Открытые данные блокчейна ценны только тогда, когда к ним есть доступ и они понятны пользователям. Новички в криптовалютах обычно обращают внимание лишь на цены токенов — это просто. Однако с опытом приходит понимание, что для глубокого анализа рынка нужны данные по пулам для DeFi, метрики удержания пользователей в GameFi и другие показатели, такие как TVL, информация о кошельках, депозиты и выводы средств.
Если вы хотите исследовать перемещения крупных держателей между проектами или оценить влияние PR-кризиса на протокол, потребуется особый подход. Как получить такие данные и создать индивидуальные решения для точных аналитических задач?
Добыть необработанные данные с одной цепочки технически несложно. Поэтому в сфере аналитики блокчейна существует множество сервисов. Процесс сводится к структурированию — стандартизации миллионов строк данных, поступающих в базу, несмотря на разнородность блокчейнов. Благодаря продуманному UX данные становятся наглядными и удобными для восприятия.
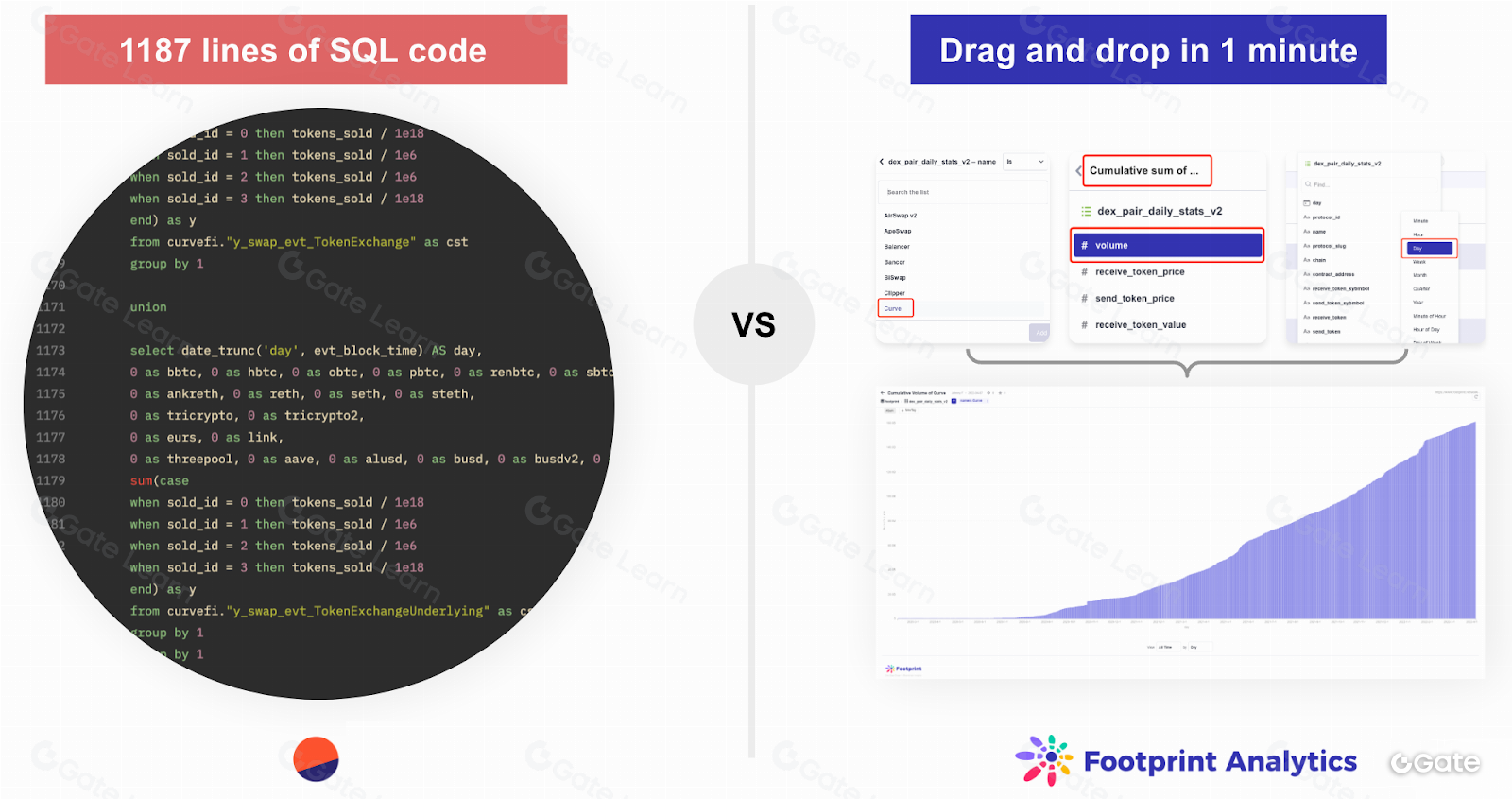
Пользователь может добавить на график метрики из разных проектов для сравнения. В Dune Analytics для этого необходим SQL. В Nansen доступны настраиваемые графики, но с меньшей гибкостью. Сложности возникают при сравнении данных с разных блокчейнов. В Footprint мы создали модель, которая агрегирует необработанные данные и индексирует их для осмысленного анализа.
Информация о миллионах транзакций делится по доменам — наш движок определяет, относится ли транзакция к GameFi, NFT, DEX или другой категории. Мы декодируем данные, чтобы аналитики могли находить нужные параметры: время блока, TVL, цену токена и сразу визуализировать их на графике.
Вместо непонятных строк из символов вы видите адреса кошельков, блокчейны, NFT-коллекции и другие значимые категории.
Опытные аналитики могут работать с необработанными данными напрямую, используя SQL или Python.
Создать самую масштабную аналитическую платформу в отрасли (сейчас поддерживается 22 блокчейна) при сохранении высокой производительности — сложная инженерная задача.
В этой статье подробно раскрывается архитектура наших данных.
Проблема кросс-чейн аналитики
Яблоки и апельсины сравнивать нельзя.
Как узнать толщину кожуры у Golden Delicious или количество семян в апельсине Cara Cara? Это бессмысленно. Но если сравнивать сладость, размер, твердость, мировое потребление — параметры, которые можно логически измерить для обоих фруктов, сравнение становится осмысленным.
Такая логическая категоризация — это и есть структурированные семантические данные. Неважно, как реализован код выпуска NFT в Solana или Ethereum, важно объединить эти данные в одну категорию — «Минтинг».
Большинство ведущих аналитических платформ позволяют сравнивать яблоки с апельсинами. В Footprint Analytics мы сравниваем яблоки, апельсины, киви, ананасы и многое другое.
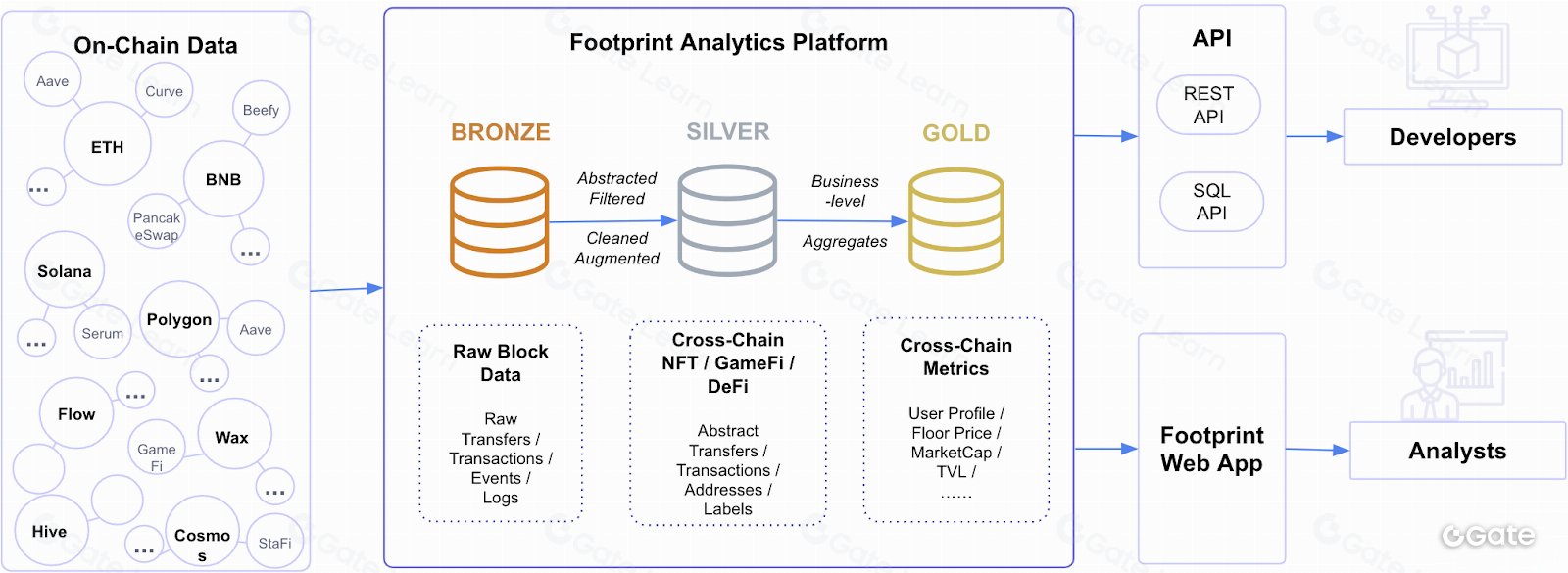
На декабрь мы обрабатываем данные с 22 блокчейнов — это больше, чем у любой другой платформы. Footprint Analytics автоматически собирает блоки, логи, трассы и транзакции. Дополняем это данными сообщества и сторонних API (например, ценами токенов с Coingecko). Все эти данные изначально сырые и неструктурированные. Мы структурируем их по категориям: заимствование, кредитование, доходное фермерство и др. Так любые данные блокчейна становятся доступны каждому.
Как Footprint Analytics сочетает гибкость и простоту
Веб-приложение Footprint построено на открытой платформе Metabase. Подробнее о Metabase. Мы выбрали Metabase, потому что технология открытая — пользователи могут дорабатывать код и совершенствовать продукт.
В последней версии Metabase появились модели. Эта функция позволяет готовить данные из других таблиц той же базы, чтобы предвосхищать возможные вопросы пользователей.
Аналитики строят графики на Footprint Analytics с помощью удобного конструктора drag-and-drop. Это снижает порог входа: даже без технических знаний любой пользователь может получить бизнес-ценность из продукта.
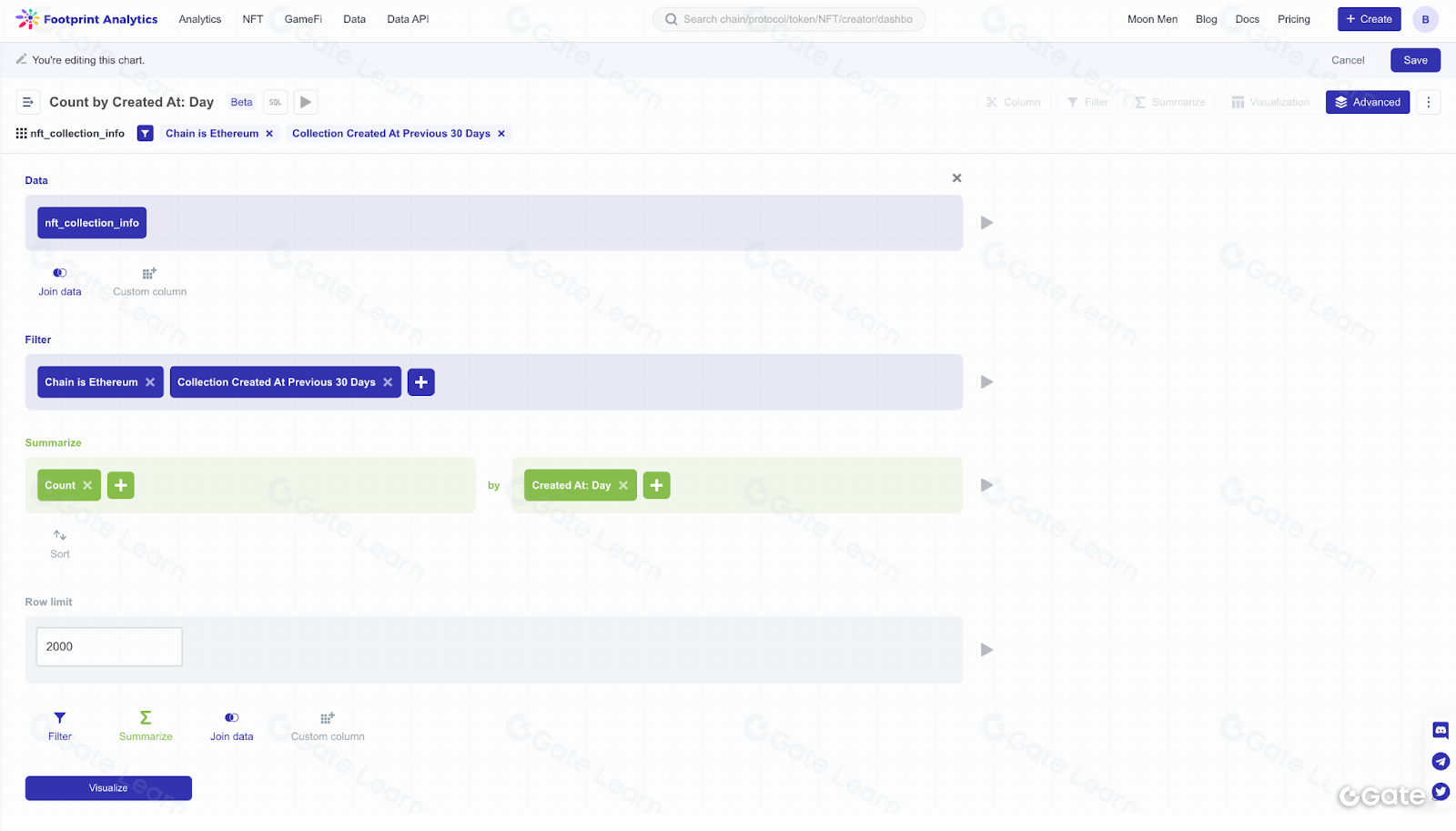
Стоит отметить, что архитектурно Metabase — это абстракция над SQL: любой drag-and-drop-запрос можно представить в виде SQL. Поэтому тем, кто предпочитает сложные запросы и работу с кодом, доступен прямой SQL.
Многие альтернативные аналитические решения позволяют анализировать разные сети на разных уровнях. Но чаще всего они либо очень гибкие и требуют знания языков запросов или программирования, либо очень простые с готовыми скриптами и низкой гибкостью.
Охват
У нас один из самых широких охватов на рынке. Подробности о текущем охвате и структуре данных (уровни, домены) — в следующем разделе.
Как Footprint Analytics обрабатывает такие объемы данных?
Наше главное конкурентное преимущество — платформа Footprint Analytics на базе Footprint Machine Learning Platform.
«Платформа Footprint Analytics» — это и сайт, доступный по footprint.network, и движок, который выполняет основную обработку данных.
Уровни
Мы преобразуем Bronze Data в Silver, затем Gold с помощью ETL-инструментов — Python и SQL. В будущем мы планируем сделать этот код, включая обработку Bronze–Silver, с открытым исходным кодом.
Мы также даем организациям доступ к этим структурированным данным через наш API блокчейн-данных.
Получайте самые полные данные блокчейна через Footprint Data API
UI — не единственный интерфейс для доступа к данным. Все поддерживаемые интерфейсы перечислены здесь: Interfaces
До Footprint Analytics анализ блокчейна ограничивался неполными и неструктурированными данными. Даже ведущие организации сталкивались с задержками доступа, ограничениями по производительности и дорогой агрегацией API.
Наша платформа парсит данные on-chain с 23 блокчейнов и переводит их в уровни Silver и Gold, поэтому любая организация получает доступ к большинству мировых данных GameFi, NFT и DeFi через единый API. В Footprint Analytics доступны REST API и SQL API.
Какие приложения можно создать на этих данных? Несколько примеров:
- Отслеживать лучшие и худшие показатели удержания игроков по всем GameFi-проектам
- Получать уведомления, когда крупные кошельки вносят или выводят средства на нужные цепочки или протоколы
- Сравнивать кросс-чейн колебания TVL с ценами на сырье
- Создавать собственные дашборды для NFT-коллекций из разных сетей
- Находить самые горячие коллекции и получать аналитику по 15 000+ проектам
- Отслеживать потоки средств крупных держателей для поиска инвестиционных возможностей и оценки рисков
С Footprint любой пользователь становится ближе к аналитике блокчейна — будь вы инвестор, аналитик, трейдер, разработчик или просто изучаете любимый криптопроект.






