Turning Stone into Gold: How 43 Years of Tennis Data Became a Money-Printing Machine in Prediction Markets?
PANews

作者:Phosphen
編譯;Gans 甘斯,Bagel預測市場觀察
這個男人收集了過去43年所有職業網球比賽的數據,全部輸入一個機器學習模型,然後只問了一個問題:你能預測誰會贏嗎?
模型只回答了一個字:能。
隨後,它在今年的澳大利亞網球公開賽上,正確預測了116場比賽中的99場,準確率高達85%!
這是模型訓練中從未見過的賽事,它竟然連最終冠軍贏得的每一場比賽都預測對了。

這一切只用了一台筆記本電腦、免費的數據和開源的程式碼,出自 @theGreenCoding 之手。
接下來,我將完整拆解這個點石成金的專案,從原始數據到最終預測成功。這將是你見過的最令人印象深刻的AI + 預測成功案例。
起點:一個資料夾裡的43年網球數據
故事要從一份堪稱「體育數據聖杯」的資料集說起。
這份資料集涵蓋了1985年至2024年,ATP(男子職業網球聯盟)的每一場職業賽事記錄。
破發點、雙誤、正手、反手、球員身高、年齡、排名、歷史交手記錄、比賽場地……ATP有史以來追蹤過的每一項逐分統計數據,應有盡有。
四十年的CSV檔案,全部裝在一個資料夾裡。
當他打開完整資料集時,電腦直接崩潰了。
但他沒有放棄。針對資料集中的95,491場比賽,他額外計算了大量衍生特徵:
- 兩位球員的歷史交手記錄
- 年齡差、身高差
- 最近10場、25場、50場、100場比賽的勝率
- 一發得分率差值
- 破發點挽救率差值
- 一套從國際象棋借鑑的自訂ELO評分系統(關鍵點)
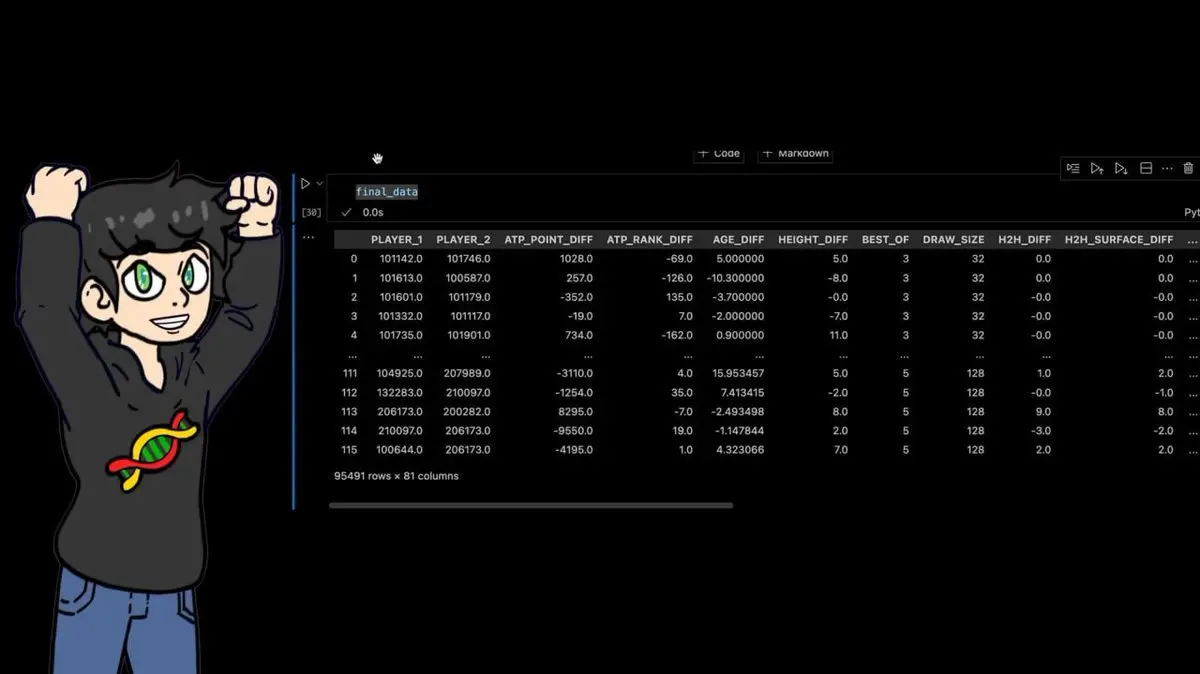
最終資料集:95,491行 × 81列。
過去四十年的每一場職業網球賽事,配上數十個手工計算的特徵。
第二步:從泰坦尼克號借鑑的演算法

在將資料輸入分類器之前,他決定先徹底理解演算法的運作原理。為此,他用 numpy 從零手寫了一個決策樹。
決策樹的工作方式類似推理遊戲——透過一系列問題逐步逼近答案。
為了說明這個概念,他選了一個完全不同的資料集:泰坦尼克號。
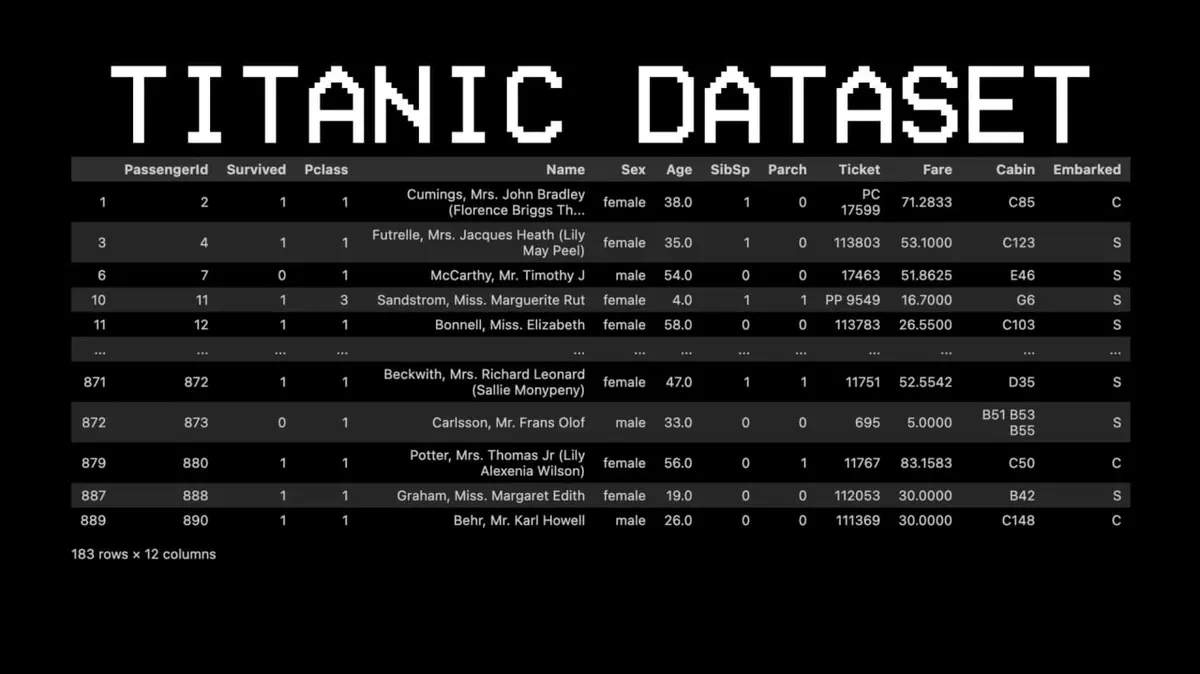
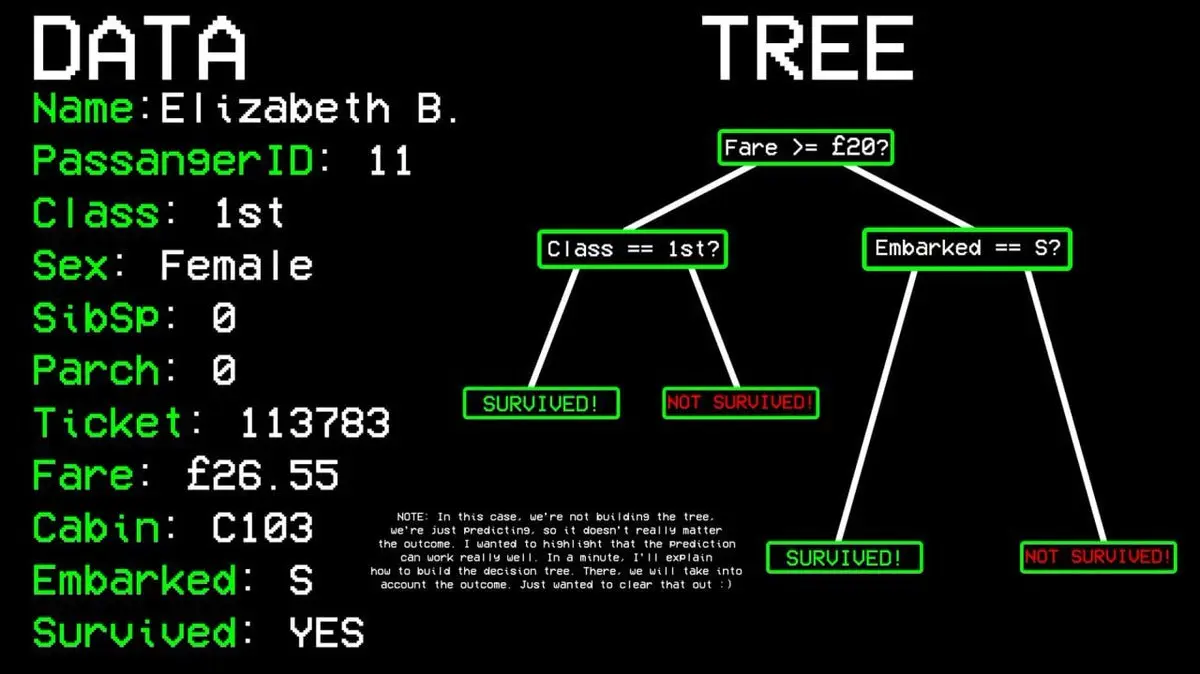
舉個例子:11號乘客是否存活?
- 問題一:TA 在頭等艙嗎?→ 是的。
- 問題二:TA 是女性嗎?→ 是的。
- 預測結果:存活。
演算法如何決定問哪些問題?
它從所有資料出發,找到最能區分「存活」和「未存活」的單一變數。在泰坦尼克號資料中,答案是艙位等級。頭等艙乘客走一邊,其他人走另一邊。
但頭等艙也有人遇難,仍存在「不純度」。演算法繼續尋找下一個最佳分割點,性別。頭等艙女性全部存活,形成「純節點」,分支到此終止。
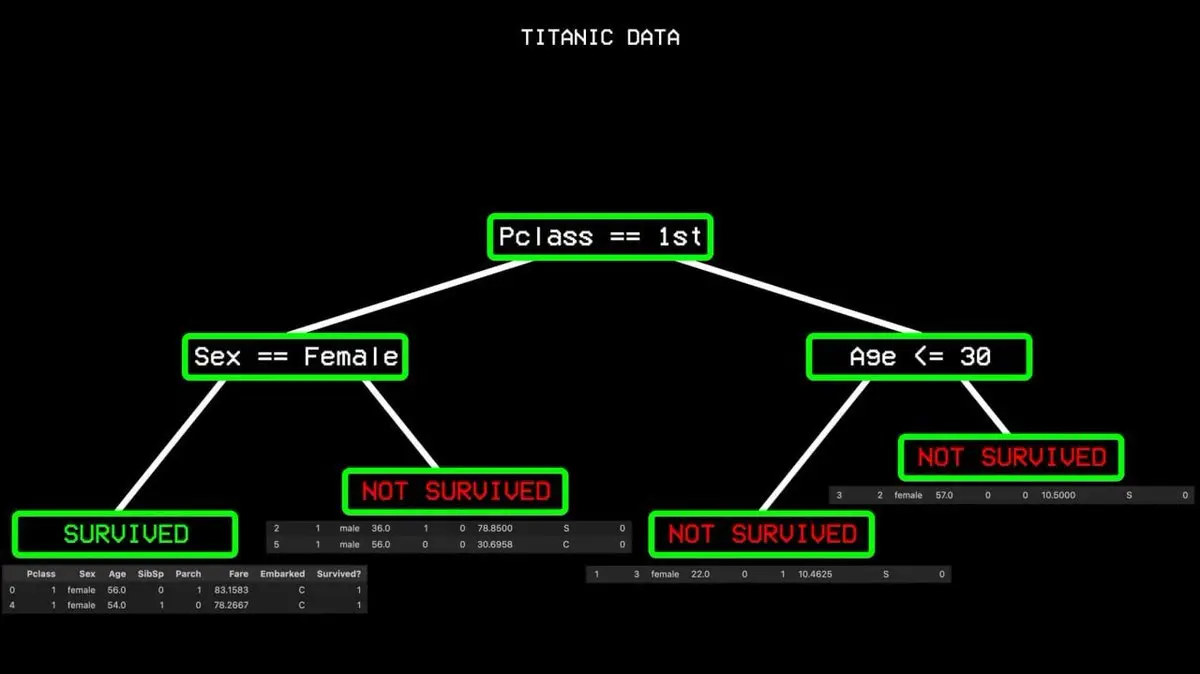
不斷重複這個過程,直到建立出一棵覆蓋所有情況的完整決策樹。
他的 numpy 手寫版在小資料集上表現良好,但用在 95,000 條網球比賽資料上時,速度慢得令人崩潰。於是在正式訓練階段,他切換到 sklearn 的優化版本,邏輯相同,但快得多。
第三步:找到決定勝負的關鍵變數
在訓練模型之前,他先將所有變數兩兩繪製成一張巨大的散點圖矩陣(SNS pairplot),尋找能夠區分勝者與敗者的規律。

大多數特徵都是噪聲。球員ID顯然沒用。勝率差值雖然呈現出一些規律,但不夠明顯,無法支撐可靠的分類器。
只有一個變數遠超其他:ELO差值(ELO_DIFF)。
ELO_DIFF 和 ELO_SURFACE_DIFF 的散點圖清楚展現了兩個類別之間的分離程度,其他任何特徵都無法與之相比。
這一發現促使他建立了整個專案最核心的部分。
第四步:將國際象棋評分系統引入網球
ELO 是一套評估選手技術水平的方法,最早應用於國際象棋。目前國際象棋世界第一 Magnus Carlsen 的評分是 2833 分。

他決定將這套系統應用到網球上:
- 每位球員起始評分:1500 分
- 贏球:評分上升;輸球:評分下降
核心機制:得失分多少取決於與對手的評分差距,擊敗高評分對手,得分更多;輸給低評分對手,扣分更重。
他用 2023 年溫布爾登決賽演示這套公式:卡洛斯·阿爾卡拉斯(評分 2063)對陣諾瓦克·德約科維奇(評分 2120),阿爾卡拉斯逆轉奪冠。

代入公式計算:阿爾卡拉斯 +14 分,德約科維奇 -14 分。
計算雖然簡單,但應用在 43 年歷史資料上時,威力驚人。
第五步:三巨頭統治力的可視化證明
他將費德勒整個職業生涯的 ELO 評分繪製成曲線,從初登職業賽場到退役,每一場比賽都清楚記錄。
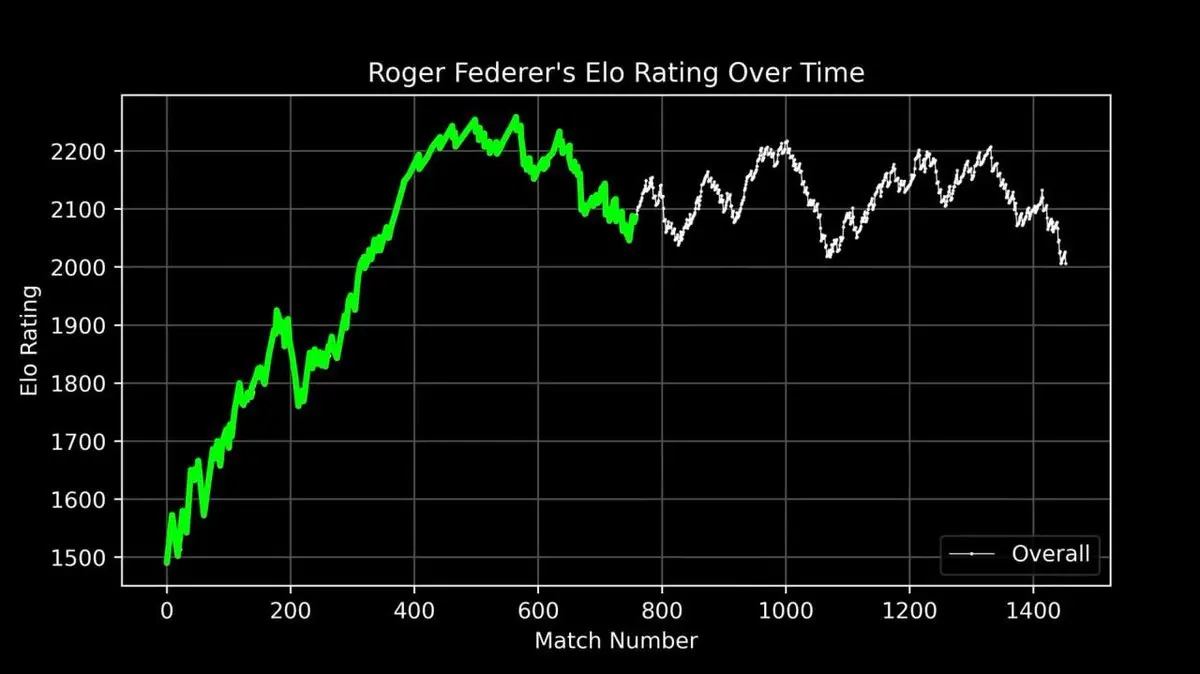
這條曲線完整展現了一段傳奇:早期的快速攀升、巔峰期(約第 400 場比賽前後)的絕對統治,以及職業生涯後期的波動起伏。
但真正震撼的,是將費德勒與 1985 年以來所有 ATP 球員放在同一張圖上時:
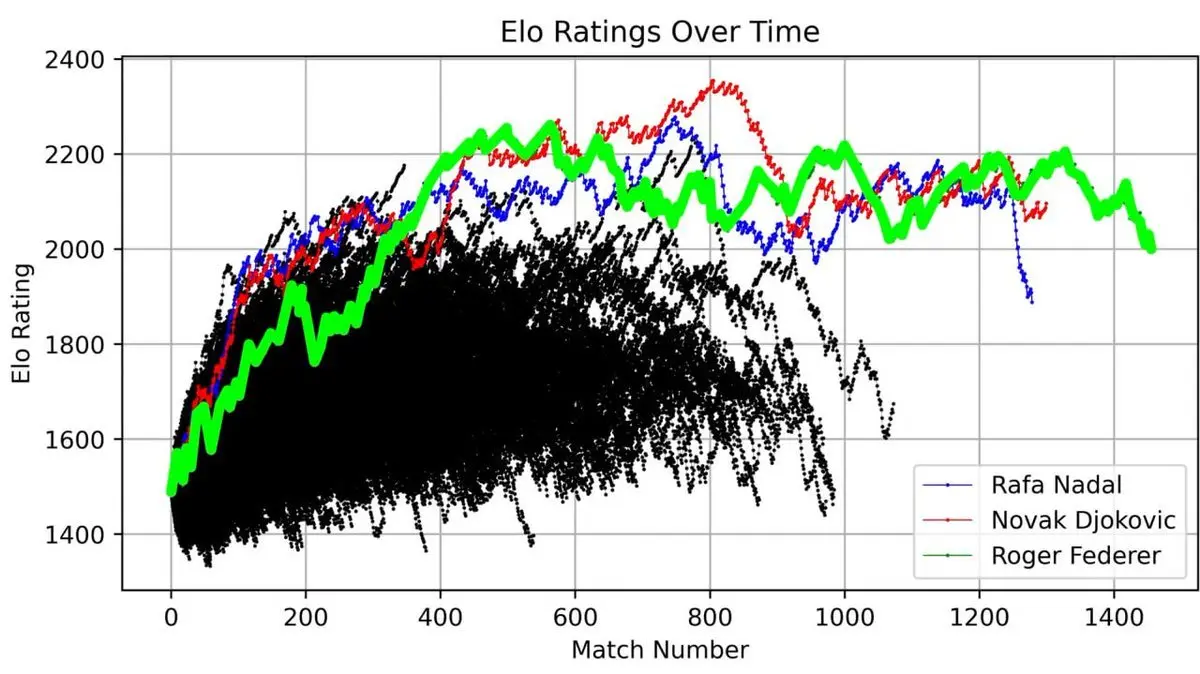
三條曲線高高矗立,遠超其他所有人——費德勒(綠)、納達爾(藍)、德約科維奇(紅)。
「大滿貫三巨頭」不只是一個稱號。當你將 40 年的比賽數據可視化後會發現,這種統治力在數學上清晰可見。
根據他的自訂 ELO 系統,當前世界第一是 雅尼克·辛納(2176 分),其次是德約科維奇(2096 分)和阿爾卡拉斯(2003 分)。

記住辛納排名第一這一點,這在後面至關重要。
第六步:場地是改變一切的變數
網球比賽的場地類型會徹底改變這項運動的面貌:
- 紅土:慢速,彈跳高
- 草地:快速,彈跳低
- 硬地:介於兩者之間
在某種場地呼風喚雨的球員,換個場地可能完全崩潰。
所以他為三種場地分別建立了 ELO 評分:紅土、草地、硬地。
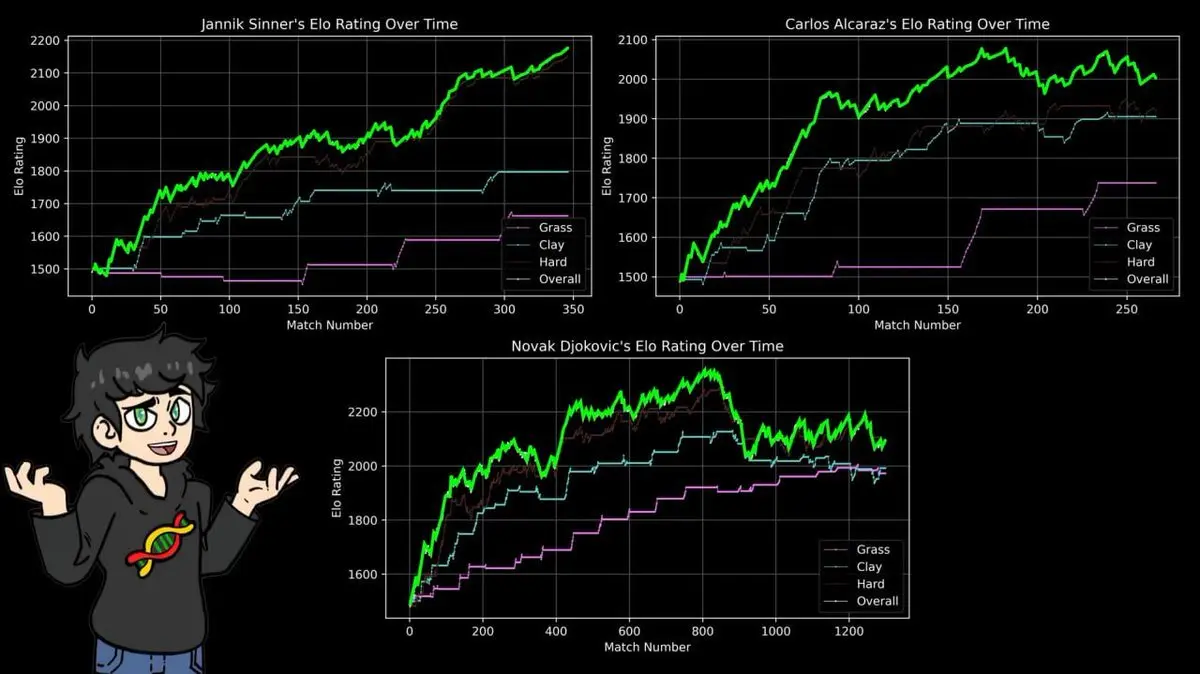
結果印證了每個網球迷心知肚明的事實,並用 43 年的數據作為佐證:
納達爾在紅土上的巔峰評分,超過了費德勒在草地上的最高分,超過了德約科維奇在硬地上的最高分,超過了任何人在任何場地的歷史最高峰。
14 座法網冠軍,在羅蘭加洛斯 112 勝 4 負。
ELO 公式不在乎敘事,不在乎名氣,它只處理勝負記錄。而它得出的結論,和四十年的體育新聞報導完全一致。
第七步:遇到天花板
資料準備完畢,ELO 系統搭建完成,他開始訓練分類器。這個過程完美展現了演算法選擇的重要性。
決策樹:準確率 74%
單棵決策樹在完整資料集上達到 74% 的準確率。聽起來不錯——直到你發現,單純用 ELO 差值預測勝者,就能達到 72%。
決策樹在他已經手動建好的評分系統基礎上,幾乎沒有帶來任何提升。
隨機森林:準確率 76%
單棵決策樹的問題在於「高方差」——它對訓練時恰好選到的資料子集過於敏感。標準解法是隨機森林:建立數十棵乃至上百棵決策樹,每棵用不同的隨機資料子集和特徵子集訓練,最後透過多數投票決定預測結果。

94 棵各不相同的決策樹,共同為每場比賽投票。

結果是 76%。有所提升,但他撞上了天花板。無論怎麼調整超參數、重新設計特徵、折騰資料,準確率就是過不了 77%。
第八步:突破天花板
接著他嘗試了XGBoost——他稱之為「隨機森林的類固醇版本」。
核心差別在於:隨機森林並行建樹後取平均,而XGBoost串行建樹——每棵新樹專門修正前面所有樹的錯誤。它引入了正則化防止過擬合,並刻意保持每棵樹的小規模,避免死記硬背訓練資料。
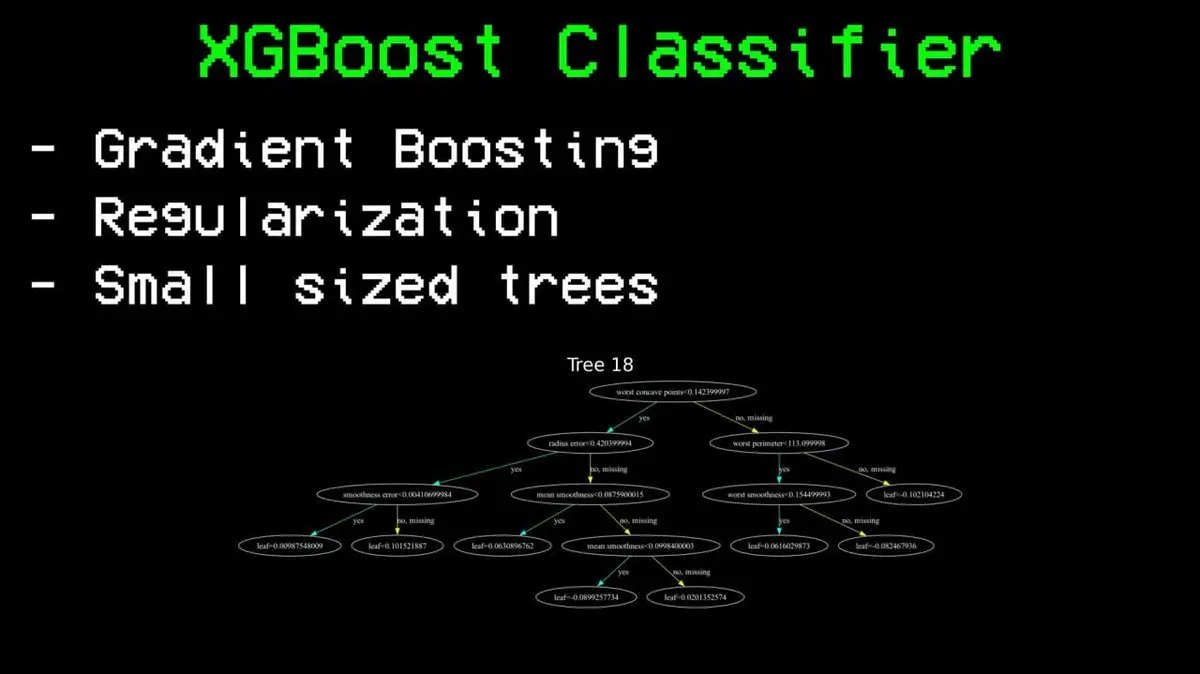
結果:準確率85%。
相比隨機森林76%的天花板,這是巨大的突破。同樣的資料,同樣的特徵,唯一改變的是演算法。
XGBoost同樣認為最重要的三個特徵是:ELO差值、場地專項ELO差值、整體ELO。這套從國際象棋借鑑來的評分系統,在81列特徵中被驗證為最強預測因子。
作為對比,他用同樣的資料訓練了一個神經網路,準確率83%。雖然不錯,但仍輸給XGBoost。在這個資料集上,基於樹的方法獲勝。
第九步:決戰時刻——2025 年澳大利亞網球公開賽
以上所有內容,都基於 2024 年 12 月之前的資料訓練。
2025 年 1 月的澳大利亞網球公開賽完全不在訓練集中,這使它成為完美的測試場:模型究竟掌握了網球的真正規律,還是只會記憶歷史模式?

他將完整的賽事簽表輸入模型,讓它預測每一場比賽。
結果:116 場比賽中正確預測 99 場,僅失誤 17 場。準確率 85.3%。
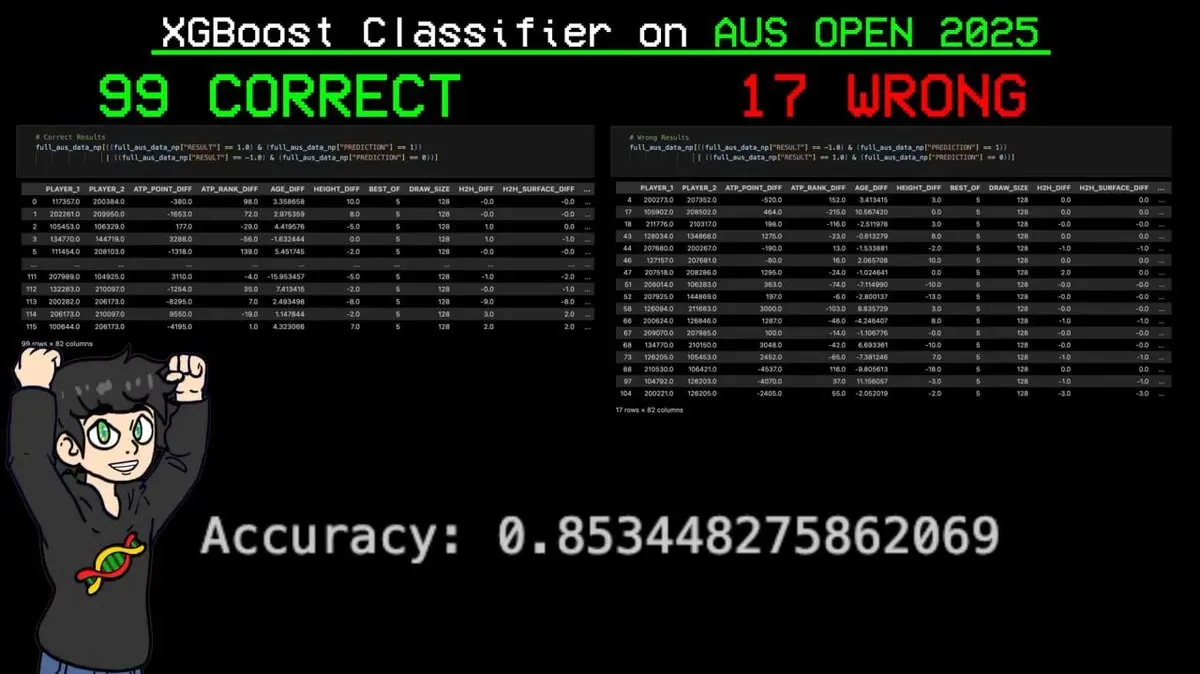
最關鍵的預測:模型準確預測了辛納(那個 ELO 系統排名全球第一的球員)在整屆賽事中的每一場勝利。
在第一顆球落地之前,AI 就預測出了大滿貫冠軍。
結語
一個人,一台筆記本電腦,沒有專有數據,沒有昂貴的基礎建設,沒有研究團隊——就構建出了一套職業網球預測模型,準確率高達 85%,並在賽事開始前預測出了大滿貫冠軍。
網球數據就在 GitHub 上,完全可復現。
創造奇蹟,從未像今天這樣觸手可及。
真正的差距不在資源,而在於你是否願意去做。
免責聲明:本頁面資訊可能來自第三方,不代表 Gate 的觀點或意見。頁面顯示的內容僅供參考,不構成任何財務、投資或法律建議。Gate 對資訊的準確性、完整性不作保證,對因使用本資訊而產生的任何損失不承擔責任。虛擬資產投資屬高風險行為,價格波動劇烈,您可能損失全部投資本金。請充分了解相關風險,並根據自身財務狀況和風險承受能力謹慎決策。具體內容詳見聲明。
留言
0/400
暫無留言