DeepSeek a publié des versions bêta de DeepSeek-V4-Pro et DeepSeek-V4-Flash le 24 avril 2026, deux modèles open-weight avec une fenêtre de contexte d’un million de tokens et des prix nettement inférieurs à des alternatives occidentales comparables. Le modèle V4-Pro coûte 1,74 $ par million de tokens d’entrée et 3,48 $ par million de tokens de sortie — soit environ 1/20e du prix de Claude Opus 4.7 et 98% de moins que GPT-5.5 Pro, selon les spécifications officielles de l’entreprise.
Architecture du modèle et échelle
DeepSeek-V4-Pro présente 1,6 trillion de paramètres totaux, ce qui en fait le plus grand modèle open-source du marché des LLM à ce jour. Cependant, seuls 49 milliards de paramètres s’activent à chaque passe d’inférence, en utilisant ce que DeepSeek appelle l’approche Mixture-of-Experts, affinée depuis la V3. Cette conception permet au modèle complet de rester en veille, tandis que seules des portions pertinentes s’activent pour chaque requête donnée, réduisant les coûts de calcul tout en maintenant la capacité de connaissance.
DeepSeek-V4-Flash fonctionne à une échelle plus réduite avec 284 milliards de paramètres totaux et 13 milliards de paramètres actifs. D’après les benchmarks de DeepSeek, il « obtient des performances de raisonnement comparables à la version Pro lorsqu’il reçoit un budget de réflexion plus important ».
Les deux modèles prennent en charge un million de tokens de contexte en tant que fonctionnalité standard — environ 750 000 mots, ou à peu près l’ensemble de la trilogie « Le Seigneur des Anneaux » plus du texte supplémentaire.
Innovation technique : mécanismes d’attention à grande échelle
DeepSeek a résolu le problème de passage à l’échelle computationnelle inhérent au traitement des contextes longs en inventant deux nouveaux types d’attention, comme détaillé dans l’article technique de l’entreprise disponible sur GitHub.
Les mécanismes d’attention standard de l’IA font face à un problème de passage à l’échelle brutal : à chaque fois que la longueur du contexte double, le coût de calcul augmente d’environ quatre fois. La solution de DeepSeek repose sur deux approches complémentaires :
Compressed Sparse Attention fonctionne en deux étapes. Elle compresse d’abord des groupes de tokens — par exemple, chaque 4 tokens — en une seule entrée. Puis, au lieu d’accéder à toutes les entrées compressées, elle utilise un « Lightning Indexer » pour sélectionner uniquement les résultats les plus pertinents pour toute requête donnée. Cela réduit l’envergure de l’attention du modèle d’un million de tokens à un ensemble beaucoup plus petit de chunks importants.
Heavily Compressed Attention adopte une approche plus agressive : elle réduit chaque 128 tokens en une seule entrée sans sélection clairsemée. Bien que cela fasse perdre des détails fins, cela fournit une vue globale extrêmement peu coûteuse. Les deux types d’attention fonctionnent sur des couches alternées, permettant au modèle de conserver à la fois la précision et la vue d’ensemble.
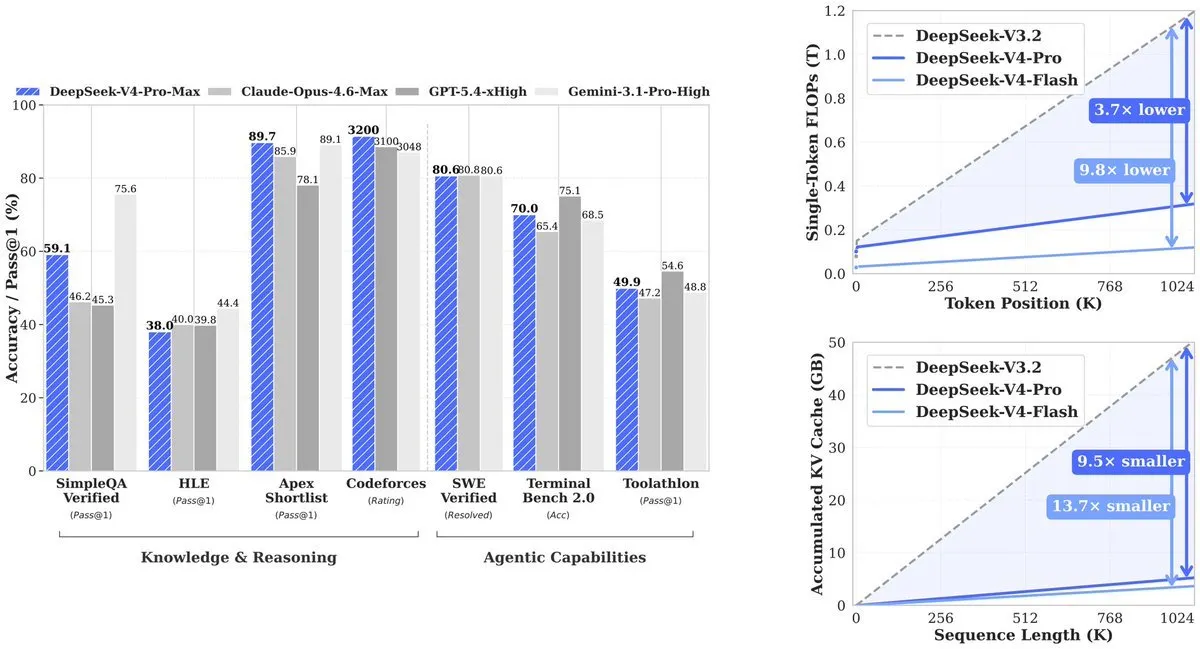
Le résultat : V4-Pro utilise 27% de la puissance de calcul de l’ordinateur de son prédécesseur (V3.2). Le KV cache — la mémoire nécessaire pour suivre le contexte — tombe à 10% de V3.2. V4-Flash pousse encore l’efficacité : 10% de calcul et 7% de mémoire par rapport à V3.2.
Performance aux benchmarks et position concurrentielle
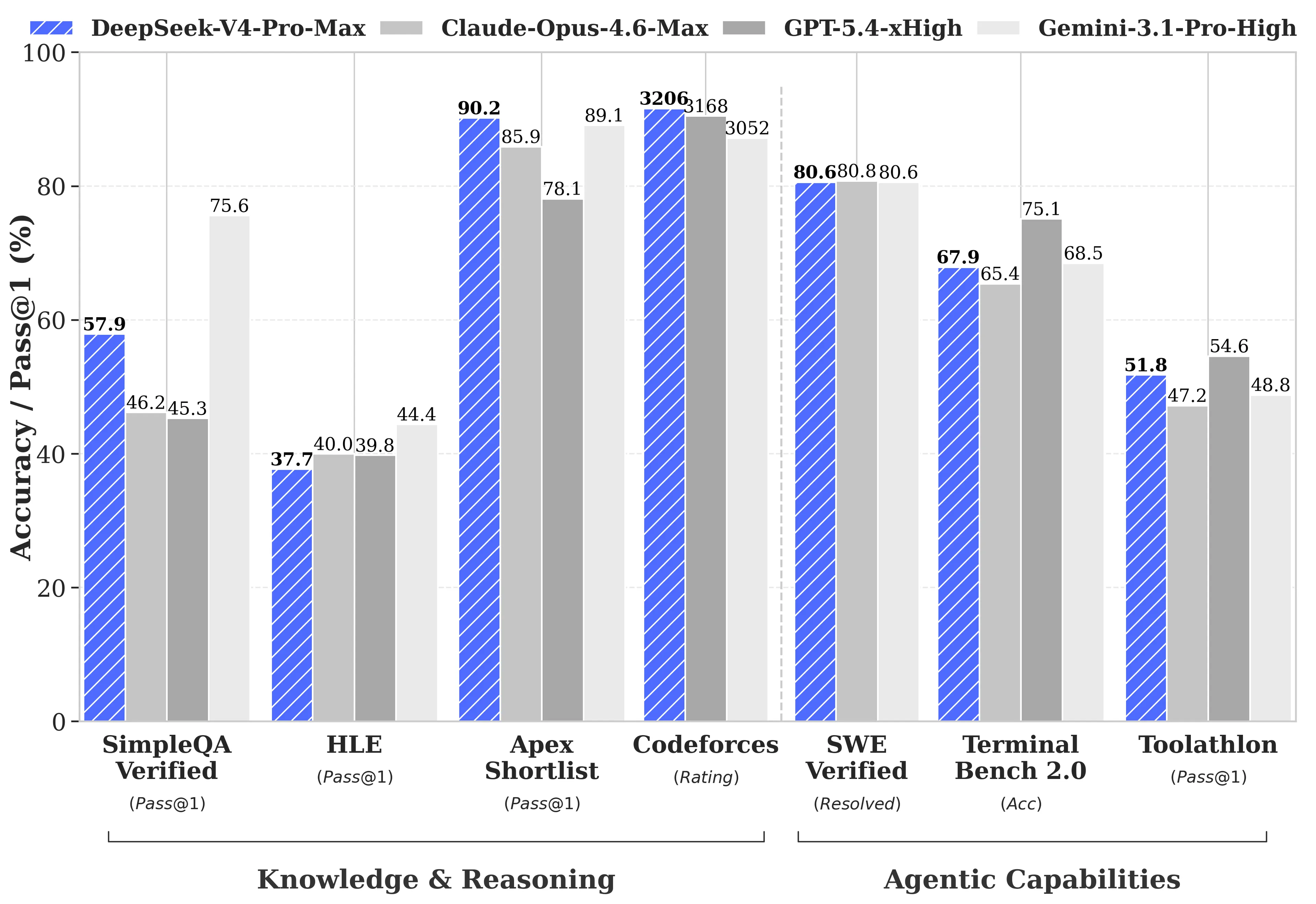
DeepSeek a publié des comparaisons de benchmarks exhaustives par rapport à GPT-5.4 et Gemini-3.1-Pro, y compris des domaines où V4-Pro est en retrait sur ses concurrents. Sur les tâches de raisonnement, le raisonnement de V4-Pro accuse un retard d’environ trois à six mois par rapport à GPT-5.4 et Gemini-3.1-Pro, selon le rapport technique de DeepSeek.
Là où V4-Pro est en avance :
- Codeforces (programmation compétitive): V4-Pro a obtenu 3 206 points, se classant autour de la 23e place parmi les participants humains aux concours réels
- Apex Shortlist (problèmes de mathématiques et STEM sélectionnés): taux de réussite de 90,2% contre 85,9% pour Opus 4.6 et 78,1% pour GPT-5.4
- SWE-Verified (résolution d’issues GitHub): 80,6%, correspondant à Claude Opus 4.6
Là où V4-Pro est en retrait :
- MMLU-Pro (multitâche): Gemini-3.1-Pro à 91,0% contre V4-Pro à 87,5%
- GPQA Diamond (connaissances d’expert): Gemini à 94,3 contre V4-Pro à 90,1
- Humanity’s Last Exam (niveau master): Gemini-3.1-Pro à 44,4% contre V4-Pro à 37,7%
Sur les tâches à long contexte, V4-Pro est en avance sur les modèles open-source et bat Gemini-3.1-Pro sur CorpusQA (simulant une analyse réaliste de documents à un million de tokens), mais perd face à Claude Opus 4.6 sur MRCR, qui mesure la récupération d’informations spécifiques enfouies profondément dans du texte long.
Capacités agentiques et de codage
V4-Pro peut fonctionner dans Claude Code, OpenCode et d’autres outils de codage IA. D’après l’enquête interne de DeepSeek auprès de 85 développeurs ayant utilisé V4-Pro comme agent de codage principal, 52% ont déclaré qu’il était prêt à être leur modèle par défaut, 39% ont penché pour oui, et moins de 9% ont dit non. Les tests internes de DeepSeek ont indiqué que V4-Pro surpasse Claude Sonnet et se rapproche de Claude Opus 4.5 sur les tâches de codage agentique.
Artificial Analysis a classé V4-Pro premier parmi tous les modèles open-weight sur GDPval-AA, un benchmark testant un travail de connaissance économiquement rentable sur des tâches de finance, de droit et de recherche. V4-Pro-Max a obtenu 1 554 Elo, devant GLM-5.1 (1 535) et M2.7 de MiniMax (1 514). Claude Opus 4.6 obtient 1 619 sur le même benchmark.
V4 introduit la « réflexion entrelacée », qui conserve toute la chaîne de pensée complète sur les appels d’outils. Dans les modèles précédents, lorsqu’un agent effectuait plusieurs appels d’outils — comme rechercher sur le web, exécuter du code, puis rechercher à nouveau — le contexte de raisonnement du modèle était vidé entre les tours. V4 maintient la continuité du raisonnement à travers les étapes, empêchant la perte de contexte dans des workflows automatisés complexes.
Contexte concurrentiel et de tarification
La sortie de V4 arrive dans un contexte de forte activité dans le secteur de l’IA. Anthropic a expédié Claude Opus 4.7 le 16 avril 2026. OpenAI a lancé GPT-5.5 le 23 avril 2026, avec GPT-5.5 Pro tarifé à $30 par million de tokens d’entrée$180 et (par million de tokens de sortie). GPT-5.5 bat V4-Pro sur Terminal Bench 2.0 (82,7% contre 70,0%), qui teste des workflows complexes d’agents en ligne de commande.
Xiaomi a publié MiMo V2.5 Pro le 22 avril 2026, offrant des capacités multimodales complètes $1 image, audio, vidéo$3 à (par million de tokens d’entrée) et par million de tokens de sortie. Tencent a publié Hy3 le même jour que GPT-5.5.
Pour mettre la tarification en perspective : le PDG de Cline, Saoud Rizwan, a noté que si Uber avait utilisé DeepSeek au lieu de Claude, son budget IA 2026 — prétendument suffisant pour quatre mois d’utilisation — aurait duré sept ans.
![Pricing comparison and Uber budget analysis]https://img-cdn.gateio.im/social/moments-0ee5a4bf95-cbc5686e31-8b7abd-badf29
Déploiement et disponibilité
Les deux, V4-Pro et V4-Flash, sont sous licence MIT et disponibles sur Hugging Face. Pour l’instant, les modèles sont uniquement textuels ; DeepSeek a indiqué qu’il travaille sur des capacités multimodales. Les deux modèles peuvent être utilisés gratuitement sur du matériel local ou personnalisés selon les besoins de l’entreprise.
Les endpoints existants de deepseek-chat et deepseek-reasoner de DeepSeek acheminent déjà respectivement V4-Flash en modes non-thinking et thinking. Les anciens endpoints deepseek-chat et deepseek-reasoner seront retirés le 24 juillet 2026.
DeepSeek a entraîné une partie de V4 sur des puces Huawei Ascend, en contournant les restrictions d’exportation américaines. L’entreprise a déclaré que lorsque 950 nouveaux supernodes seront mis en ligne plus tard en 2026, le prix déjà bas du modèle Pro baissera encore.
Implications pratiques
Pour les entreprises, la structure tarifaire pourrait modifier les calculs coût-bénéfice. Un modèle en tête des benchmarks open-source à 1,74 $ par million de tokens d’entrée rend le traitement à grande échelle de documents, la revue juridique et les pipelines de génération de code substantiellement moins coûteux qu’il y a six mois. Le contexte d’un million de tokens permet de traiter l’ensemble de bases de code ou de dépôts réglementaires en une seule requête plutôt que de les découper en plusieurs appels.
Pour les développeurs et les créateurs indépendants, V4-Flash est la considération principale. À 0,14 $ en entrée et 0,28 $ en sortie par million de tokens, il est moins cher que des modèles considérés comme options budget il y a un an, tout en gérant la plupart des tâches que le modèle Pro gère.