบกับ 70.0%) ซึ่งทดสอบเวิร์กโฟลว์ของเอเจนต์บนบรรทัดคำสั่ง (command-line agent) ที่ซับซ้อน
Xiaomi เปิดตัว MiMo V2.5 Pro ในวันที่ 22 เมษายน 2026 โดยให้ความสามารถมัลติโหมดเต็มรูปแบบ (image, audio, video) ที่ $1 อินพุต และ $3 เอาต์พุต ต่อหนึ่งล้านโทเค็น Tencent เปิดตัว Hy3 ในวันเดียวกับ GPT-5.5
เพื่อมุมมองด้านราคา: ซีอีโอของ Cline คือ Saoud Rizwan ระบุว่า หาก Uber ใช้ DeepSeek แทน Claude งบประมาณ AI ของ Uber ในปี 2026—ซึ่งรายงานว่าพอสำหรับการใช้งานสี่เดือน—จะสามารถอยู่ได้นานถึงเจ็ดปี
การใช้งานจริงและความพร้อมใช้งาน
ทั้ง V4-Pro และ V4-Flash ใช้ใบอนุญาต MIT และมีให้ใช้งานบน Hugging Face โมเดลทั้งสองยังเป็นแบบข้อความเท่านั้น (text-only) ในตอนนี้; DeepSeek ระบุว่ากำลังทำงานเพื่อเพิ่มความสามารถแบบมัลติโหมด ทั้งสองโมเดลสามารถรันได้ฟรีบนฮาร์ดแวร์ภายในเครื่อง หรือปรับแต่งตามความต้องการของบริษัท
ปลายทาง (endpoints) deepseek-chat และ deepseek-reasoner ที่มีอยู่เดิมของ DeepSeek ได้กำหนดเส้นทางไปยัง V4-Flash อยู่แล้วในโหมด non-thinking และ thinking ตามลำดับ endpoint รุ่นเดิมของ deepseek-chat และ deepseek-reasoner จะหยุดให้บริการในวันที่ 24 กรกฎาคม 2026
DeepSeek ฝึก V4 บางส่วนโดยใช้ชิป Huawei Ascend ซึ่งหลีกเลี่ยงข้อจำกัดการส่งออกของสหรัฐฯ บริษัทระบุว่าเมื่อมี supernodes ใหม่ 950 ตัวออนไลน์ในช่วงปลายปี 2026 ราคา (ที่ต่ำอยู่แล้ว) ของโมเดล Pro จะลดลงต่อไป
นัยเชิงปฏิบัติ
สำหรับองค์กร โครงสร้างราคามีแนวโน้มจะทำให้การคำนวณคุ้มค่า (cost-benefit) เปลี่ยนไป โมเดลที่นำหน้า benchmark แบบ open-source ที่ $1.74 ต่ออินพุตหนึ่งล้านโทเค็น ทำให้การประมวลผลเอกสารขนาดใหญ่ การตรวจทานทางกฎหมาย และท่อทาง (pipelines) สำหรับการสร้างโค้ด ถูกทำให้ราคาถูกลงอย่างมากเมื่อเทียบกับหกเดือนก่อนหน้า คอนเท็กซ์ต์หนึ่งล้านโทเค็นทำให้สามารถประมวลผลทั้งโค้ดเบสหรือเอกสารยื่นด้านกฎระเบียบในคำขอเดียว แทนที่จะถูกแบ่งเป็นชิ้นผ่านหลายๆ การเรียก
สำหรับนักพัฒนาและผู้สร้างอิสระ V4-Flash คือสิ่งที่ควรพิจารณาเป็นหลัก ด้วยราคา $0.14 สำหรับอินพุต และ $0.28 สำหรับเอาต์พุต ต่อหนึ่งล้านโทเค็น มันถูกกว่าโมเดลที่เคยถูกมองว่าเป็นตัวเลือกงบประมาณเมื่อหนึ่งปีก่อน ในขณะที่จัดการงานส่วนใหญ่ที่เวอร์ชัน Pro ทำได้