Thứ Ba, ngày 24 tháng 2. Washington, Lầu Năm Góc.
Giám đốc điều hành Anthropic, ông Dario Amodei, ngồi đối diện Bộ trưởng Quốc phòng Pete Hegseth. Các nguồn tin từ NPR và CNN mô tả cuộc gặp là “lịch sự”, dù nội dung thì hoàn toàn căng thẳng.
Hegseth đưa ra tối hậu thư: trước 17:01 thứ Sáu, Anthropic phải gỡ bỏ mọi hạn chế sử dụng quân sự đối với Claude và cho phép Lầu Năm Góc triển khai cho “mọi mục đích hợp pháp”, bao gồm cả nhắm mục tiêu vũ khí tự động và giám sát quy mô lớn trong nước.
Nếu không, hợp đồng trị giá 200 triệu USD sẽ bị hủy. Đạo luật Sản xuất Quốc phòng sẽ được áp dụng để trưng dụng bắt buộc. Anthropic sẽ bị xếp vào diện “rủi ro chuỗi cung ứng”—tương đương bị đưa vào danh sách đen cùng các đối thủ như Nga và Trung Quốc.
Ngay trong ngày, Anthropic công bố phiên bản thứ ba của Chính sách Mở rộng Trách nhiệm (RSP 3.0), âm thầm loại bỏ cam kết cốt lõi kể từ khi thành lập: không đào tạo các mô hình mạnh hơn nếu chưa có biện pháp an toàn.
Cũng trong ngày, Elon Musk đăng trên X: “Anthropic đã thực hiện hành vi trộm cắp dữ liệu đào tạo quy mô lớn—đây là sự thật.” Cùng lúc đó, Community Notes của X dẫn lại thông tin Anthropic đã trả 1,5 tỷ USD để dàn xếp các cáo buộc đào tạo Claude bằng sách vi phạm bản quyền.
Trong vòng bảy mươi hai giờ, công ty AI từng tuyên bố có “linh hồn” này bị gán ba nhãn: liệt sĩ an toàn, kẻ trộm sở hữu trí tuệ và kẻ phản bội Lầu Năm Góc.
Vậy thực chất Anthropic là gì?
Có lẽ là tất cả những điều đó.
Mệnh lệnh “Tuân thủ hoặc Rời đi” của Lầu Năm Góc
Lớp đầu tiên của câu chuyện khá rõ ràng.
Anthropic là công ty AI đầu tiên nhận được quyền truy cập thông tin mật từ Bộ Quốc phòng Hoa Kỳ, với hợp đồng ký vào mùa hè năm ngoái, giới hạn ở mức 200 triệu USD. Sau đó, OpenAI, Google và xAI cũng có hợp đồng quy mô tương tự.
Theo Al Jazeera, Claude đã được sử dụng trong một chiến dịch quân sự của Mỹ vào tháng 1 năm nay. Báo cáo cho biết nhiệm vụ này liên quan đến việc bắt cóc Tổng thống Venezuela Maduro.
Tuy nhiên, Anthropic đã vạch ra hai lằn ranh đỏ: không hỗ trợ nhắm mục tiêu vũ khí hoàn toàn tự động và không hỗ trợ giám sát quy mô lớn công dân Hoa Kỳ. Anthropic cho rằng AI chưa đủ tin cậy để kiểm soát vũ khí, và hiện chưa có luật nào điều chỉnh AI trong giám sát đại chúng.
Lầu Năm Góc không chấp nhận điều đó.
Tháng 10 năm ngoái, cố vấn AI của Nhà Trắng, David Sacks, công khai cáo buộc Anthropic trên X là “vũ khí hóa nỗi sợ để thao túng quy định”.
Các đối thủ đã chấp nhận nhượng bộ. OpenAI, Google và xAI đều đồng ý để quân đội sử dụng AI cho “mọi kịch bản hợp pháp”. Grok của Musk vừa được phê duyệt cho hệ thống mật trong tuần này.
Anthropic là thành trì cuối cùng.
Tính đến thời điểm hiện tại, Anthropic tuyên bố trong thông báo mới nhất rằng họ không có ý định nhượng bộ. Nhưng hạn chót 17:01 thứ Sáu đang đến gần.
Một cựu đầu mối liên lạc giữa Bộ Tư pháp và Lầu Năm Góc ẩn danh nói với CNN: “Làm sao có thể vừa coi một công ty là ‘rủi ro chuỗi cung ứng’ vừa ép buộc họ làm việc cho quân đội của mình?”
Đó là câu hỏi hay—nhưng không phải điều Lầu Năm Góc quan tâm. Điều họ quan tâm là nếu Anthropic không nhượng bộ, họ sẽ buộc tuân thủ hoặc loại Anthropic khỏi Washington.
“Tấn công chưng cất”: Lời cáo buộc công khai phản tác dụng
Ngày 23 tháng 2, Anthropic đăng một bài blog với ngôn từ gay gắt, cáo buộc ba công ty AI Trung Quốc—DeepSeek, Moonshot AI và MiniMax—thực hiện “tấn công chưng cất quy mô công nghiệp” đối với Claude.
Anthropic cho rằng các công ty này đã sử dụng 24.000 tài khoản giả để thực hiện hơn 16 triệu lượt tương tác với Claude, có hệ thống trích xuất các năng lực cốt lõi về lý luận tác vụ, sử dụng công cụ và lập trình.
Anthropic mô tả đây là mối đe dọa an ninh quốc gia, cho rằng các mô hình chưng cất “khó giữ được rào chắn an toàn” và có thể bị các chính phủ độc tài sử dụng cho tấn công mạng, phát tán thông tin sai lệch và giám sát đại chúng.
Câu chuyện được xây dựng rất đúng thời điểm và khéo léo.
Nó xuất hiện ngay sau khi chính quyền Trump nới lỏng kiểm soát xuất khẩu chip sang Trung Quốc—đúng lúc Anthropic cần chất liệu mới để vận động hành lang về xuất khẩu chip.
Nhưng Musk đáp trả: “Anthropic đã thực hiện hành vi trộm cắp dữ liệu đào tạo quy mô lớn và trả hàng tỷ USD để dàn xếp. Đó là sự thật.”
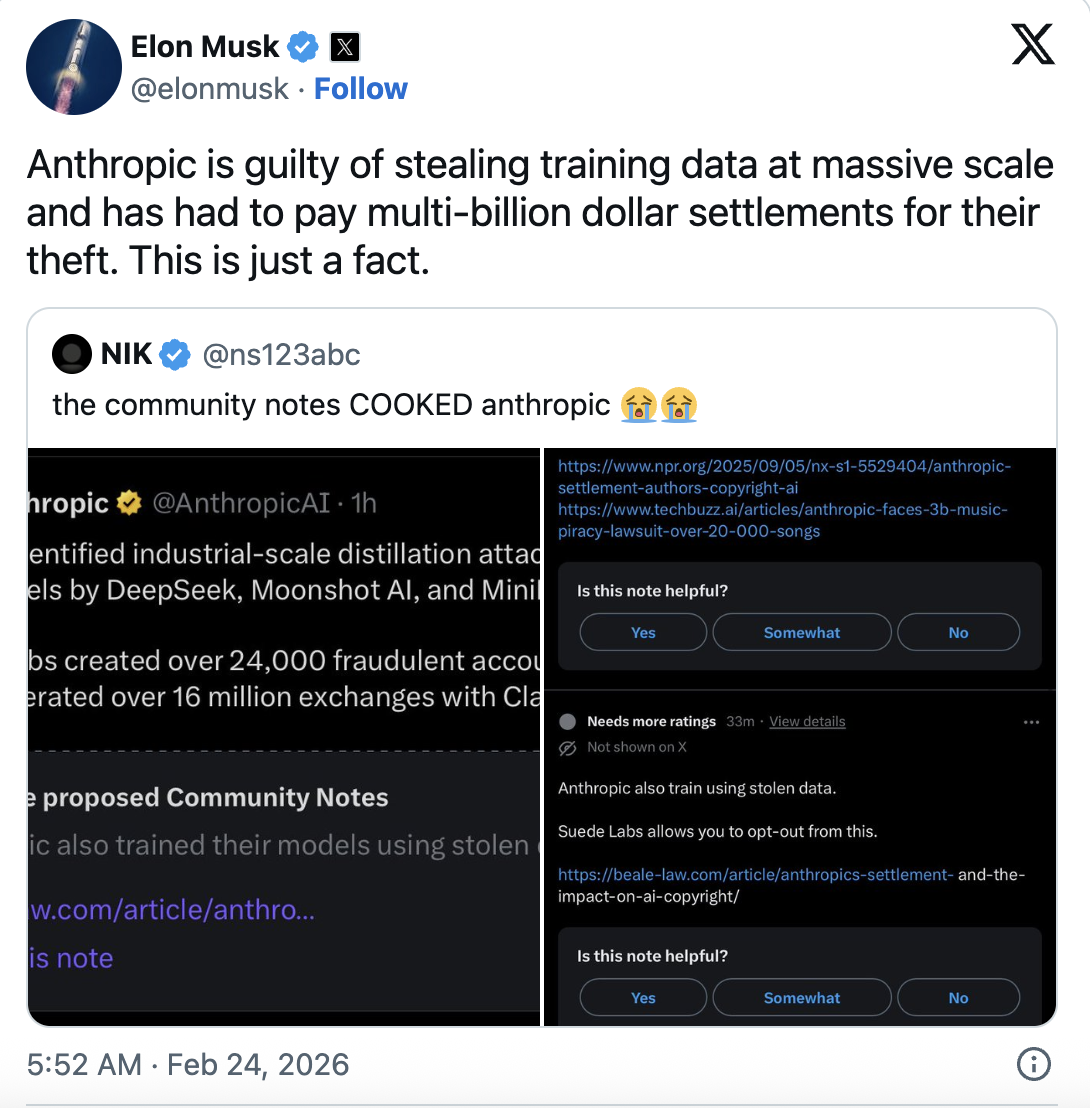
Đồng sáng lập IO.Net, Tory Green, bình luận: “Các anh đào tạo mô hình trên toàn bộ internet, còn khi người khác học từ API công khai của các anh thì lại gọi đó là ‘tấn công chưng cất’?”
Anthropic gọi chưng cất là “tấn công”, nhưng đây là thực tiễn tiêu chuẩn trong ngành AI. OpenAI dùng để nén GPT-4, Google dùng để tối ưu Gemini, bản thân Anthropic cũng từng làm. Điểm khác biệt lần này: Anthropic là mục tiêu.
Như giáo sư AI Erik Cambria của Đại học Công nghệ Nanyang nói với CNBC: “Ranh giới giữa sử dụng hợp pháp và khai thác ác ý thường rất mờ nhạt.”
Trớ trêu thay, Anthropic vừa trả 1,5 tỷ USD để dàn xếp các cáo buộc đào tạo Claude bằng sách vi phạm bản quyền. Họ đào tạo trên toàn bộ internet, rồi lại cáo buộc người khác học từ API công khai của mình. Đó không chỉ là tiêu chuẩn kép—mà là tiêu chuẩn ba.
Anthropic muốn đóng vai nạn nhân nhưng cuối cùng lại trở thành bị cáo.
Phá bỏ cam kết an toàn: RSP 3.0
Trong cùng ngày đối đầu với Lầu Năm Góc và tranh luận với Thung lũng Silicon, Anthropic công bố phiên bản thứ ba của Chính sách Mở rộng Trách nhiệm.
Nhà khoa học trưởng Jared Kaplan chia sẻ với truyền thông: “Chúng tôi không nghĩ việc dừng đào tạo mô hình AI sẽ giúp ích cho ai. Khi AI phát triển quá nhanh, việc cam kết đơn phương trong khi đối thủ tăng tốc là vô nghĩa.”
Nói cách khác, nếu người khác không tuân thủ luật chơi, chúng tôi cũng sẽ không tuân thủ.
Cốt lõi của RSP 1.0 và 2.0 là cam kết cứng rắn: nếu năng lực mô hình vượt quá phạm vi biện pháp an toàn, việc đào tạo sẽ tạm dừng. Cam kết này giúp Anthropic có vị thế đặc biệt trong cộng đồng AI an toàn.
Nhưng phiên bản 3.0 đã loại bỏ cam kết đó.
Thay vào đó là khung “linh hoạt” hơn—tách biệt biện pháp an toàn Anthropic có thể thực hiện với khuyến nghị toàn ngành. Cứ mỗi 3–6 tháng sẽ công bố báo cáo rủi ro, có chuyên gia độc lập đánh giá.
Như vậy có gọi là trách nhiệm không?
Chris Painter, chuyên gia đánh giá độc lập từ tổ chức phi lợi nhuận METR, nhận xét sau khi xem bản thảo: “Điều này cho thấy Anthropic tin rằng họ phải chuyển sang ‘chế độ ưu tiên cứu nguy’ vì đánh giá và kiểm soát rủi ro không thể theo kịp tốc độ phát triển năng lực. Đây là minh chứng cho thấy xã hội chưa sẵn sàng trước rủi ro thảm họa của AI.”
Tạp chí TIME đưa tin Anthropic mất gần một năm tranh luận nội bộ về bản sửa đổi này, với sự nhất trí của CEO Amodei và hội đồng quản trị. Về mặt chính thức, chính sách ban đầu nhằm thúc đẩy đồng thuận ngành—nhưng ngành không hưởng ứng. Chính quyền Trump chọn buông lỏng AI, thậm chí muốn bãi bỏ luật cấp bang. Luật liên bang về AI vẫn xa vời. Năm 2023, khuôn khổ quản trị toàn cầu tưởng như khả thi, nhưng ba năm sau, cánh cửa đó đã đóng lại.
Một nhà nghiên cứu quản trị AI lâu năm ẩn danh nhận xét thẳng thắn: “RSP là tài sản thương hiệu giá trị nhất của Anthropic. Loại bỏ việc tạm dừng đào tạo chẳng khác gì một hãng thực phẩm hữu cơ âm thầm gỡ nhãn ‘hữu cơ’, rồi bảo bạn rằng kiểm nghiệm giờ minh bạch hơn.”
Khủng hoảng bản sắc ở mức định giá 380 tỷ USD
Đầu tháng 2, Anthropic hoàn tất vòng gọi vốn 30 tỷ USD ở mức định giá 380 tỷ USD, với Amazon là nhà đầu tư chính. Kể từ khi thành lập, công ty đạt doanh thu hàng năm 14 tỷ USD, và ba năm qua con số này tăng gấp mười lần mỗi năm.
Đồng thời, Lầu Năm Góc đe dọa đưa công ty vào danh sách đen. Musk công khai cáo buộc trộm cắp dữ liệu. Cam kết an toàn cốt lõi bị xóa bỏ. Giám đốc an toàn AI của Anthropic, ông Mrinank Sharma, từ chức và viết trên X: “Thế giới đang gặp nguy hiểm.”
Mâu thuẫn?
Có lẽ mâu thuẫn là ADN của Anthropic.
Được thành lập bởi các cựu lãnh đạo OpenAI lo ngại về tốc độ an toàn của OpenAI, Anthropic lại phát triển mô hình mạnh hơn, nhanh hơn, đồng thời cảnh báo thế giới về nguy cơ của chúng.
Mô hình kinh doanh tóm gọn: chúng tôi sợ AI hơn bất cứ ai, nên bạn hãy trả tiền để chúng tôi xây dựng nó.
Câu chuyện này đã phát huy tối đa trong năm 2023–2024. An toàn AI là từ khóa nóng ở Washington, và Anthropic là nhà vận động hành lang nổi bật nhất.
Đến năm 2026, cục diện đã thay đổi.
“Woke AI” trở thành từ miệt thị chính trị, quy định AI cấp bang bị Nhà Trắng ngăn chặn, và dù dự luật SB 53 của California (Anthropic hậu thuẫn) được thông qua, không có gì thay đổi ở cấp liên bang.
Câu chuyện an toàn của Anthropic đang chuyển từ “khác biệt” thành “gánh nặng chính trị”.
Anthropic đang thực hiện màn cân bằng phức tạp—phải đủ “an toàn” để giữ thương hiệu, nhưng đủ “linh hoạt” để không bị thị trường hay chính phủ loại bỏ. Vấn đề là mức độ dung thứ ở cả hai phía đều giảm dần.
Giá trị thực của câu chuyện an toàn giờ là bao nhiêu?
Xâu chuỗi ba sự kiện lại sẽ thấy bức tranh rõ ràng.
Cáo buộc công ty Trung Quốc chưng cất Claude củng cố lập luận vận động kiểm soát xuất khẩu chip. Bỏ “tạm dừng an toàn” giúp Anthropic tiếp tục cuộc đua vũ khí AI. Từ chối yêu cầu vũ khí tự động của Lầu Năm Góc giữ lại lớp đạo đức cuối cùng.
Mỗi nước đi đều hợp lý, nhưng lại mâu thuẫn với nhau.
Bạn không thể vừa nói công ty Trung Quốc “chưng cất” mô hình của mình là đe dọa an ninh quốc gia, vừa xóa cam kết ngăn mô hình của chính mình mất kiểm soát. Nếu mô hình nguy hiểm như vậy, lẽ ra bạn phải thận trọng hơn—chứ không phải hung hăng hơn.
Trừ khi bạn là Anthropic.
Trong ngành AI, bản sắc không được xác định bởi tuyên bố—mà bởi bảng cân đối kế toán. Câu chuyện “an toàn” của Anthropic thực chất là khoản cộng thương hiệu.
Thời kỳ đầu cuộc đua AI, khoản cộng này rất giá trị. Nhà đầu tư trả giá cao cho “AI có trách nhiệm”, chính phủ duyệt “AI đáng tin cậy”, khách hàng sẵn sàng trả phí cho “AI an toàn hơn”.
Nhưng đến năm 2026, khoản cộng này đang dần biến mất.
Anthropic giờ không còn đối mặt câu hỏi “có nên thỏa hiệp không”, mà là “nên thỏa hiệp với ai trước”. Thỏa hiệp với Lầu Năm Góc, thương hiệu tổn thất. Thỏa hiệp với đối thủ, cam kết an toàn bị xóa. Thỏa hiệp với nhà đầu tư, cả hai bên đều phải nhượng bộ.
Đến 17:01 thứ Sáu, Anthropic sẽ đưa ra câu trả lời.
Dù kết quả ra sao, một điều chắc chắn: Anthropic từng sống nhờ “chúng tôi khác OpenAI”, giờ đang trở nên giống tất cả những công ty còn lại.
Kết thúc của một cuộc khủng hoảng bản sắc thường là sự biến mất của bản sắc đó.
Tuyên bố:
- Bài viết này được đăng lại từ [TechFlow]. Bản quyền thuộc về tác giả gốc [Ada]. Nếu bạn có thắc mắc về việc đăng lại, vui lòng liên hệ đội ngũ Gate Learn, chúng tôi sẽ xử lý kịp thời theo quy trình liên quan.
- Tuyên bố miễn trừ trách nhiệm: Quan điểm và ý kiến trong bài viết này hoàn toàn thuộc về tác giả, không cấu thành lời khuyên đầu tư.
- Các phiên bản ngôn ngữ khác của bài viết này do đội ngũ Gate Learn dịch. Nếu không đề cập Gate, các bài dịch không được phép sao chép, phân phối hoặc đạo văn.







