OpenAI 在上一個版本推出僅僅 4 天後,便推出 GPT-5.4,隨著「QuitGPT」的出走潮逐漸升溫
Decrypt
簡要
- OpenAI 在越來越多的 QuitGPT 反彈聲浪中推出 GPT-5.4,原因是其與五角大廈的 AI 合約。
- GPT-5.4 增加了 100 萬個令牌的上下文窗口、更強的推理能力以及代理能力。
- 企業用戶受益最大,因為 GPT-5.4 提供更快的 AI 代理,使用更少的令牌。
OpenAI 於星期四開始推出其迄今為止最強大的模型 GPT-5.4,試圖控制一場公關危機,該危機已導致約 250 萬用戶採取行動反對公司,無論是取消訂閱還是在社交媒體上分享抵制行動。 所謂的 QuitGPT 運動在 OpenAI 公布與美國國防部的合作協議數小時後爆發,該公司在 Anthropic 公開退出同一合約後,迅速宣布合作,這使得 Claude 的製造商成為特朗普總統及其他政府官員公開批評的對象。 Anthropic 的主要問題在於:國防部拒絕加入明確禁止部署自主武器和對美國公民進行大規模監控的條款。
然而,OpenAI 還是接受了這筆交易。CEO 山姆·奧特曼(Sam Altman)一直在回應有關公司聲稱的安全紅線與合約實際內容之間差距的問題,他需要這些用戶回來。 於是 GPT-5.4 出現了……就在 GPT-5.3 推出僅兩天後。
新模型將推理、編碼和代理能力整合到一個版本中。它還具有一百萬令牌的上下文能力,讓用戶在單次會話中處理大量資訊時擁有更大的自由。 從數據來看,數字表現令人振奮。在 GDPval——一個測試 44 個職業知識工作的基準測試中——GPT-5.4 在 83.0% 的比較中與行業專家持平或超越,較 GPT-5.2 的 70.9% 有明顯提升。在電腦操作方面,GPT-5.4 在 OSWorld-Verified 測試中成功率達 75.0%,而 GPT-5.2 為 47.3%,並且超越了人類基準的 72.4%。在深網研究測試 BrowseComp 中,它比 GPT-5.2 提升了 17 個百分點。100 萬令牌的上下文窗口和中途引導功能(允許用戶在模型思考時重新引導)也是其亮點功能。 這些功能節省了時間和計算資源,避免在出現錯誤時必須丟棄所有先前生成的令牌。
誰將從 GPT 5.4 中受益? 值得注意的是,一些基準測試主要比較 GPT-5.4——且大多數情況下,推理設定為超高努力(免費和 Plus 用戶無法享受)——與 GPT-5.2,完全跳過了 GPT-5.3。 對於已經使用 GPT-5.3 的用戶來說,幾個提升可能感覺更像是漸進式的,而非數據圖表所顯示的巨大變化。
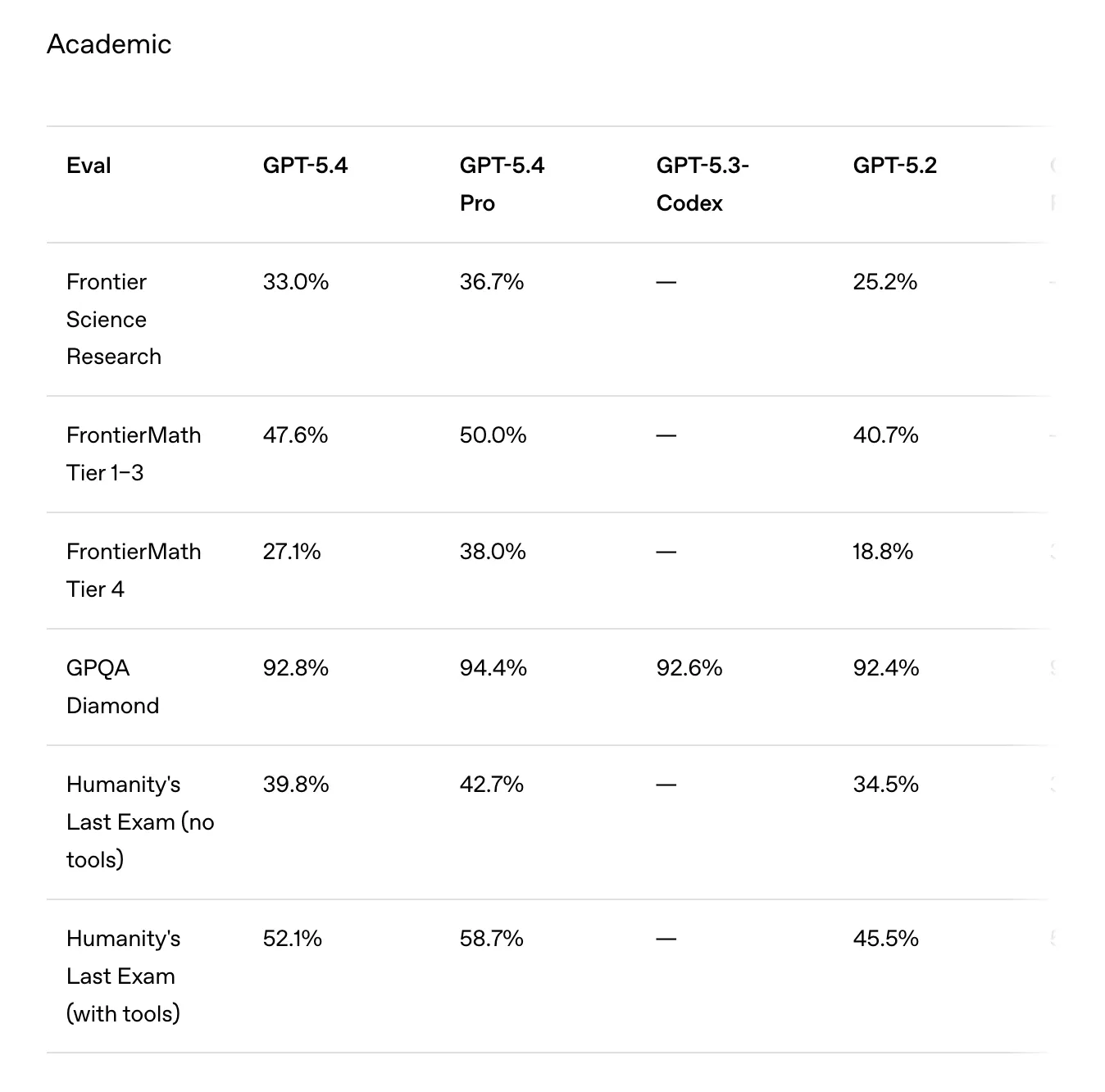
程式設計師最有理由保持期待:在 SWE-Bench Pro 測試中,從 GPT-5.3-Codex(56.8%)到 GPT-5.4(57.7%)的提升幾乎可以忽略不計。該模型還聲稱完成任務所需的令牌數明顯少於 GPT-5.2。 “GPT‑5.4 是我們迄今為止最具令牌效率的推理模型,與 GPT‑5.2 相比,使用的令牌顯著更少來解決問題”,OpenAI 表示。 不過,這方面的任何進步對於通過 API 使用 OpenAI 模型並按令牌收費的開發者來說都是好消息。一個具有高效思考鏈的模型可能以更低的成本提供相同的結果,而不是過度思考以確保得出正確結論的模型。 對於希望立即使用新模型的人來說,還有另一個問題:OpenAI 表示 GPT-5.4 今天將推出,但截至本文撰寫時尚未提供,可能正在逐步推出。對大多數用戶來說,最好的模型是 GPT 5.3,它只能用於即時回覆,提供不需過多努力的答案。 依賴思考——OpenAI 用來描述在複雜任務中進行長鏈推理的術語——的用戶仍在使用 GPT-5.2。換句話說,最有可能推動模型極限的用戶,往往也是最後一批獲得它的人。
最明顯的受益者是進行大量文件工作的企業用戶。在一個內部試算表建模基準測試中,GPT-5.4 的得分為 87.3%,而 GPT-5.2 為 68.4%。法律研究公司 Harvey 表示其在 BigLaw 基準測試中得分達 91%。主要運行代理的公司 Mainstay,管理 30,000 個房產稅務門戶網站,報告首次嘗試成功率達 95%,會話速度約快 3 倍,且使用的令牌少約 70%。 這種效率優勢可能對企業採購團隊來說很重要,但對於個人用戶來說,想要刪除帳戶的考慮則較難說服。
免責聲明:本頁面資訊可能來自第三方,不代表 Gate 的觀點或意見。頁面顯示的內容僅供參考,不構成任何財務、投資或法律建議。Gate 對資訊的準確性、完整性不作保證,對因使用本資訊而產生的任何損失不承擔責任。虛擬資產投資屬高風險行為,價格波動劇烈,您可能損失全部投資本金。請充分了解相關風險,並根據自身財務狀況和風險承受能力謹慎決策。具體內容詳見聲明。
留言
0/400
暫無留言