BlockSec: AI 尚未能取代人類進行智能合約審計
Tap Chi Bitcoin
保安公司 BlockSec 已重新測試由 OpenAI 和 Paradigm 開發的名為 EVMBench 的智能合約審計評估標準。結果顯示,當面對實際的攻擊場景時,AI 機器人表現明顯較差。
研究團隊擴展了測試環境,加入更多模型配置,同時新增近期發生的安全事件——這些數據在 AI 模型的訓練資料中從未出現過。
儘管 AI 仍無法取代安全專家,但報告強調,機器智慧可以自然地作為人類代碼審查的輔助角色。
EVMBench 初步結果可能過於樂觀
之前的 EVMBench 評估了智能合約的安全任務,如漏洞檢測、修復和攻擊,結果被認為非常令人印象深刻。根據報告,AI 能夠利用 72% 的漏洞,並偵測約 45% 的缺陷,這些數據來自從 Code4rena 的審計中挑選的 120 個樣本。
然而,BlockSec 認為最初的測試條件可能導致結果偏差。共同創始人周雅進表示,當他們用更多配置和 22 個實際攻擊事件重新測試時,AI 的成功利用率為 0%。
擴展配置並排除“數據污染”
研究將模型配置數量從 14 增加到 26,通過靈活組合多個“腳手架”與不同的機器人,而不僅限於各供應商的生態系統。研究團隊指出,舊的方法難以區分模型性能是來自模型本身還是架構優勢。
此外,BlockSec 也質疑“數據污染”現象,因為 EVMBench 使用了已公開的漏洞——這些漏洞可能已包含在 AI 的訓練資料中。為此,團隊測試了 2026 年 2 月之後發生的 22 個安全事件,這些事件超出了模型的“知識窗口”。
AI 在實戰攻擊中完全失敗
最令人關注的結果是:在 110 對 agent 與漏洞的測試中(5 個 agent 面對 22 個情境),沒有一例成功完成完整攻擊。這表明,即使是目前最先進的 AI,也距離能進行實際攻擊還很遙遠。
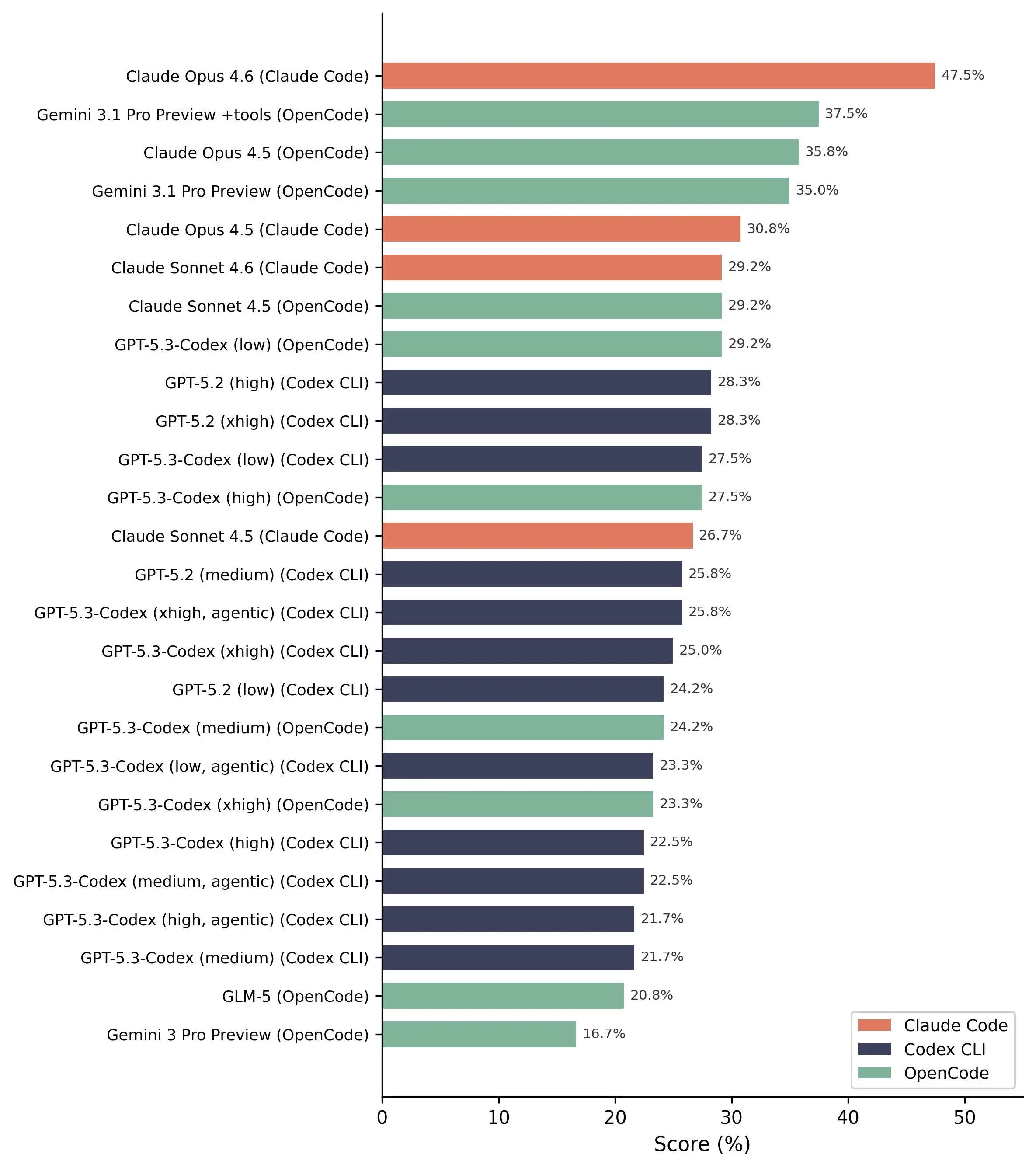
不過,在漏洞偵測方面,結果仍較為積極。Claude Opus 4.6 模型在實際中能偵測出 13/20 個漏洞,表現最佳。
常見且熟悉的漏洞,AI 輕鬆偵測,但較複雜的案例幾乎完全漏掉。
未來是 AI 與人類的合作
研究結論指出,AI 目前尚無法取代人類進行安全審計,更重要的是雙方如何有效協作。
AI 在覆蓋範圍和大規模掃描能力方面具有優勢,而人類則在深度分析、協議理解和對抗推理方面更勝一籌。這兩者應相輔相成。
BlockSec 表示,正確的方向不是用 AI 取代人類,而是建立雙方合作的模型,以實現更全面的審計效果。
石山
免責聲明:本頁面資訊可能來自第三方,不代表 Gate 的觀點或意見。頁面顯示的內容僅供參考,不構成任何財務、投資或法律建議。Gate 對資訊的準確性、完整性不作保證,對因使用本資訊而產生的任何損失不承擔責任。虛擬資產投資屬高風險行為,價格波動劇烈,您可能損失全部投資本金。請充分了解相關風險,並根據自身財務狀況和風險承受能力謹慎決策。具體內容詳見聲明。
留言
0/400
暫無留言