As large language models (LLMs) become important infrastructure for AI applications, developers building intelligent assistants, automated workflows, and AI Agents often face a key choice: should they call the OpenAI API directly, or use an AI Gateway platform to centrally manage model calls? Both approaches can deliver AI capabilities, but they differ clearly in system architecture, scalability, and operational complexity.
As the multi-model ecosystem continues to develop, enterprises and developers are increasingly using different models such as GPT, Claude, Gemini, and DeepSeek at the same time. How to manage model resources in a unified way, reduce vendor dependency risk, and improve system availability has become an important issue in AI infrastructure. Gate.AI emerged in this context as a model routing and AI Gateway platform, with a fundamentally different positioning from the traditional single-model API access model.
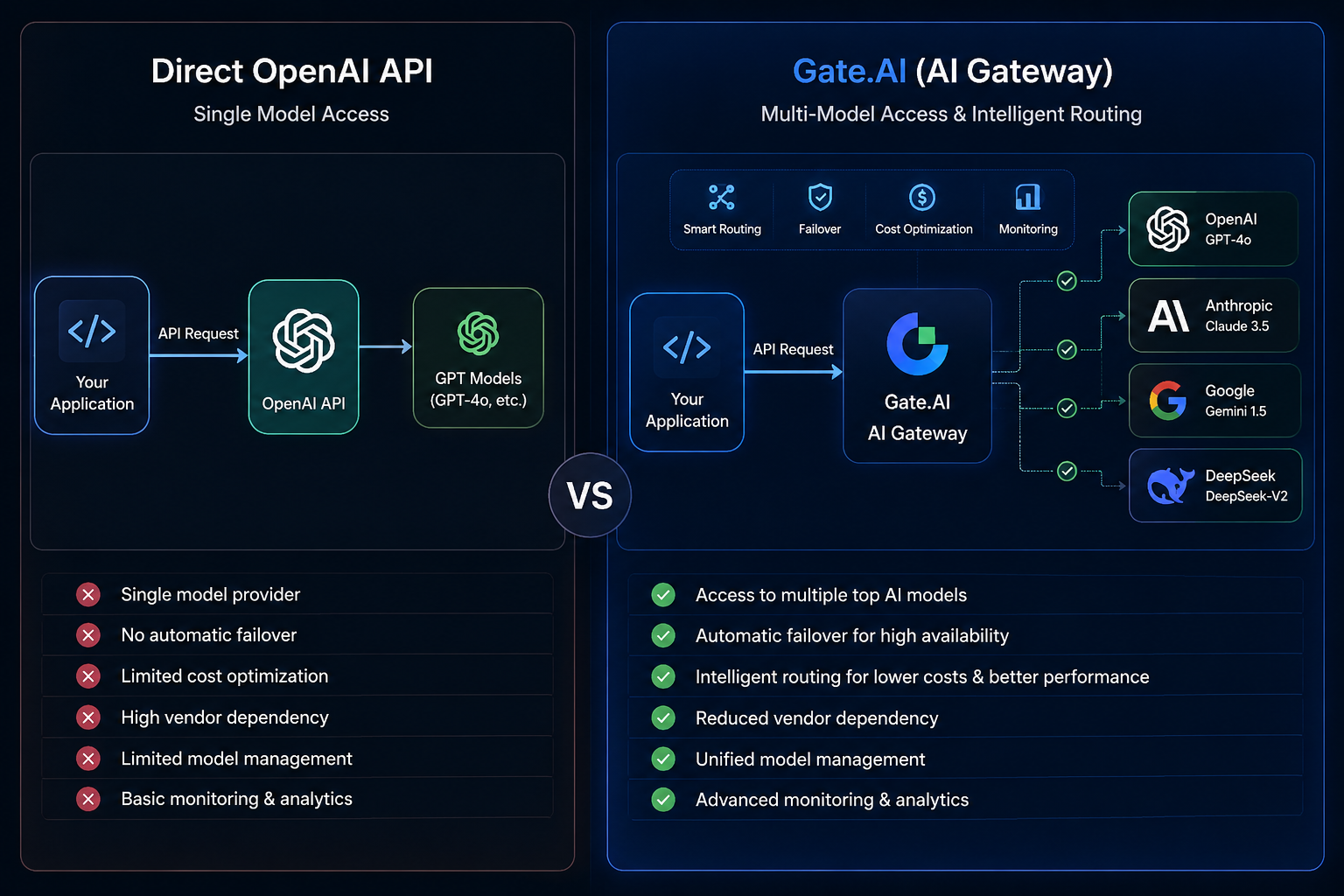
What Is the OpenAI API?
The OpenAI API is a model service interface provided by OpenAI. Developers can use standard API calls to access GPT models and integrate them into chatbots, content generation tools, search systems, and automation applications.
In this model, the application sends requests directly to OpenAI, and OpenAI returns the model inference results. The overall call chain is relatively simple. Developers only need to manage the interface of a single provider to complete deployment.
This architecture is suitable for early product validation, single-model applications, and scenarios with clearly defined requirements. However, as business scale grows, issues such as limited model choice, strong vendor dependency, and insufficient failure recovery may begin to appear.
What Is Gate.AI?
Gate.AI is a model routing platform for AI applications and AI Agents, connecting multiple mainstream AI model services through a unified interface.
Unlike directly calling a single model, Gate.AI sits between the application and model services, taking on functions such as AI Gateway, model routing, request governance, and model switching.
Developers do not need to build separate interfaces for different models. Instead, they can access models through a unified entry point. When one model becomes unavailable, the system can automatically switch to another model according to preset rules, improving overall availability and stability.
How Do OpenAI API and Gate.AI Differ in Model Coverage?
Model coverage is one of the clearest differences between the two approaches.
When directly calling the OpenAI API, developers can access models provided by OpenAI, but they cannot directly use services from other model providers through that same integration.
Gate.AI, by contrast, is designed to aggregate resources from multiple model providers, allowing developers to access different model capabilities through a single interface.
For example, an application may use GPT for complex reasoning tasks, Claude for long-text analysis, and DeepSeek for code generation. Through a model routing platform, these capabilities can be managed in a unified way.
This model helps avoid vendor lock-in and improves system flexibility.
Architectural Differences Between OpenAI API and Gate.AI: AI Gateway vs Single-Model Access
From an architectural perspective, the two belong to different layers of infrastructure.
Directly calling the OpenAI API means the application layer connects directly to the model layer:
Application → OpenAI API → GPT model
Gate.AI adds an AI Gateway layer in the middle:
Application → Gate.AI → Multi-model ecosystem
The responsibilities of an AI Gateway include not only request forwarding, but also:
-
Model routing
-
Request governance
-
Permission control
-
Monitoring and auditing
-
Load balancing
-
Failure recovery
As a result, the two are not simply substitutes for each other. They are different architectural models used by systems with different levels of complexity.
How Do OpenAI API and Gate.AI Differ in Cost Control?
As AI applications scale, model call costs become an important consideration.
In a single-model architecture, all requests are sent to the same model. Even when certain tasks do not require the highest-performance model, they still generate the same level of inference cost.
A model routing platform can dynamically select models based on task complexity.
For example:
-
Simple Q&A can use a lightweight model
-
Content summarization can use a mid-sized model
-
Complex reasoning can use a high-performance model
This tiered scheduling approach can improve resource efficiency and reduce overall inference costs.
Therefore, a multi-model architecture usually offers more room for cost optimization than a fixed-model architecture.
How Do OpenAI API and Gate.AI Differ in Failure Recovery and Availability?
AI applications increasingly require strong stability.
When developers connect directly to a single model service, requests may fail immediately if that service is interrupted, times out, or hits rate limits.
A multi-model Gateway architecture can provide automatic failure recovery through a Fallback mechanism.
When the preferred model cannot respond, the system can automatically switch the request to a backup model and continue execution.
This mechanism reduces the risk of single points of failure and improves the ability of the system to keep running continuously.
For long-running AI Agents or automated workflows, model failover has already become a key infrastructure capability.
Core Differences Between Gate.AI and OpenAI API
| Comparison Dimension |
Gate.AI |
OpenAI API |
| Positioning |
AI Gateway and model routing platform |
Single-model service interface |
| Model sources |
Multi-model ecosystem |
OpenAI models |
| Model switching |
Supported |
Not supported |
| Automatic Fallback |
Supported |
Not supported |
| Unified management |
Supported |
Limited |
| Cost optimization |
Supports dynamic routing |
Fixed model calls |
| AI Agent compatibility |
High |
Moderate |
| Vendor dependency |
Lower |
Higher |
| Scalability |
Strong |
Relatively limited |
When Is Direct OpenAI API Integration Suitable?
For prototype validation, small projects, and applications that clearly depend on GPT models, directly calling the OpenAI API usually allows fast deployment with lower complexity.
When the system is small, model requirements are simple, and failure recovery requirements are not demanding, a single-model architecture has the advantages of low implementation cost and simple maintenance.
When Is Gate.AI More Suitable?
For long-running AI products, enterprise-level applications, and AI Agent systems, multi-model management often matters more than access to a single model.
When a system needs to:
-
Use multiple models at the same time
-
Reduce vendor dependency
-
Enable automatic failover
-
Optimize costs
-
Provide unified governance and monitoring
An AI Gateway architecture usually offers greater flexibility and scalability.
Conclusion
The difference between Gate.AI and direct OpenAI API integration is, at its core, the difference between an AI Gateway architecture and a single-model access architecture.
The OpenAI API provides direct access to a single model ecosystem, making it suitable for quickly building and deploying AI applications. Gate.AI, by contrast, uses model routing and a unified gateway mechanism to provide infrastructure support for multi-model collaboration, high-availability systems, and AI Agents.
FAQs
Are OpenAI API and Gate.AI Competitors?
They do not fully belong to the same layer. The OpenAI API is a model service provider, while Gate.AI is a model routing and AI Gateway platform that can use OpenAI models as one of its connected resources.
Can Gate.AI Only Connect to OpenAI Models?
No. Gate.AI is designed to connect multiple AI model ecosystems in a unified way, allowing developers to access different model capabilities through a single interface.
What Is an AI Gateway?
An AI Gateway is an infrastructure layer located between applications and models. It is responsible for request forwarding, model routing, permission management, monitoring, governance, failure recovery, and other functions.
What Does the Fallback Mechanism Mean?
Fallback is an automatic failure recovery mechanism. When the preferred model is unavailable, the system automatically switches to a backup model to continue processing the request, reducing the risk of service interruption.
Does Using an AI Gateway Mean Developers Cannot Choose Models Directly?
No. An AI Gateway usually supports both automatic model routing and manual model selection. Developers can flexibly configure either mode depending on their specific needs.








