X熱文》もう一度やり直すならこう始める量化取引:18ヶ月で初級レベルに到達し、年収30万ドルの壁を突破
動區BlockTempo
量化(Quant)取引員 gemchange_ltd が X 上に長文を投稿し、「もしやり直せるならどの順番で学ぶか」の完全なロードマップを示した。確率論から始まり、確率微積分、五つの数学的関門を経て、18ヶ月で何も知らない状態から本格的な量的取引の入門に到達できる内容だ。この記事は彼のXにおける人気記事『How I’d Become a Quant If I Had to Start Over Tomorrow』を翻訳・再構成したものだ。
(前提:手数料不要、スプレッド晒さず、分析周期に基づく常勝戦略だけで勝負するトレーダーの話)
(補足:トップクラスの暗号通貨女性トレーダーの生存ノート:『速成で金持ちになれる』に騙されるな)
目次
Toggle
- Part I:確率論――不確実性の言語
- Part II:統計学――データの声を聴く
- Part III:線形代数――すべてを動かす機械
- Part IV:微積分と最適化――変化の言語
- Part V:確率微積分――真のQuantの門戸
- Polymarket
- LMSRは信念にどう価格をつけるか
- 量的取引キャリアのロードマップ:四つの原型
- ツールキットと書籍リスト
- 作者が早く知っておきたかった三つのこと
免責:本記事は投資の助言ではありません。市場にはリスクがあります。自己責任で調査してください。
まず数字をいくつか:2025年、トップ機関の新卒Quantの年収総額は30万〜50万ドル。金融業界のAI/ML採用は年88%増。果たしてこの道の地図はあるのか?
これは、著者が自分が最初に学び始めたときに誰かが渡してくれたかったものだ。学習ルートは「学ぶべき順序」に沿って整理されている。各概念は前の理解に基づき、まるでゲームのレベルアップのように進む。飛び級はできない。でも、真剣に取り組めば、YouTubeのつまらない金融入門動画(時間の無駄)を見ずに、問題を解き、手を動かすことで、約18ヶ月で何も知らない状態から実際に理解できるレベルに到達できる。
まず、あなたが知っていると思っている取引の知識はすべて脇に置いておく。多くの人は、量的取引は株選びやテスラの見通し、決算予測だと思っている。でも違う。Quant取引は数学だ。統計関係、価格の非効率性、そして「市場はシステム的な誤りを犯す人々が動かす複雑なシステムである」という事実に基づく構造的優位性を扱う。
Part I:確率論――不確実性の言語
量的金融のすべては、最終的にこういう問題に帰着する:勝率はどれくらい?自分に味方しているのか?
これが確率だ。確率を深く理解していなければ、この先の内容は意味をなさない。
条件付き確率:Quantの思考法
普通の人は絶対値で考える:これは本当か嘘か。Quantは条件付きで考える:今知っている情報に基づいて、これがどれだけの確率か。
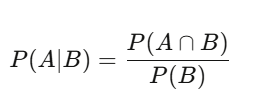
P(A|B) = P(A∩B) / P(B)——Bが起きたときにAが起きる確率。シンプルに見えるが、深い意味がある。例えば、ある株は60%の日に上昇する——これは基本確率だ。でも、出来高が平均以上の日に上昇確率は75%。この条件付き確率こそが意味のある情報だ。もともとの60%はノイズにすぎない。
ベイズ定理:リアルタイムで判断を更新
事後確率 = (このデータが観測される確率)× 事前確率 ÷ (このデータが観測される全確率)。実装ではモンテカルロサンプリングを使う。ロジックは同じ:ベイズは、新情報に直ちに判断を調整する方法だ。モデルが株価は50ドルと示しても、決算で売上が予想より3%高かったら、事後確率は上昇する。最も素早く、最も正確に更新できる人が勝つ。
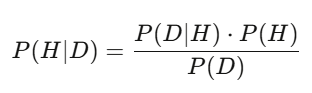
期待値と分散:あなたの二大友達
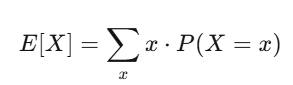
期待値はあなたの信念の強さ、分散はリスクだ。戦略の期待値が正で、かつ分散の揺れに耐えられるなら、儲かる可能性が高い。
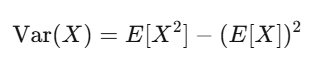
Level 1課題(毎日2時間、3-4週間)
- 読む:Blitzstein & Hwang『Introduction to Probability』(ハーバードの無料PDF)、第1-6章の問題をすべて解く
- コーディング:コイン投げを10,000回シミュレーションし、大数の法則を視覚化
- コーディング:ベイズ更新器を自作し、事前と尤度から事後を出す
import numpy as np
import matplotlib.pyplot as plt
# 大数の法則:平均値が真の確率に収束
np.random.seed(42)
flips = np.random.choice([0, 1], size=10000, p=[0.5, 0.5])
running_avg = np.cumsum(flips) / np.arange(1, 10001)
plt.figure(figsize=(10, 4))
plt.plot(running_avg, linewidth=0.7)
plt.axhline(y=0.5, color='r', linestyle='--', label='真の確率')
plt.xlabel('投げた回数')
plt.ylabel('実行平均')
plt.title('大数の法則の実演')
plt.legend()
plt.savefig('lln.png', dpi=150)
print(f"10000回後: {running_avg[-1]:.4f}(真の確率: 0.5000)")
Part II:統計学――データの声を聴く
確率の言語を理解したら、次はデータから何を読み取るかだ。統計学の第一課は:見かけ上意味のある発見の多くは、実はノイズにすぎない。

仮説検定:ノイズ検出器
あなたはモデルを作り、年率リターン15%の戦略をバックテストした。これは本当か?帰無仮説H₀:「この戦略の期待リターンはゼロ」だと設定し、検定統計量とp値を計算。ただし注意:1,000個のランダム戦略を試した場合、運だけでp値が0.05未満になるものが50個出る。これが多重比較の問題だ。解決策はBonferroni補正(有意水準を比較回数で割る)やBenjamini-Hochbergで偽陽性率を制御。初心者は自分が何か意味のあるものを見つけたと過大評価しがちだ。最初からこれを受け入れ、無駄な投資を避けよう。
回帰分析:リターンを分解する
線形回帰 y = Xβ + εは金融の主力ツール。戦略リターンを既知のリスク因子に回帰し、切片αが超過リターン(未説明部分)を示す。
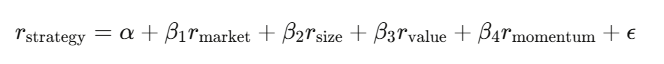
因子をコントロールしてもαがゼロなら、「優位性」は偽装された市場リスクの露出にすぎない。Newey-West標準誤差を使うのは、金融データは自己相関や異質分散を持つため。普通の最小二乗法の標準誤差は、まるで割れたフロントガラスで高速道路を走るようなものだ。
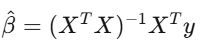
最尤推定(MLE)
金融業界では、モデルのキャリブレーションに最尤推定が使われる。GARCHのパラメータ推定や跳躍拡散の推定、オプション価格の市場適合もこれだ。誰かが「モデルをキャリブレーションしている」と言ったら、ほぼMLEのこと。
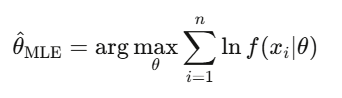
Level 2課題(4-5週間)
- 読む:Wasserman『All of Statistics』第1-13章
- 実データを使い、株価リターンの正規性を検定(必ず失敗する)、t分布にMLEでフィッティングし比較
- statsmodelsでFama-Frenchの三因子回帰を実行
- 配列置換検定:日付をシャッフルして10,000回、シャッフル後のパフォーマンスと実績を比較
Part III:線形代数――すべてを動かす機械
線形代数は退屈に思えるかもしれないが、投資ポートフォリオ構築、主成分分析、ニューラルネット、共分散行列推定、因子モデルなど、すべての基盤だ。行列を知らなければQuantは語れない。

行列思考
共分散行列Σは、資産間の相関・移動を捉える。例えば500銘柄ならΣは500×500の行列で、125,250のユニークな値を持つ。ポートフォリオの分散はw’Σwという二次型で表され、これがマルコウィッツの最適化やリスク管理の核心だ。
固有値:本当に重要なもの
500銘柄のデータから、最初の5つの固有ベクトルが70%以上の総変動を説明。残りはノイズだ。固有値分解を使い始めると世界が変わる:次元削減、ファクター投資の基礎だ。
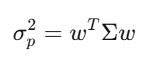
Level 3課題(4-6週間)
- Gilbert StrangのMIT 18.06線形代数コースを全て視聴(飛ばさずに)
- 『Introduction to Linear Algebra』を読み、問題を解く
- S&P 500のリターンにPCAを適用し、固有値スペクトルを描き、最初の3つの主成分を抽出
- 自分でMarkowitzの平均分散最適化を実装
import numpy as np
import cvxpy as cp
np.random.seed(42)
n_assets = 10
mu = np.random.uniform(0.04, 0.15, n_assets)
A = np.random.randn(n_assets, n_assets) * 0.1
cov = A @ A.T + np.eye(n_assets) * 0.01
w = cp.Variable(n_assets)
objective = cp.Minimize(cp.quad_form(w, cov))
constraints = [
mu @ w >= 0.08, # 最低リターン
cp.sum(w) == 1, # 完全投資
w >= -0.1, # 最大10%空売り
w <= 0.3 # 最大30%買い
]
prob = cp.Problem(objective, constraints)
prob.solve()
ret = mu @ w.value
vol = np.sqrt(w.value @ cov @ w.value)
sharpe = (ret - 0.03) / vol
print(f"ポートフォリオリターン: {ret:.4f}")
print(f"ポートフォリオリスク: {vol:.4f}")
print(f"シャープレシオ: {sharpe:.4f}")
Part IV:微積分と最適化――変化の言語
微積分は変化を記述する言語。金融では、価格やボラティリティ、相関は常に変動している。微積分はこれらの変化を捉え、利用する。導関数はニューラルネットの逆伝播やオプションのギリシャ文字計算に登場。
テイラー展開はデルタヘッジの一次近似、ガンマヘッジは二次補正。イツ微積分と普通の微積分は異なる。確率過程の二次項が消えないからだ。
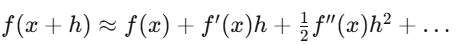
Level 4課題(4-5週間)
- 『Convex Optimization』(Boyd & Vandenberghe)の第1-5章を読む(スタンフォードの無料PDF)
- 勾配降下法を自作し、Rosenbrock関数の最小化
- cvxpyを使い、取引コストを考慮したポートフォリオ最適化問題を解く
Part V:確率微積分――真のQuantの門戸
確率微積分を学ぶ前のあなたは、ただの金融好きなデータサイエンティスト。学び終えると、やっとQuantになれる。連続時間で確率性をモデル化し、Black-Scholes方程式を導き、兆ドル規模のデリバティブ市場の仕組みを理解できる。
ブラウン運動:確率性の形式化

ブラウン運動(ウィーナ過程)W_tは連続時間のランダムウォーク。最も重要な洞察はこれだ——dW_tの「大きさ」は√dt、つまり(dW_t)²=dtだ。これは技術的な詳細だが、量的金融の最重要事実の一つ。
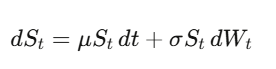
イツの引理
普通の微積分では、(dx)²は無視できるほど小さい。しかし、xが確率過程の場合、(dW_t)²=dtは一次項なので無視できない。イツの引理は:df = (∂f/∂t + μ∂f/∂x + ½σ²∂²f/∂x²)dt + σ∂f/∂x dW_t。これをオプション価格に適用すると、Black-Scholes方程式が得られる。
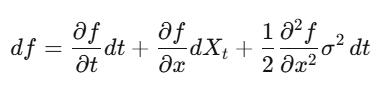
Black-Scholesの導出
ステップ1:V(S,t)をオプション価格とし、イツの引理を適用
ステップ2:デルタヘッジポートフォリオΠ=V−(∂V/∂S)·Sを構築し、その微小変化dΠを計算。dW_t項が完璧に打ち消され、局所的に無リスクなポートフォリオになる。
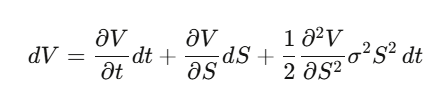
ステップ3:無リスクポートフォリオは無リスク金利で増価される。
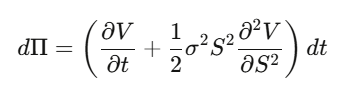
ステップ4:整理して偏微分方程式(PDE)を導出。
ここで、ドリフトμは消える。オプション価格は株価の期待リターンやリスク嗜好に依存しない。リスク中立測度の下で割引価格はマルゴリズム(鞅)になる。これが理解できると、頭が混乱する。
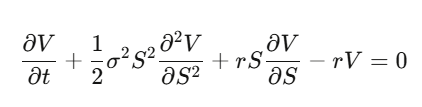
満期T、行使価格Kのヨーロピアンコールの解は:
ただし、
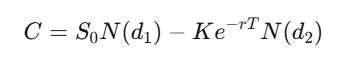
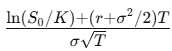
d_1=
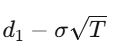
d_2=
ギリシャ文字
- Delta Δ:株価1ドルの変化に対するオプション価格の変動
- Gamma Γ:Deltaの変化率
- Theta Θ:時間経過による価値減少
- Vega V:ボラティリティ変化に対する感応度
- Rho ρ:金利変化に対する感応度
import numpy as np
from scipy.stats import norm
def black_scholes(S, K, T, r, sigma, option_type='call'):
d1 = (np.log(S/K) + (r + sigma**2/2)*T) / (sigma*np.sqrt(T))
d2 = d1 - sigma*np.sqrt(T)
if option_type=='call':
return S*norm.cdf(d1) - K*np.exp(-r*T)*norm.cdf(d2)
else:
return K*np.exp(-r*T)*norm.cdf(-d2) - S*norm.cdf(-d1)
def monte_carlo_option(S0, K, T, r, sigma, n_sims=500000):
Z = np.random.standard_normal(n_sims)
ST = S0 * np.exp((r - sigma**2/2)*T + sigma*np.sqrt(T)*Z)
payoffs = np.maximum(ST - K, 0)
price = np.exp(-r*T) * np.mean(payoffs)
stderr = np.exp(-r*T) * np.std(payoffs) / np.sqrt(n_sims)
return price, stderr
S, K, T, r, sigma = 100, 105, 1.0, 0.05, 0.2
bs_price = black_scholes(S, K, T, r, sigma)
mc_price, mc_err = monte_carlo_option(S, K, T, r, sigma)
print(f"Black-Scholes価格: ${bs_price:.4f}")
print(f"モンテカルロ価格: ${mc_price:.4f} ± {mc_err:.4f}")
Level 5:最難の課題(6-8週間)
- 『Stochastic Calculus for Finance II』(Shreve)を読む
- 代替案:『A First Course in Stochastic Calculus』(Arguin)も良い
- f(S)=ln(S)にイツの引理を適用し、-σ²/2を導出
- Black-Scholes方程式を完全に自分で導く
- 自作コードでBlack-Scholesとモンテカルロを比較し、収束を確認
Polymarket
今世界で最も面白い市場の一つ。そこに使われる数学は、本文のすべてのテーマをつなぐ。
LMSRは信念にどう価格をつけるか
対数市場スコア規則(Logarithmic Market Scoring Rule, LMSR)
Robin Hansonが発明した、自動化予測市場の仕組み。
n個の結果(outcomes)に対し、コスト関数は:
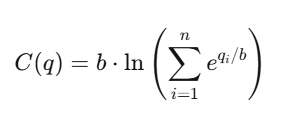
ここで、
- q_i:結果iの未決済シェア数
- b:流動性パラメータ
結果iの価格は:
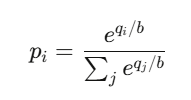
これがソフトマックス関数そのもので、ニューラルネットの分類器の出力にも使われる。
特性は:
- すべての価格の合計は常に1
- すべての価格は0と1の間
- 市場は常に価格を提供し、無限の流動性を持つ
マーケットメイカーの最大損失は、b×ln(n)に制限される。
量的取引キャリアのロードマップ:四つの原型
Quant Researcher(QR):大量のデータから規則性を見つけ、予測モデルを作り、戦略を設計。博士級の数学・統計・機械学習の知識が必要。Jane Streetのような機関ではGPU数万枚を扱う。
Quant Developer/Engineer(QD):研究者のモデルを実際に動かすための取引プラットフォームやリアルタイムデータパイプラインを構築。C++やRust、Pythonの生産環境経験と低遅延システムの知識が求められる。
Quant Trader(QT):資本配分とリスク管理の決定者。最も報酬が高く、トップは8桁ドルも稼ぐ。
Risk Quant:モデルの検証、VaR、ストレステスト、規制対応を担当。安定したキャリアだが天井は低め。AI/MLを使った新興の信号生成役も伸びている。2025年の採用は年88%増。
給与例(米国トップ機関、Jane Street、Citadel、HRT):
- 新卒:30万〜50万ドル+総額
- 中堅(3-7年):55万〜95万ドル
- ベテラン(8年以上):100万〜300万ドル
- スター・トレーダー/PM:300万〜3000万ドル
中規模機関(Two Sigma、D.E. Shaw)の新卒は約25万〜35万ドル。Jane Streetの平均年収は2025年上半期に140万ドルと推定。
面接フロー:履歴書審査→オンラインテスト(Zetamacで計算力、論理問題)→電話面接(確率問題、ギャンブルゲーム)→スーパー・デイ(3-5回連続面接、模擬取引、コーディング、ホワイトボード推論)。Jane Streetは意図的に難問を出し、ヒントや協力をどう使うかを見る。インターンも理系出身者が多く、金融知識はあまり重視されない。
準備にはXinfeng Zhouの『Green Book』(量化金融面接実戦ガイド、200問以上の実例)と、QuantGuide.io(量化版LeetCode)、Brainstellarがおすすめ。
ツールと書籍リスト
Pythonエコシステム:pandasやpolars(大規模データはpolarsが10〜50倍高速)、numpy/scipy、xgboost/lightgbm、pytorch、cvxpy、QuantLib、statsmodels、NautilusTraderやvectorbt。
無料データ源:yfinance、Finnhub(1分60リクエスト)、Alpha Vantage。中級者はPolygon.io(月額199ドル、遅延20ms未満)。企業向けはBloomberg Terminal(年間約3万2000ドル)。
書籍(順番に)
- 数学基礎:Blitzstein & Hwang『確率論』→ Strang『線形代数』→ Wasserman『All of Statistics』→ Boyd & Vandenberghe『凸最適化』→ Shreve『確率微積分 I & II』
- 量的金融:Hull『オプション・先物・その他のデリバティブ』→ Natenberg『オプションのボラティリティと価格』→ López de Prado『金融機械学習の進歩』→ Ernest Chan『量的取引』→ Zuckerman『市場の謎を解く人』
- 面接対策:Zhou『Green Book』→ Crack『Heard on the Street』→ Joshi『Quant面接問題』
- 競技:Jane Street Kaggle(賞金10万ドル)、WorldQuant BRAIN(10万人超のユーザー、αシグナル購入可)、Citadelデータトーナメント(最短ルートで正職へ)
作者が早く知っておきたかった三つのこと
推定誤差こそ最大の敵。Full Kellyや制約なしのMarkowitz、過剰な特徴量の機械学習モデルは、すべてパラメータ推定のノイズに過剰適合する失敗例だ。数学は真のパラメータのもとで完璧に動く。だが、実世界には真のパラメータは存在しない。理論と実践の差は、常に推定誤差に由来する。最も優れたQuantは、そのことを理解し、尊重している。
ツールはすでに民主化されているが、判断力はそうではない。誰でもQuantLibやPolygon.io、PyTorchにアクセスできる。技術は必要条件だが十分条件ではない。優位性は、ユニークなデータ、独自のモデル、実行能力にある。pip installの良さではない。
数学は最も強力な護城河。AIはコードを書き、戦略を提案できるが、なぜイツの引理に余分な項が出るのか、リスク中立測度下で価格が鞅になる理由、組み合わせアービトラージの凸緩和が緊か緩であるかを証明できる数学的流暢さこそが、差別化の本質だ。借り物の優位性には期限がある。

免責事項:このページの情報は第三者から提供される場合があり、Gateの見解または意見を代表するものではありません。このページに表示される内容は参考情報のみであり、いかなる金融、投資、または法律上の助言を構成するものではありません。Gateは情報の正確性または完全性を保証せず、当該情報の利用に起因するいかなる損失についても責任を負いません。仮想資産への投資は高いリスクを伴い、大きな価格変動の影響を受けます。投資元本の全額を失う可能性があります。関連するリスクを十分に理解したうえで、ご自身の財務状況およびリスク許容度に基づき慎重に判断してください。詳細は免責事項をご参照ください。
コメント
0/400
コメントなし