Компанія з безпеки BlockSec повторно провела оцінку стандарту аудиту смарт-контрактів за допомогою AI під назвою EVMBench, розробленого OpenAI та Paradigm. Результати показали, що AI-боти значно менш ефективні при зіткненні з реальними сценаріями експлуатації.
Дослідницька група розширила тестове середовище, додавши більше конфігурацій моделей, а також включила нові випадки безпеки, що трапилися нещодавно — дані, які раніше не з’являлися у навчальних наборах AI-моделей.
Хоча AI ще не може замінити фахівців з безпеки, у звіті наголошується, що машинний інтелект може природно доповнювати процес перевірки коду людиною.
Початкові результати EVMBench можуть бути надто оптимістичними
Раніше EVMBench оцінював завдання безпеки смарт-контрактів, такі як виявлення, виправлення помилок і експлуатація вразливостей, з дуже вражаючими результатами. За даними звіту, AI може експлуатувати 72% і виявляти близько 45% вразливостей, на основі 120 вибраних зразків з аудитів Code4rena.
Однак BlockSec вважає, що початкові умови тестування могли спотворити результати. Співзасновник Yajin Zhou повідомив, що при повторному тестуванні з більшою кількістю конфігурацій і 22 реальними випадками атак рівень успішної експлуатації AI становив 0%.
Розширення конфігурацій і виключення “зараження даних”
Дослідження збільшило кількість конфігурацій моделей з 14 до 26, шляхом гнучкого поєднання ботів з різними “скелетами”, а не обмежуючись екосистемою одного постачальника. За словами дослідників, попередній підхід ускладнював розрізнення між продуктивністю через можливості моделі та перевагами архітектури.
Крім того, BlockSec поставив під сумнів явище “зараження даних”, коли EVMBench використовує вразливості, оприлюднені раніше — ймовірно, вже включені до навчальних даних AI. Щоб уникнути цього, команда протестувала 22 випадки безпеки, що трапилися після лютого 2026 року, які виходять за межі “вікна знань” моделей.
AI повністю провалився у реальній експлуатації
Найбільш вражаючий результат: у 110 пар тестів між агентами та випадками (5 агентів на 22 ситуації) жоден не завершився повною експлуатацією. Це свідчить, що навіть найсучасніші AI ще дуже далекі від здатності здійснювати реальні атаки.
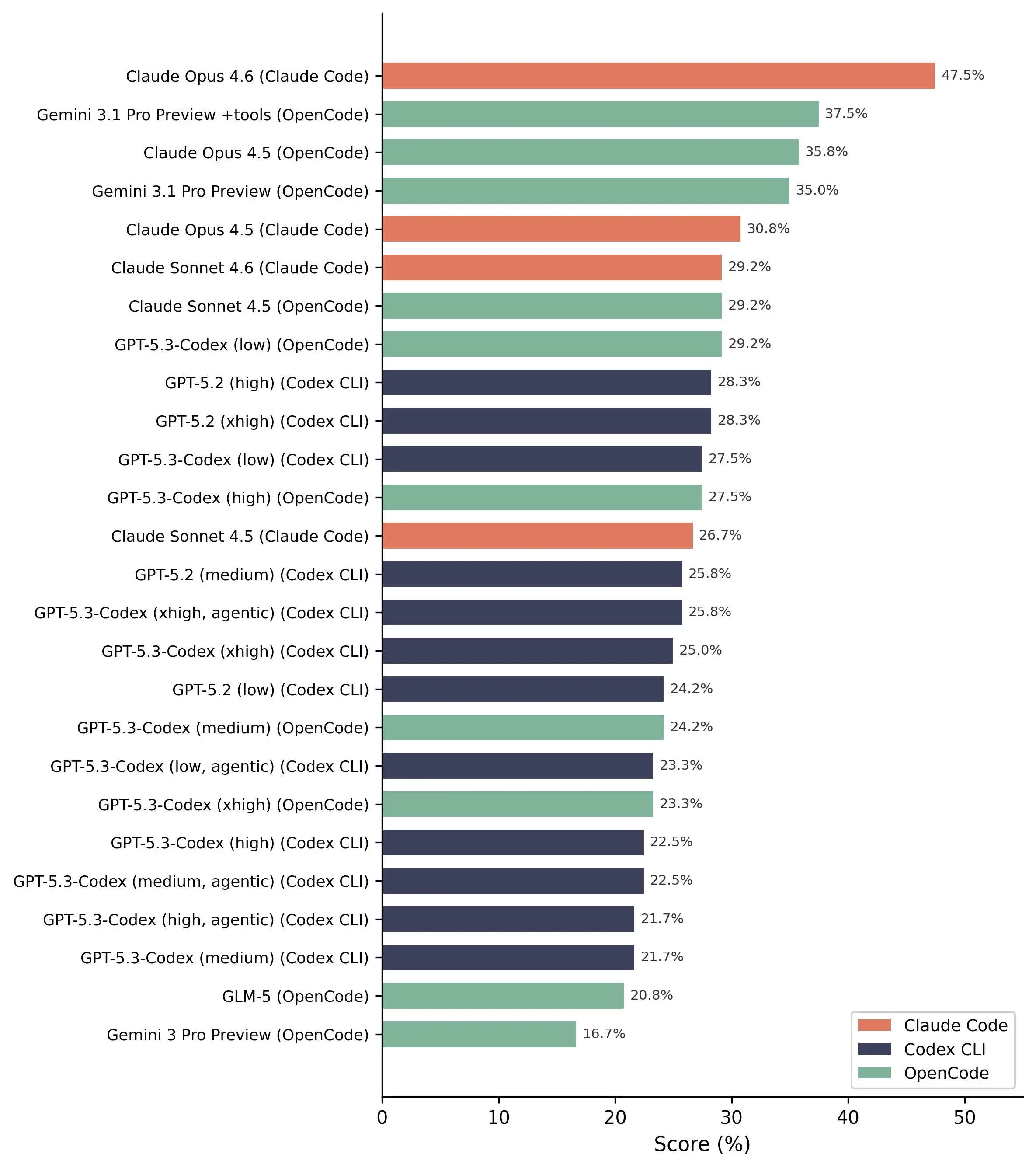
Проте у виявленні вразливостей результати залишаються досить позитивними. Модель Claude Opus 4.6 найкраще показала себе, виявивши 13 з 20 реальних вразливостей.
Поширені, звичні вразливості AI виявляє легко, але більш складні випадки майже повністю пропускає.
Майбутнє — співпраця AI і людини
Дослідження робить висновок, що AI ще не може замінити людину у аудиті безпеки, і більш важливим є питання ефективної взаємодії двох сторін.
AI має переваги у масштабності та здатності швидко сканувати системи, тоді як людина переважає у глибокому аналізі, розумінні протоколів і логічних висновках. Ці фактори доповнюють один одного.
За даними BlockSec, правильний шлях — не замінити людину AI, а створити модель співпраці, яка забезпечить більш всебічний аудит.
Застереження: Інформація на цій сторінці може походити від третіх осіб і не відображає погляди або думки Gate. Вміст, що відображається на цій сторінці, є лише довідковим і не є фінансовою, інвестиційною або юридичною порадою. Gate не гарантує точність або повноту інформації і не несе відповідальності за будь-які збитки, що виникли в результаті використання цієї інформації. Інвестиції у віртуальні активи пов'язані з високим ризиком і піддаються значній ціновій волатильності. Ви можете втратити весь вкладений капітал. Будь ласка, повністю усвідомлюйте відповідні ризики та приймайте обережні рішення, виходячи з вашого фінансового становища та толерантності до ризику. Для отримання детальної інформації, будь ласка, зверніться до
Застереження.

