Quant交易员 gemchange_ltd publicou uma longa mensagem no X, listando o roteiro completo de “se tivesse que começar de novo, em que ordem aprenderia”, desde probabilidade até cálculo estocástico, passando por cinco níveis matemáticos, em 18 meses saindo do zero para uma verdadeira introdução à quant trading. O artigo é uma tradução e reorganização do seu popular post no X, “How I’d Become a Quant If I Had to Start Over Tomorrow”, compilado por Flip.
(Resumindo: um trader que não depende de comissões ou exposição pública, que usa estratégias vencedoras de ciclo de análise, sem depender de exposição de carteira)
(Complemento: Top trader feminina de criptomoedas, com notas de sobrevivência de dez mil palavras: “Não deixe que a promessa de riqueza rápida destrua você”)
Índice do artigo
Toggle
- Parte I: Probabilidade — a linguagem da incerteza
- Parte II: Estatística — aprender a ouvir os dados
- Parte III: Álgebra linear — a máquina que move tudo
- Parte IV: Cálculo e otimização — a linguagem da mudança
- Parte V: Cálculo estocástico — o verdadeiro limiar do Quant
- Polymarket
- Como o LMSR precifica crenças
- Mapa de carreira em quant trading: quatro protótipos
- Caixa de ferramentas e leituras recomendadas
- Três coisas que o autor gostaria de ter sabido mais cedo
Aviso de tradução: Este artigo não constitui aconselhamento financeiro. O mercado tem riscos, pesquise bem antes de investir.
Vamos começar com alguns números: em 2025, o salário total de um Quant recém-contratado em grandes instituições será entre 300 mil e 500 mil dólares. A contratação de AI/ML na área financeira cresce 88% ao ano. Essa rota tem um mapa?
Este artigo é o que o autor gostaria que alguém tivesse lhe dado no começo. A rota de aprendizagem está organizada na ordem “o que você deve aprender”, cada conceito construindo o anterior, como um jogo de videogame — você não pula fases. Mas se você realmente se dedicar, não assistir a vídeos chatos de introdução à finança no YouTube (isso é perda de tempo), e realmente resolver problemas e praticar — em cerca de 18 meses, você sairá do zero e entenderá algo de verdade.
Deixe de lado todo o seu conhecimento prévio de trading. A maioria pensa que quant é sobre escolher ações, ter opinião sobre Tesla, prever resultados financeiros. Na verdade, não é. Quant é matemática. Você trabalha com relações estatísticas, precificação de ineficiências, e com a vantagem estrutural de que “o mercado é um sistema complexo onde pessoas cometem erros sistemáticos”.
Parte I: Probabilidade — a linguagem da incerteza
Tudo em finanças quantitativas pode ser resumido a uma pergunta: qual a taxa de sucesso? Ela está a meu favor?
Essa é a probabilidade. Se você não entender profundamente probabilidade, o que vem a seguir neste artigo não fará sentido.
Probabilidade condicional: a forma de pensar do Quant
A maioria pensa em valores absolutos: isso é verdadeiro ou falso. O Quant pensa condicionalmente: dado o que eu sei agora, qual a probabilidade de isso acontecer?
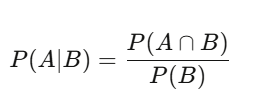
P(A|B) = P(A∩B) / P(B) — dado que B aconteceu, a probabilidade de A é a probabilidade de ambos acontecerem, dividida pela probabilidade de B. Parece simples, mas tem impacto profundo. Uma ação tem 60% de dias de alta — essa é a probabilidade básica. Mas em dias com volume acima da média, a chance de alta sobe para 75%. Essa probabilidade condicional é a informação relevante; o valor de 60% é ruído.
Teorema de Bayes: atualize suas avaliações em tempo real
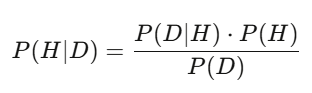
Pós-teste = (probabilidade de ver esses dados dado que a hipótese é verdadeira) × probabilidade prévia ÷ probabilidade total de ver esses dados. Na prática, usa-se amostragem de Monte Carlo para calcular. A lógica é a mesma: Bayes é a forma de ajustar suas avaliações diante de novas informações. Se seu modelo diz que uma ação vale 50 dólares, e o relatório financeiro mostra receita 3% maior que o esperado — sua avaliação posterior aumenta. Quem atualiza mais rápido e com mais precisão, ganha.
Valor esperado e variância: seus dois melhores amigos
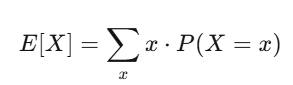
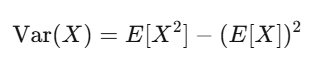
Valor esperado é a força da sua crença; variância é o risco. Se sua estratégia tem valor esperado positivo e você consegue suportar as oscilações da variância, provavelmente ganhará dinheiro.
Tarefa nível 1 (2 horas por dia, 3-4 semanas)
- Ler: Blitzstein & Hwang, “Introduction to Probability” (PDF gratuito de Harvard), fazer todos os exercícios dos capítulos 1-6
- Programar: simular 10.000 lançamentos de moeda, usar visualização para verificar a lei dos grandes números
- Programar: implementar um atualizador de Bayes, com entrada de priori e verossimilhança, saída de posterior
import numpy as np
import matplotlib.pyplot as plt
# Lei dos grandes números: média de execução converge para a probabilidade verdadeira
np.random.seed(42)
lancamentos = np.random.choice([0, 1], size=10000, p=[0.5, 0.5])
media_rodando = np.cumsum(lancamentos) / np.arange(1, 10001)
plt.figure(figsize=(10, 4))
plt.plot(media_rodando, linewidth=0.7)
plt.axhline(y=0.5, color='r', linestyle='--', label='Probabilidade verdadeira')
plt.xlabel('Número de lançamentos')
plt.ylabel('Média acumulada')
plt.title('Demonstração da Lei dos Grandes Números')
plt.legend()
plt.savefig('lln.png', dpi=150)
print(f"Após 10.000 lançamentos: {media_rodando[-1]:.4f} (verdadeiro: 0.5000)")
Parte II: Estatística — aprender a ouvir os dados
Depois de entender a linguagem da probabilidade, o próximo passo é extrair informações dos dados. A primeira lição da estatística é: a maioria das descobertas aparentemente significativas são ruído.

Teste de hipóteses: seu filtro contra ruído
Você criou um modelo com retorno anualizado de 15%. É real? Assume-se a hipótese nula H₀: “o retorno esperado é zero”, calcula-se uma estatística de teste e um p-valor. Mas atenção: se testar 1.000 estratégias aleatórias, por sorte, 50 terão p < 0,05. É o problema de múltiplos testes. A solução é correção Bonferroni (dividir o nível de significância pelo número de testes) ou controle de FDR (False Discovery Rate) de Benjamini-Hochberg. Muitos iniciantes superestimam suas descobertas. Aceite que seus primeiros 10 resultados são ruído — economize dinheiro.
Análise de regressão: decompondo retornos
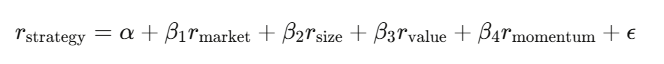
Regressão linear y = Xβ + ε é a ferramenta principal na finança. Regressa o retorno da estratégia contra fatores de risco conhecidos, o intercepto α é o retorno excessivo — a parte que não explica os fatores conhecidos.
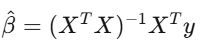
Se, após controlar os fatores, α for zero, sua “vantagem” é apenas exposição de mercado disfarçada. Use erro padrão de Newey-West, pois dados financeiros têm autocorrelação e heterocedasticidade. Usar erro padrão comum é como dirigir com para-brisa trincado em alta velocidade.
Estimativa de máxima verossimilhança (MLE)
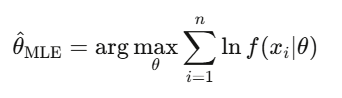
É o método padrão na finança para ajustar modelos, seja calibrar GARCH, estimar saltos em processos, ou ajustar preços de opções ao mercado. Quando alguém fala em “calibrar” um modelo, quase sempre está usando MLE.
Tarefa nível 2 (4-5 semanas)
- Ler: Wasserman, “All of Statistics”, capítulos 1-13
- Baixar retornos reais de ações (usando yfinance), testar normalidade (provavelmente falha), ajustar uma distribuição t com MLE, comparar resultados
- Usar statsmodels para regressar um portfólio com os fatores Fama-French
- Implementar teste de permutação: embaralhar datas 10.000 vezes, comparar desempenho permutado com o real
Parte III: Álgebra linear — a máquina que move tudo
Álgebra linear parece chata, mas é a base de tudo: construção de portfólios, análise de componentes principais, redes neurais, estimação de covariância, modelos de fatores. Sem matriz, não há Quant.

Pensamento matricial
A matriz de covariância Σ captura como cada ativo se move em relação aos outros. Para 500 ações, Σ é 500×500, com 125.250 valores únicos. A variância de uma carteira w é w’Σw — uma forma quadrática que é o núcleo do modelo de Markowitz, gestão de risco, tudo.
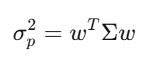
Valores próprios: o que realmente importa
Para um universo de 500 ações, os primeiros 5 vetores próprios explicam 70% da variância total. O resto é ruído. Usar decomposição em valores próprios muda tudo: é redução de dimensionalidade e a base do investimento em fatores.
Tarefa nível 3 (4-6 semanas)
- Assistir: Gilbert Strang, MIT 18.06 — toda a aula, sem pular
- Ler: Strang, “Introduction to Linear Algebra”, fazer todos os exercícios
- Fazer PCA de retornos do S&P 500, plotar espectro de valores próprios, identificar os três principais componentes
- Implementar a otimização de portfólio de média-variância de Markowitz do zero
import numpy as np
import cvxpy as cp
np.random.seed(42)
n_ativos = 10
mu = np.random.uniform(0.04, 0.15, n_ativos)
A = np.random.randn(n_ativos, n_ativos) * 0.1
cov = A @ A.T + np.eye(n_ativos) * 0.01
w = cp.Variable(n_ativos)
objetivo = cp.Minimize(cp.quad_form(w, cov))
restricoes = [
mu @ w >= 0.08, # retorno mínimo
cp.sum(w) == 1, # total investido
w >= -0.1, # limite de venda a descoberto
w <= 0.3 # limite de compra
]
problema = cp.Problem(objetivo, restricoes)
problema.solve()
retorno = mu @ w.value
volatilidade = np.sqrt(w.value @ cov @ w.value)
sharpe = (retorno - 0.03) / volatilidade
print(f"Retorno do portfólio: {retorno:.4f}")
print(f"Volatilidade: {volatilidade:.4f}")
print(f"Índice de Sharpe: {sharpe:.4f}")
Parte IV: Cálculo e otimização — a linguagem da mudança
Cálculo é a linguagem de descrever mudanças. Em finanças, tudo muda: preços, volatilidade, correlações, distribuições. Cálculo descreve e usa essas mudanças. Derivadas aparecem na retropropagação de redes neurais e nos gregos de opções.
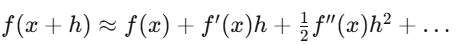
A série de Taylor é uma aproximação de Delta hedge de primeira ordem, Gamma de segunda. Itô é diferente de cálculo clássico, porque o termo de segunda ordem (dW_t)² não desaparece.
Parte 4: tarefas (4-5 semanas)
- Ler: Boyd & Vandenberghe, “Convex Optimization” (PDF gratuito de Stanford), capítulos 1-5
- Implementar gradiente descendente para minimizar a função de Rosenbrock
- Usar cvxpy para resolver um problema de otimização de portfólio com custos de transação
Parte V: Cálculo estocástico — o verdadeiro limiar do Quant
Antes de aprender cálculo estocástico, você é um cientista de dados que gosta de finanças. Depois, é um Quant de verdade. Aqui você aprende a modelar a incerteza em tempo contínuo, derivar a equação de Black-Scholes do zero, entender por que o mercado de derivativos de trilhões funciona assim.

Movimento Browniano: formalizando a incerteza
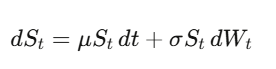
O movimento Browniano (Wiener) W_t é um passeio aleatório contínuo. A ideia central — que tudo depende disso — é que dW_t tem magnitude √dt, ou seja, (dW_t)² = dt. Parece detalhe técnico, mas é a verdade mais importante em finanças quantitativas.
Itô Lemma
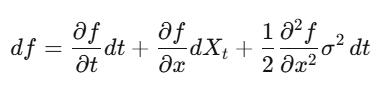
Na análise clássica, faz-se uma expansão de Taylor, (dx)² é negligenciável. Mas se x é um processo estocástico, (dW_t)² = dt é um termo de primeira ordem, não pode ser ignorado. Itô Lemma: df = (∂f/∂t + μ∂f/∂x + ½σ²∂²f/∂x²)dt + σ∂f/∂x dW_t. Aplicando a preços de opções, chega-se ao Black-Scholes.
Derivando o Black-Scholes do zero
Passo 1: Seja V(S,t) o preço da opção, aplique Itô a V.
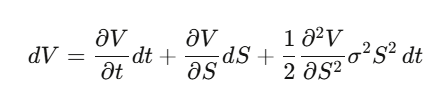
Passo 2: Crie uma carteira Delta-hedge Π = V − (∂V/∂S)·S, calcule dΠ — as componentes de dW desaparecem, e essa carteira é localmente livre de risco.
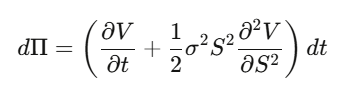
Passo 3: Uma carteira livre de risco deve crescer à taxa livre de risco.
Passo 4: Substitua e organize para obter a PDE do Black-Scholes.
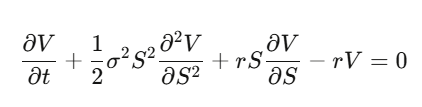
Note o que acontece: a taxa de drift μ desaparece. O preço da opção não depende do retorno esperado da ação, nem da preferência de risco. Pode-se usar uma medida neutra ao risco para precificar opções. Essa é a compreensão que realmente muda sua cabeça.
Para uma opção de compra europeia com strike K e vencimento T, a solução da PDE é:
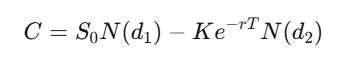
onde
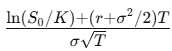
e
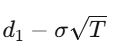
Gregos
- Delta Δ: quanto a opção se move com o preço da ação
- Gamma Γ: a taxa de variação do Delta
- Theta Θ: perda de valor temporal
- Vega V: sensibilidade à volatilidade
- Rho ρ: sensibilidade à taxa de juros
import numpy as np
from scipy.stats import norm
def black_scholes(S, K, T, r, sigma, option_type='call'):
d1 = (np.log(S/K) + (r + sigma**2/2)*T) / (sigma*np.sqrt(T))
d2 = d1 - sigma*np.sqrt(T)
if option_type == 'call':
return S*norm.cdf(d1) - K*np.exp(-r*T)*norm.cdf(d2)
else:
return K*np.exp(-r*T)*norm.cdf(-d2) - S*norm.cdf(-d1)
def monte_carlo_opcao(S0, K, T, r, sigma, n_sims=500_000):
Z = np.random.standard_normal(n_sims)
ST = S0 * np.exp((r - sigma**2/2)*T + sigma*np.sqrt(T)*Z)
payoffs = np.maximum(ST - K, 0)
preco = np.exp(-r*T) * np.mean(payoffs)
erro = np.exp(-r*T) * np.std(payoffs) / np.sqrt(n_sims)
return preco, erro
S, K, T, r, sigma = 100, 105, 1.0, 0.05, 0.2
bs = black_scholes(S, K, T, r, sigma)
mc, err = monte_carlo_opcao(S, K, T, r, sigma)
print(f"Black-Scholes: ${bs:.4f}")
print(f"Monte Carlo: ${mc:.4f} ± {err:.4f}")
Nível 5: tarefas (6-8 semanas, o mais difícil)
- Ler: Shreve, “Stochastic Calculus for Finance II” (padrão ouro)
- Alternativa: Arguin, “A First Course in Stochastic Calculus” (mais acessível)
- Derivar: para f(S) = ln(S), obter o termo de drift -σ²/2
- Derivar: a equação completa de Black-Scholes, a partir da argumentação de hedge Delta
- Programar: implementar o Black-Scholes do zero, comparar com Monte Carlo, verificar convergência
Polymarket
O mercado mais interessante do mundo, com matemática que conecta todos os tópicos deste artigo:
Probabilidade, teoria da informação, otimização convexa, programação inteira.
Como o LMSR precifica crenças
Regra de pontuação de mercado logarítmica (LMSR)
Criada por Robin Hanson, para mercados preditivos automatizados.
Para n resultados, a função de custo é:
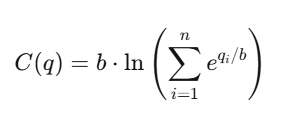
onde:
- q_i: quantidade de ações emitidas para resultado i
- b: parâmetro de liquidez
O preço do resultado i é:
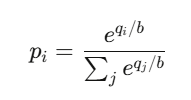
Que é exatamente a função softmax — a mesma usada por classificadores de redes neurais.
Propriedades:
- Todos os preços somam 1
- Todos os preços estão entre 0 e 1
- O mercado sempre fornece preços, com liquidez infinita
O maior prejuízo do formador de mercado é limitado a:
b × ln(n)
Mapa de carreira em quant trading: quatro protótipos
Quant Researcher (QR): encontra padrões em dados massivos, constrói modelos preditivos, precisa de doutorado em matemática, estatística ou ML, ou destaque na faculdade. Em firmas como Jane Street, tem dezenas de GPUs.
Quant Developer/Engineer (QD): constrói plataformas de trading, motores de execução, pipelines de dados em tempo real, para que os modelos do QR possam ser negociados. Precisa de C++, Rust, Python, sistemas de baixa latência.
Quant Trader (QT): toma decisões, gerencia capital, controla risco, faz julgamentos em tempo real. Salários variam muito, chegando a oito dígitos em anos de pico.
Risk Quant: valida modelos, calcula VaR, faz testes de estresse, conformidade regulatória. Trajetória mais estável, teto mais baixo. Novos papéis em IA/ML, usando deep learning para gerar sinais, crescem rápido — recrutamento cresce 88% ao ano.
Salários (top nos EUA, Jane Street, Citadel, HRT):
- Recém-formados: US$ 300k–500k + bônus
- Médio prazo (3-7 anos): US$ 550k–950k
- Sênior (8+ anos): US$ 1M–3M+
- Estrelas: US$ 3M–30M+
Firmas médias (Two Sigma, DE Shaw): cerca de US$ 250k–350k para recém-formados. Jane Street paga em 2025 uma média de US$ 1,4 milhão por ano, valor médio.
Processo de entrevista: análise de currículo → teste online (usando Zetamac, objetivo acima de 50 pontos, questões de lógica) → entrevista por telefone (probabilidade, jogos de azar) → Superday (3-5 rodadas, simulação de trading, código, quadro branco). As perguntas são difíceis, testando sua capacidade de usar dicas e colaborar. Estagiários geralmente vêm de ciência da computação ou matemática, conhecimento financeiro não é obrigatório.
Preparação recomendada: “Green Book” de Xinfeng Zhou (guia de entrevistas em quant finance, mais de 200 questões reais), junto com QuantGuide.io (LeetCode para quant) e Brainstellar.
Caixa de ferramentas e leituras recomendadas
Stack Python: pandas/polars (Polars é 10-50x mais rápido em grandes volumes), numpy/scipy, xgboost/lightgbm, pytorch, cvxpy, QuantLib, statsmodels, backtesting com NautilusTrader ou vectorbt.
Fontes de dados gratuitas: yfinance, Finnhub (60 requisições por minuto), Alpha Vantage. Para nível intermediário, Polygon.io (US$ 199/mês, baixa latência). Para uso corporativo, Bloomberg Terminal (~US$ 32.000/ano).
Bibliografia (por ordem):
- Matemática: Blitzstein & Hwang “Probabilidade” → Strang “Álgebra Linear” → Wasserman “All of Statistics” → Boyd & Vandenberghe “Otimização Convexa” → Shreve “Cálculo Estocástico I & II”
- Finanças Quant: Hull “Options, Futures and Other Derivatives” → Natenberg “Volatilidade e Precificação de Opções” → López de Prado “Machine Learning em Finanças” → Ernest Chan “Quantitative Trading” → Zuckerman “Quem Decifra os Mistérios do Mercado”
- Entrevistas: Zhou “Green Book” → Crack “Heard on the Street” → Joshi “Perguntas de Entrevista Quant”
- Competições: Kaggle da Jane Street (US$ 100 mil), WorldQuant BRAIN (mais de 100 mil usuários, comprando sinais), Citadel Datathon (entrada rápida para vagas)
Três coisas que o autor gostaria de ter sabido mais cedo
O erro de estimativa é o verdadeiro inimigo. Kelly completo, Markowitz sem restrições, modelos ML com muitas variáveis — todos falham pelo overfitting de ruído na estimação. Matemática funciona bem com parâmetros reais, mas nunca temos parâmetros verdadeiros. A diferença entre teoria e prática é sempre o erro de estimação. Os melhores Quant são aqueles que respeitam isso.
Ferramentas estão democratizadas, julgamento não. Qualquer um pode usar QuantLib, Polygon.io, PyTorch. Tecnologia é condição necessária, não suficiente. A vantagem está em dados únicos, modelos exclusivos ou execução diferenciada — não no pip install mais recente.
Matemática é a barreira de proteção. AI pode programar, propor estratégias, mas só quem consegue derivar por que o Itô tem aquele termo extra, provar que sob medida neutra ao risco o preço descontado é uma martingala, ou saber se a relaxação convexa em problemas de arbitragem é tight ou loose — essa fluência matemática diferencia o “Quant que constrói vantagem” do “Quant que apenas usa vantagem alheia”. Vantagem emprestada tem prazo de validade.

