Na tarde de 20 de janeiro, a X disponibilizou em código aberto seu mais recente algoritmo de recomendação.
Musk comentou: “Sabemos que esse algoritmo ainda é limitado e precisa de melhorias importantes, mas pelo menos você pode acompanhar nosso trabalho para aprimorá-lo em tempo real. Nenhuma outra plataforma social teria coragem de fazer isso.”
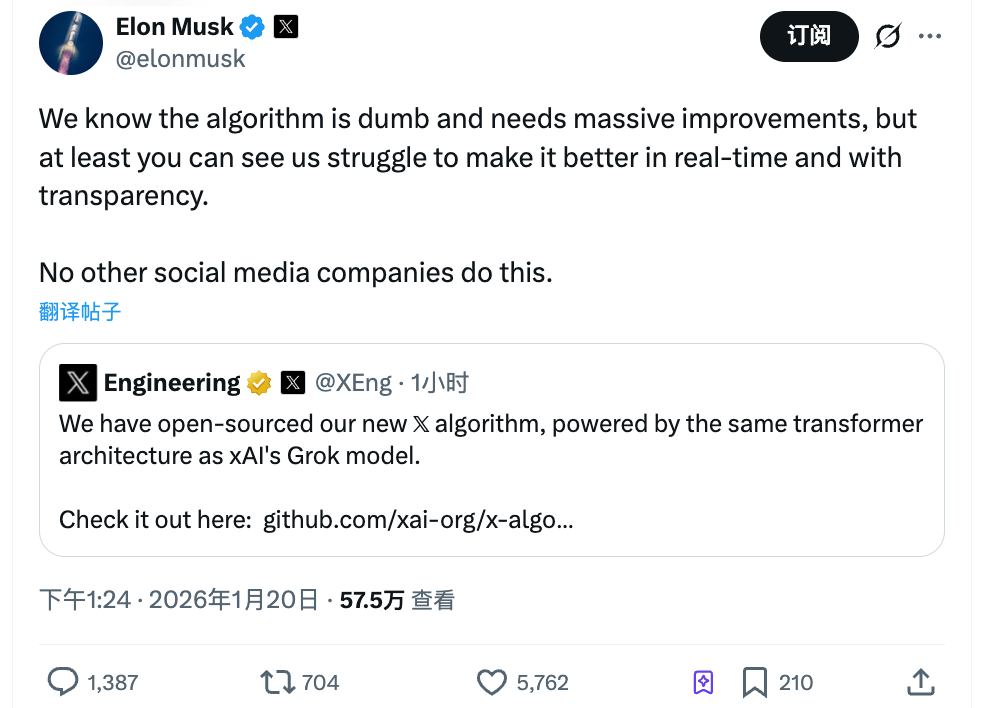
O pronunciamento traz dois pontos principais. Primeiro, ele reconhece as limitações do algoritmo. Segundo, destaca a transparência como diferencial competitivo.
Esta é a segunda vez que a X torna seu algoritmo open-source. A versão de 2023 ficou três anos sem atualizações e já estava fora do ambiente de produção. Agora, o código foi totalmente reescrito. O modelo central migrou do machine learning tradicional para o Grok transformer. Segundo a documentação oficial, “toda engenharia manual de features foi eliminada.”
Em resumo: o algoritmo anterior dependia de ajustes manuais dos parâmetros pelos engenheiros. Agora, a IA analisa diretamente seu histórico de interações para decidir se seu conteúdo será promovido.
Para criadores de conteúdo, isso significa que estratégias como “horário ideal de postagem” ou “tags que aumentam seguidores” podem perder eficácia.
Também analisamos o repositório open-source no GitHub e, com auxílio da IA, identificamos lógicas hard-coded que valem ser exploradas.
Mudança na lógica do algoritmo: das regras manuais ao julgamento orientado por IA
Primeiro, vamos esclarecer as diferenças entre as versões antiga e nova para evitar confusões na análise.
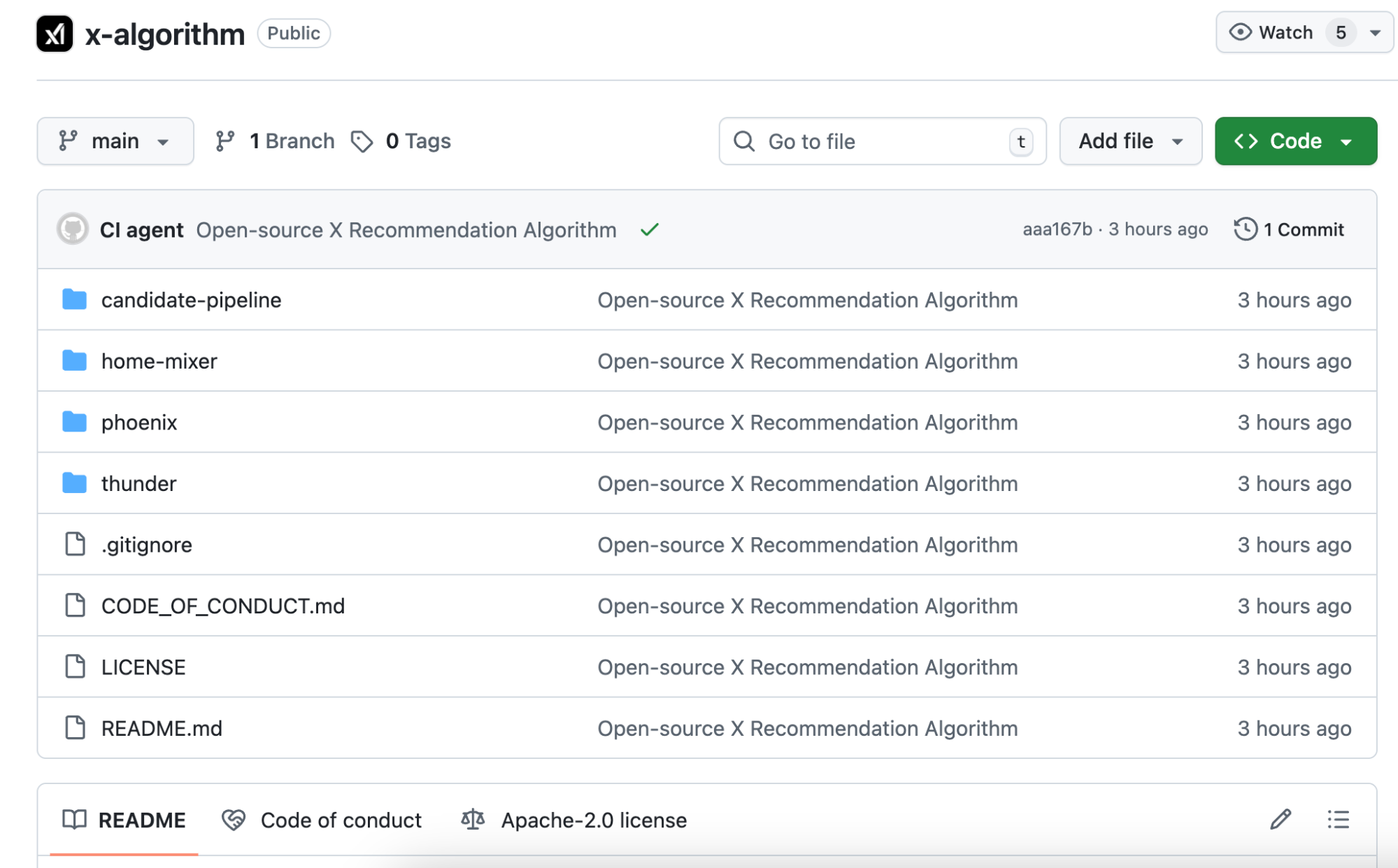
Em 2023, o algoritmo open-source do Twitter era o Heavy Ranker. Fundamentado em machine learning tradicional, os engenheiros definiam manualmente centenas de features: se o post tinha imagem, número de seguidores do autor, tempo desde a publicação, presença de links, entre outros.
Cada feature recebia um peso, ajustado continuamente para encontrar a melhor combinação.
A nova versão open-source, chamada Phoenix, tem arquitetura completamente diferente—pense nela como um algoritmo que depende de modelos de IA de grande escala. O núcleo utiliza o Grok transformer, mesma tecnologia base do ChatGPT e Claude.
O README oficial é direto: “Eliminamos todas as features criadas manualmente.”
O antigo sistema baseado em regras manuais e extração de características do conteúdo foi totalmente removido.
Então, como o algoritmo avalia se o conteúdo é relevante?
A resposta: sua sequência de comportamentos. O que você curtiu, para quem respondeu, em quais posts permaneceu mais de dois minutos, quais tipos de contas bloqueou. O Phoenix processa esses comportamentos no transformer, permitindo que o modelo aprenda e resuma padrões.
Para ilustrar: o algoritmo antigo funcionava como uma planilha de pontuação manual, atribuindo pontos a cada item marcado.
O novo algoritmo age como uma IA com acesso ao seu histórico completo de navegação, prevendo o que você deseja ver em seguida.
Para criadores, isso implica duas mudanças:
Primeiro, táticas como “melhor horário de postagem” ou “tags estratégicas” têm relevância muito menor. O modelo agora prioriza as preferências individuais de cada usuário, não mais features fixas.
Segundo, o destaque do seu conteúdo depende muito mais de “como os usuários reagem ao que você publica.” Essas reações são convertidas em 15 tipos de previsões comportamentais, detalhadas a seguir.
O algoritmo prevê 15 tipos de reações do usuário
Ao avaliar um post para recomendação, o Phoenix projeta 15 possíveis ações do usuário:
- Ações positivas: curtir, responder, repostar, repostar com citação, clicar no post, clicar no perfil do autor, assistir mais da metade de um vídeo, expandir imagem, compartilhar, permanecer por tempo determinado, seguir o autor
- Ações negativas: selecionar “não estou interessado”, bloquear o autor, silenciar o autor, denunciar
Cada ação recebe uma probabilidade estimada. Por exemplo, o modelo pode prever 60% de chance de você curtir um post e 5% de chance de bloquear o autor.
O algoritmo multiplica cada probabilidade pelo peso correspondente e soma para obter a pontuação final.
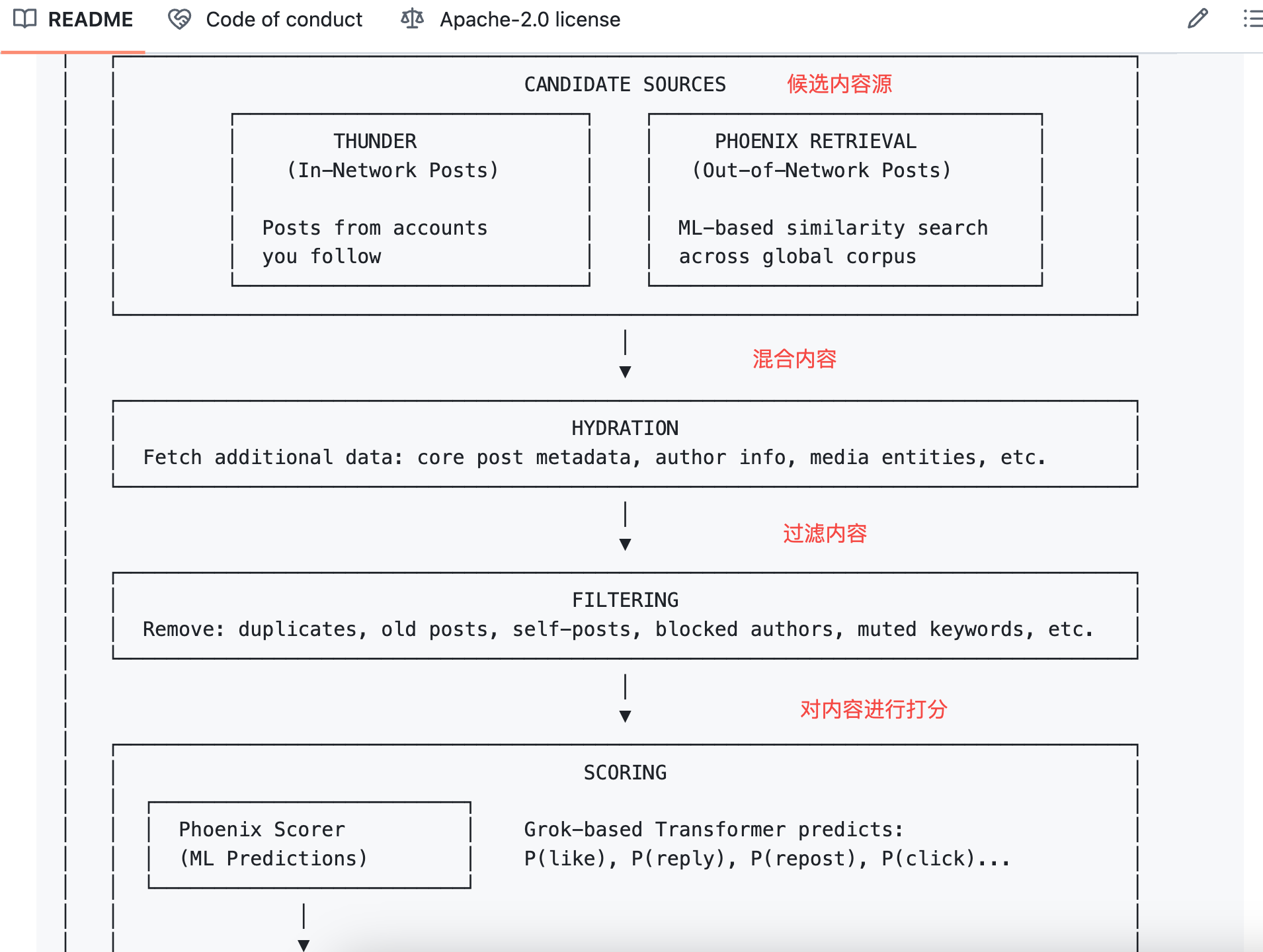
A fórmula é:
Pontuação final = Σ ( peso × P(açao) )
Ações positivas têm pesos positivos; ações negativas, negativos.
Posts com pontuação total mais alta sobem no ranking; os de pontuação baixa são rebaixados.
Na prática, o que define se o conteúdo é “bom” não é mais sua qualidade intrínseca (embora legibilidade e valor ainda sejam essenciais para compartilhamento). Agora, o que importa são “as reações que seu conteúdo provoca.” O algoritmo não avalia o conteúdo em si, mas sim o comportamento do usuário.
Com essa lógica, em casos extremos, um post de baixa qualidade que gera muitas respostas pode superar um post de alta qualidade sem engajamento. Esse parece ser o raciocínio do sistema.
Porém, o novo algoritmo open-source não divulga os pesos exatos para cada comportamento, diferente da versão de 2023.
Referência da versão antiga: uma denúncia = 738 curtidas
Vamos analisar o conjunto de dados de 2023. Apesar de desatualizado, ele ilustra como o algoritmo valoriza cada ação.
Em 5 de abril de 2023, a X publicou um conjunto de pesos no GitHub.
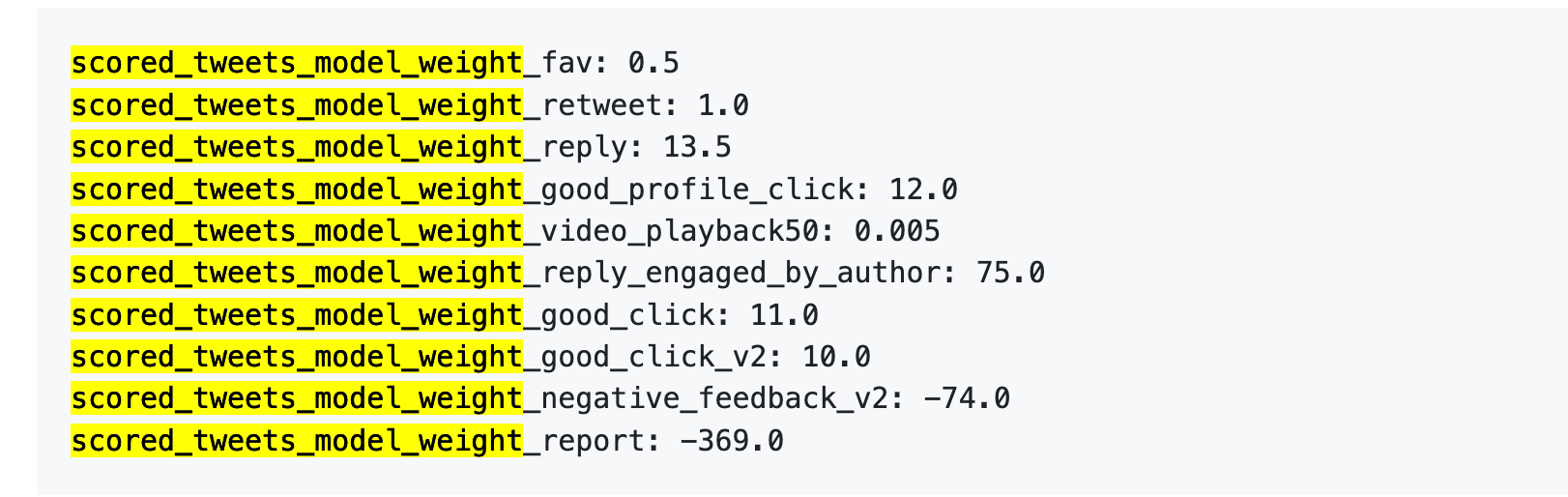
Veja os números:
Em termos práticos:
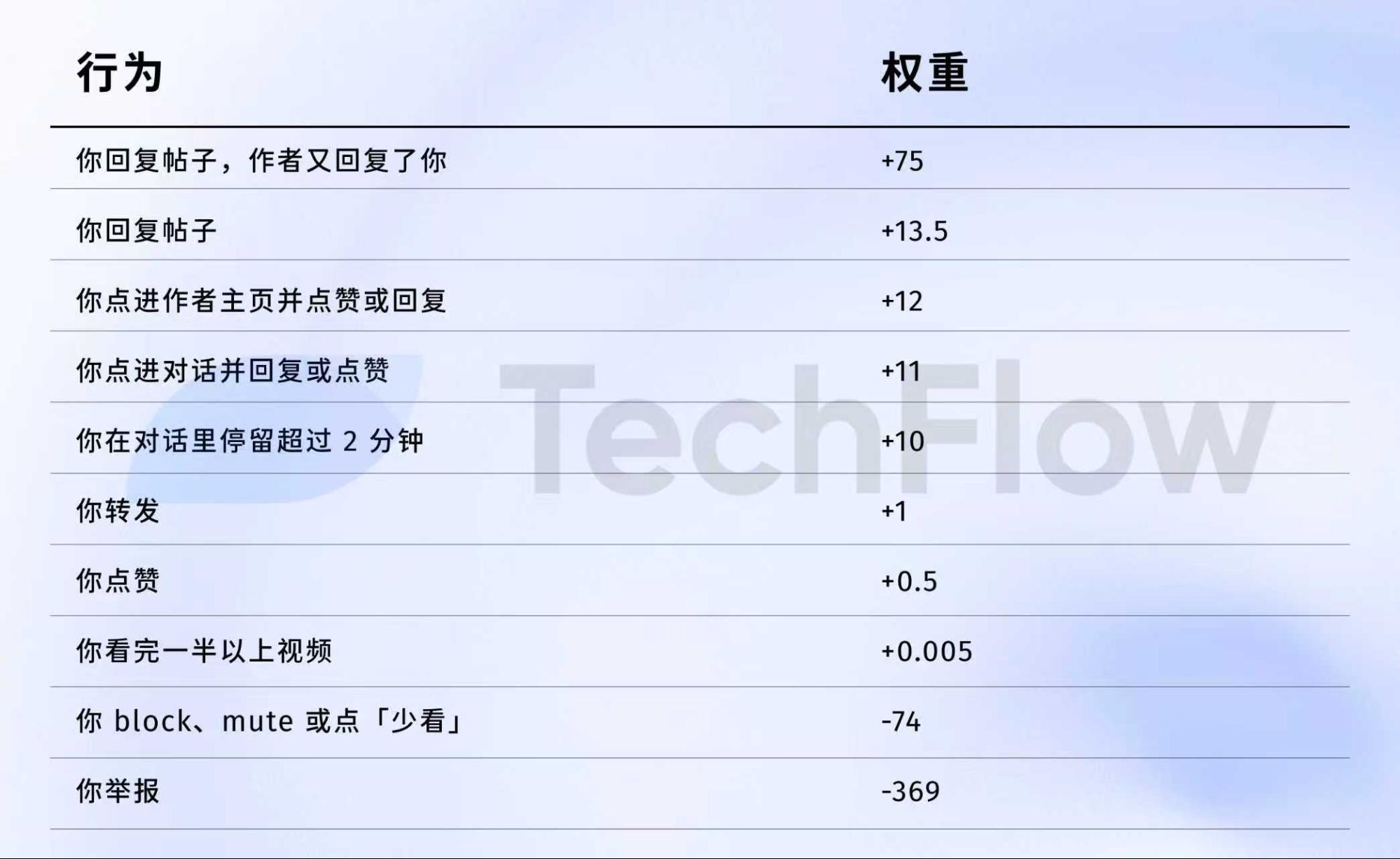
Fonte dos dados: versão antiga repositório GitHub twitter/the-algorithm-ml. Clique para acessar o algoritmo original.
Alguns números merecem destaque:
Primeiro, curtidas têm valor quase nulo. O peso é só 0,5, o menor entre ações positivas. O algoritmo praticamente desconsidera a curtida.
Segundo, conversas são altamente valorizadas. “Você responde e o autor responde de volta” tem peso 75—150 vezes maior que uma curtida. O algoritmo prioriza diálogos reais e não apenas likes.
Terceiro, feedback negativo tem penalidade alta. Um bloqueio ou silenciamento (-74) exige 148 curtidas para compensar. Uma denúncia (-369) demanda 738 curtidas. Essas penalizações acumulam na reputação da conta, afetando a distribuição dos posts futuros.
Quarto, taxa de conclusão de vídeo tem peso baixíssimo—só 0,005, praticamente irrelevante. Isso contrasta fortemente com plataformas como TikTok, que tratam esse índice como métrica central.
O documento oficial também informa: “Os pesos exatos podem ser ajustados a qualquer momento… Desde então, ajustamos periodicamente para otimizar as métricas da plataforma.”
Os pesos mudam a qualquer momento—e já mudaram.
A nova versão não revela valores específicos, mas a lógica do README permanece: ações positivas somam pontos, negativas subtraem, e a pontuação final é uma soma ponderada.
Os números exatos mudam, mas a ordem relativa se mantém. Responder ao comentário de alguém vale mais do que receber 100 curtidas. Ser bloqueado é pior do que não receber interação alguma.
O que os criadores podem fazer com essa informação?
Após revisar o código das versões nova e antiga do algoritmo do Twitter, seguem recomendações práticas:
1. Responda aos comentários recebidos. Na tabela de pesos, “autor responde ao comentador” é a ação mais valorizada (+75), 150 vezes mais importante que uma curtida. Não é preciso pedir comentários, mas sempre responda—até mesmo um “obrigado” é contabilizado pelo algoritmo.
2. Evite provocar bloqueios. Um bloqueio exige 148 curtidas para compensar. Conteúdo polêmico pode gerar engajamento, mas se isso resultar em “essa pessoa é irritante, bloquear”, sua reputação será prejudicada no longo prazo, afetando toda a distribuição futura dos posts. Controvérsia é uma faca de dois gumes—pense antes de provocar.
3. Coloque links externos nos comentários. O algoritmo penaliza posts que levam o usuário para fora da plataforma—Musk já confirmou isso. Se quiser direcionar tráfego, coloque o conteúdo principal no post e o link no primeiro comentário.
4. Não faça spam. O novo código inclui o Author Diversity Scorer, que penaliza postagens consecutivas do mesmo autor. O objetivo é diversificar o feed dos usuários; é melhor publicar um conteúdo de qualidade do que dez seguidos.
6. Não existe mais “horário ideal de postagem.” O algoritmo antigo usava “horário de postagem” como feature manual, mas o Phoenix eliminou esse critério. Agora, só o comportamento do usuário importa, não o horário. Estratégias como “terça-feira às 15h” são cada vez menos relevantes.
Essas são as conclusões possíveis a partir do código.
Há também regras de bônus e penalidades na documentação pública da X que não aparecem neste open-source: verificação com selo azul aumenta o alcance, posts em caixa alta são penalizados, e conteúdo sensível reduz o alcance em 80%. Essas regras não estão abertas, então não entram aqui.
No geral, este lançamento open-source é relevante.
A arquitetura completa do sistema, lógica de recall de conteúdo candidato, processo de pontuação e ranqueamento e diversos filtros estão presentes. O código está em Rust e Python, com estrutura clara e README mais detalhado que muitos projetos comerciais.
No entanto, alguns elementos-chave não foram abertos.
1. Os parâmetros de peso não são públicos. O código apenas explica que “ações positivas somam pontos, negativas subtraem”, mas não especifica o valor de uma curtida ou bloqueio. A versão de 2023 ao menos divulgou os números; desta vez, só o framework da fórmula está disponível.
2. Os pesos do modelo não são públicos. O Phoenix utiliza o Grok transformer, mas os parâmetros do modelo não estão incluídos. É possível ver como o modelo é chamado, mas não seu funcionamento interno.
3. Os dados de treinamento não são públicos. Não está claro quais dados foram usados para treinar o modelo, como o comportamento dos usuários foi amostrado ou como as amostras positivas e negativas foram construídas.
Ou seja, este open-source revela “usamos somas ponderadas para calcular pontuações”, mas não os pesos reais; mostra “usamos transformers para prever probabilidades comportamentais”, mas não revela a estrutura interna do transformer.
Em comparação, TikTok e Instagram não divulgaram nem isso. O open-source da X é de fato mais abrangente que o de outras grandes plataformas, mas ainda não é totalmente transparente.
Isso não significa que abrir o código não seja valioso. Para criadores e pesquisadores, poder revisar o código é melhor do que não ter acesso algum.
Isenção de responsabilidade:
- Este artigo foi reproduzido de [TechFlow], com direitos autorais do autor original [David]. Caso tenha dúvidas sobre esta reprodução, entre em contato com a equipe Gate Learn, que tomará as medidas cabíveis conforme os procedimentos aplicáveis.
- Isenção de responsabilidade: As opiniões expressas neste artigo são exclusivamente do autor e não constituem recomendação de investimento.
- Outras versões deste artigo em diferentes idiomas foram traduzidas pela equipe Gate Learn. Sem menção explícita a Gate, não copie, distribua ou replique o artigo traduzido.








