O DeepSeek lançou versões preview do DeepSeek-V4-Pro e do DeepSeek-V4-Flash a 24 de abril de 2026, ambos modelos open-weight com janelas de contexto de um milhão de tokens e preços significativamente abaixo das alternativas ocidentais comparáveis. O modelo V4-Pro custa $1.74 por milhão de tokens de entrada e $3.48 por milhão de tokens de saída — aproximadamente 1/20 do preço do Claude Opus 4.7 e 98% menos do que o GPT-5.5 Pro, de acordo com as especificações oficiais da empresa.
Arquitetura do Modelo e Escala
O DeepSeek-V4-Pro apresenta 1,6 biliões de parâmetros totais, tornando-se no maior modelo open-source no mercado de LLM até à data. No entanto, apenas 49 mil milhões de parâmetros são ativados por passe de inferência, usando o que a DeepSeek chama de abordagem Mixture-of-Experts, refinada desde a V3. Este desenho permite que o modelo completo permaneça em latência enquanto apenas são ativados recortes relevantes para qualquer pedido em particular, reduzindo custos de computação enquanto mantém capacidade de conhecimento.
O DeepSeek-V4-Flash opera com uma escala menor, com 284 mil milhões de parâmetros totais e 13 mil milhões de parâmetros ativos. De acordo com os benchmarks da DeepSeek, ele “atinge desempenho de raciocínio comparável ao da versão Pro quando lhe é dado um orçamento de pensamento maior”.
Ambos os modelos suportam um milhão de tokens de contexto como funcionalidade padrão — aproximadamente 750.000 palavras, ou aproximadamente toda a trilogia de “Lord of the Rings” mais texto adicional.
Inovação Técnica: Mecanismos de Attention à Escala
A DeepSeek resolveu o problema de escalamento computacional inerente ao processamento de longo contexto, inventando dois novos tipos de attention, conforme detalhado no artigo técnico da empresa disponível no GitHub.
Os mecanismos de attention padrão de IA enfrentam um problema de escalamento brutal: sempre que o comprimento do contexto dobra, o custo de computação aumenta aproximadamente em quatro vezes. A solução da DeepSeek envolve duas abordagens complementares:
Compressed Sparse Attention funciona em dois passos. Primeiro, comprime grupos de tokens — por exemplo, cada 4 tokens — para uma única entrada. Depois, em vez de fazer attention a todas as entradas comprimidas, usa um “Lightning Indexer” para selecionar apenas os resultados mais relevantes para qualquer query dada. Isto reduz o âmbito do attention do modelo de um milhão de tokens para um conjunto muito menor de chunks importantes.
Heavily Compressed Attention adota uma abordagem mais agressiva, colapsando cada 128 tokens numa única entrada sem seleção esparsa. Embora isso perca detalhe fino, fornece uma visão global extremamente barata. Os dois tipos de attention correm em camadas alternadas, permitindo ao modelo manter tanto detalhe quanto visão geral.
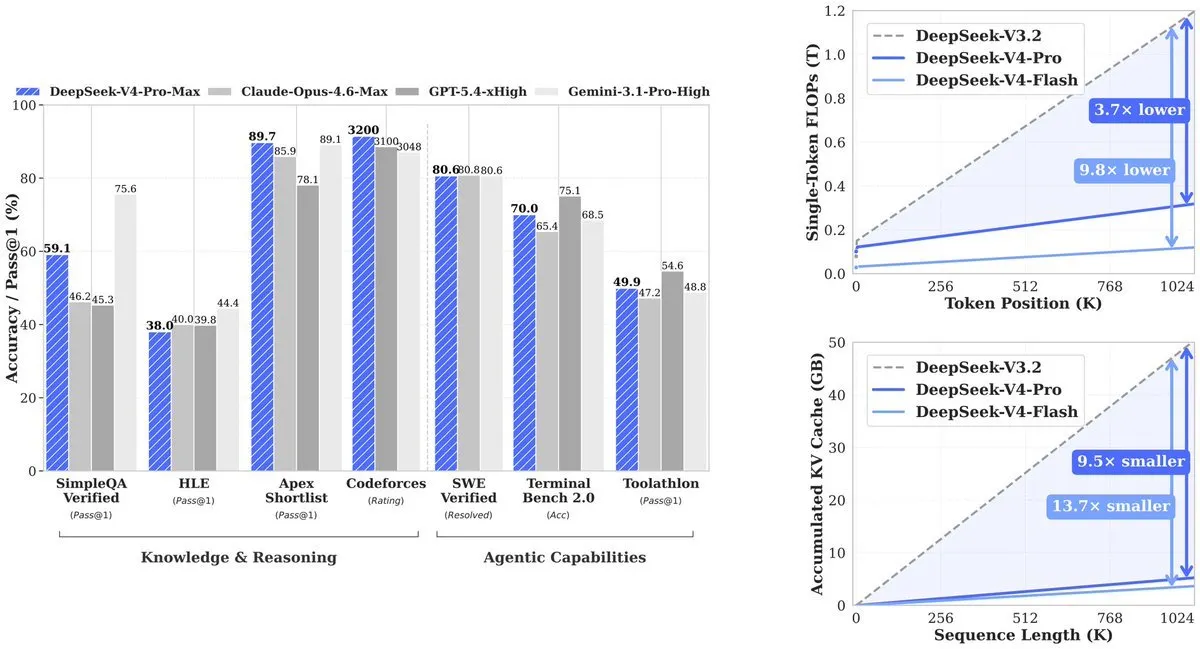
O resultado: o V4-Pro usa 27% da computação que o seu predecessor (V3.2) exigia. A KV cache — a memória necessária para acompanhar o contexto — desce para 10% da V3.2. O V4-Flash empurra a eficiência ainda mais: 10% de computação e 7% de memória em comparação com a V3.2.
Desempenho em Benchmark e Posição Competitiva
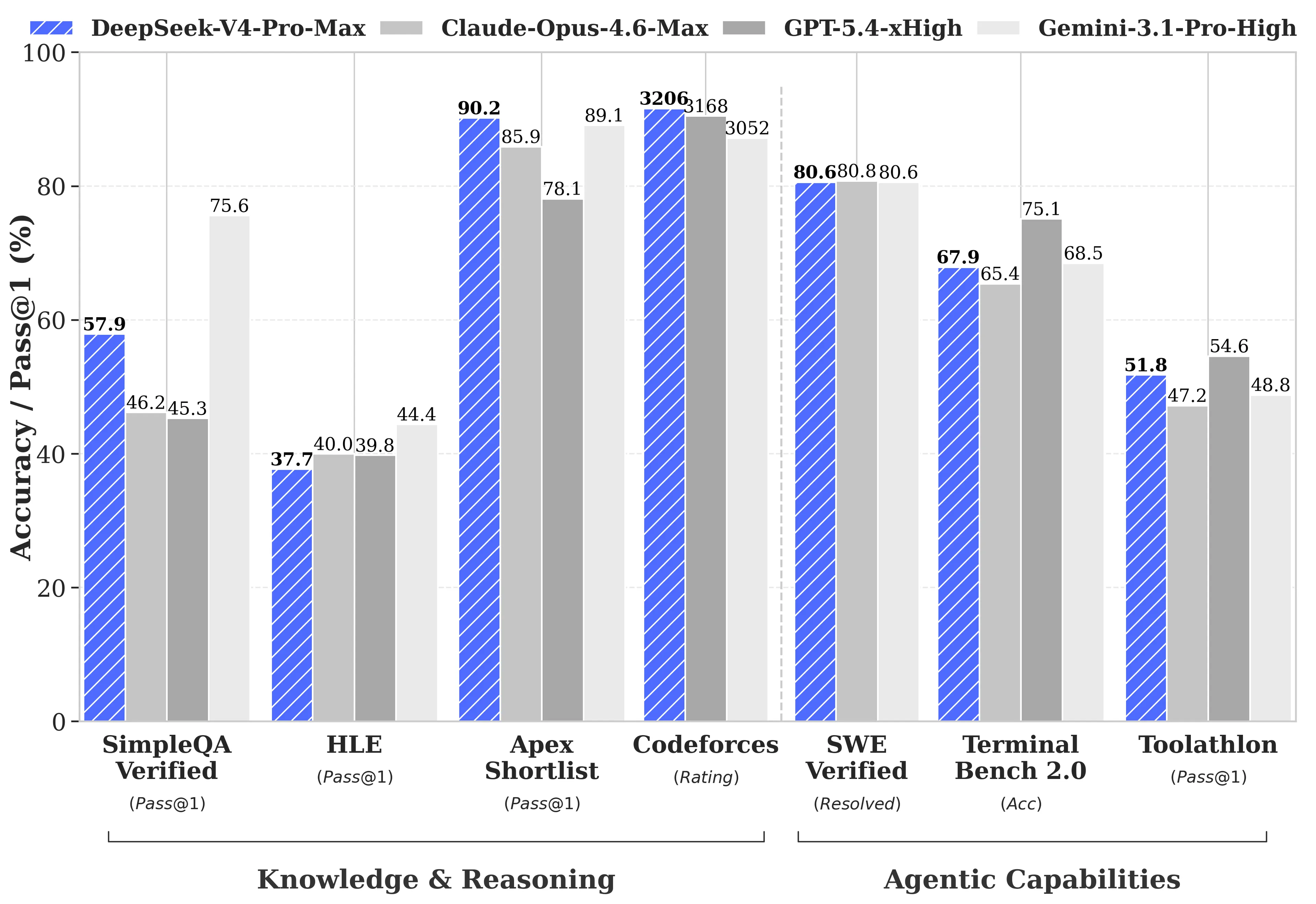
A DeepSeek publicou comparações abrangentes de benchmarks contra o GPT-5.4 e o Gemini-3.1-Pro, incluindo áreas em que o V4-Pro fica atrás dos concorrentes. Em tarefas de raciocínio, o raciocínio do V4-Pro fica atrás do GPT-5.4 e do Gemini-3.1-Pro em aproximadamente três a seis meses, de acordo com o relatório técnico da DeepSeek.
Onde o V4-Pro lidera:
- Codeforces (programação competitiva): o V4-Pro marcou 3.206, ficando cerca do 23.º entre participantes humanos reais em concursos
- Apex Shortlist (problemas de matemática e STEM curados): taxa de aprovação de 90,2% face aos 85,9% do Opus 4.6 e aos 78,1% do GPT-5.4
- SWE-Verified (resolução de issues no GitHub): 80,6%, correspondendo ao Claude Opus 4.6
Onde o V4-Pro fica atrás:
- MMLU-Pro (multitarefa): Gemini-3.1-Pro a 91,0% face ao V4-Pro a 87,5%
- GPQA Diamond (conhecimento especializado): Gemini a 94,3 face ao V4-Pro a 90,1
- Humanity’s Last Exam (nível de licenciatura): Gemini-3.1-Pro a 44,4% face ao V4-Pro a 37,7%
Em tarefas de longo contexto, o V4-Pro lidera modelos open-source e supera o Gemini-3.1-Pro em CorpusQA (simulando análise real de documentos com um milhão de tokens), mas perde para o Claude Opus 4.6 no MRCR, que mede a recuperação de informação específica enterrada profundamente em texto longo.
Capacidades de Agente e de Código
O V4-Pro pode correr no Claude Code, OpenCode e outras ferramentas de coding de IA. De acordo com um inquérito interno da DeepSeek a 85 programadores que usaram o V4-Pro como o seu agente de coding principal, 52% disseram que estava pronto para ser o seu modelo por defeito, 39% inclinaram-se para “sim” e menos de 9% disseram “não”. Testes internos da DeepSeek indicaram que o V4-Pro supera o Claude Sonnet e aproxima o Claude Opus 4.5 em tarefas de coding agentic.
A Artificial Analysis classificou o V4-Pro em primeiro lugar entre todos os modelos open-weight no GDPval-AA, um benchmark que testa trabalho de conhecimento economicamente valioso em finanças, jurídicos e tarefas de investigação. O V4-Pro-Max obteve 1.554 Elo, à frente do GLM-5.1 (1.535) e do MiniMax’s M2.7 (1.514). O Claude Opus 4.6 obtém 1.619 no mesmo benchmark.
O V4 introduz “interleaved thinking”, que retém toda a cadeia de pensamento completa através de chamadas de ferramentas. Em modelos anteriores, quando um agente fazia múltiplas chamadas a ferramentas — como procurar na web, executar código e depois procurar novamente — o contexto de raciocínio do modelo era limpo entre rondas. O V4 mantém continuidade de raciocínio entre passos, evitando perda de contexto em workflows automatizados complexos.
Cenário Competitivo e Contexto de Preços
O lançamento da V4 chega num momento de atividade significativa no espaço de IA. A Anthropic enviou o Claude Opus 4.7 a 16 de abril de 2026. O GPT-5.5 da OpenAI foi lançado a 23 de abril de 2026, com o GPT-5.5 Pro com preços de $30 por milhão de tokens de entrada$180 e (por milhão de tokens de saída). O GPT-5.5 supera o V4-Pro no Terminal Bench 2.0 (82,7%) face aos 70,0%$1 , que testa workflows complexos de agentes de linha de comandos.
A Xiaomi lançou o MiMo V2.5 Pro a 22 de abril de 2026, oferecendo capacidades multimodais completas $3 imagem, áudio, vídeo( a )entrada e saída por milhão de tokens. A Tencent lançou o Hy3 no mesmo dia do GPT-5.5.
Para perspectiva de preços: o CEO da Cline, Saoud Rizwan, observou que, se a Uber tivesse usado a DeepSeek em vez do Claude, o seu orçamento de IA de 2026 — alegadamente suficiente para quatro meses de uso — teria durado sete anos.
![Pricing comparison and Uber budget analysis]https://img-cdn.gateio.im/social/moments-0ee5a4bf95-cbc5686e31-8b7abd-badf29
Deployment e Disponibilidade
Tanto o V4-Pro como o V4-Flash têm licença MIT e estão disponíveis no Hugging Face. Os modelos são apenas de texto por agora; a DeepSeek afirmou que está a trabalhar em capacidades multimodais. Ambos os modelos podem ser executados gratuitamente em hardware local ou personalizados com base nas necessidades da empresa.
Os endpoints existentes deepseek-chat e deepseek-reasoner da DeepSeek já encaminham para o V4-Flash nos modos non-thinking e thinking, respetivamente. Os antigos endpoints deepseek-chat e deepseek-reasoner serão descontinuados a 24 de julho de 2026.
A DeepSeek treinou parcialmente o V4 com chips Huawei Ascend, contornando restrições de exportação dos EUA. A empresa afirmou que, quando 950 novos supernodes ficarem online mais tarde em 2026, o preço já baixo do modelo Pro irá cair ainda mais.
Implicações Práticas
Para empresas, a estrutura de preços pode alterar os cálculos de custo-benefício. Um modelo que lidera benchmarks open-source a $1.74 por milhão de tokens de entrada torna o processamento de grandes volumes de documentos, revisão jurídica e pipelines de geração de código substancialmente mais baratos do que há seis meses. O contexto de um milhão de tokens permite que bases de código inteiras ou submissões regulatórias sejam processadas numa única requisição em vez de serem fatiadas em múltiplas chamadas.
Para programadores e criadores independentes, o V4-Flash é a consideração principal. A $0.14 de entrada e $0.28 de saída por milhão de tokens, é mais barato do que modelos considerados opções “budget” há um ano, enquanto lida com a maioria das tarefas que a versão Pro gere.