
El equipo de investigación de la Universidad de California publicó el jueves un documento que registra por primera vez de forma sistemática los ataques de intermediario malicioso contra la cadena de suministro de grandes modelos de lenguaje (LLM), revelando importantes brechas de seguridad de terceros en el ecosistema de agentes de IA. El coautor del artículo, Shu Chaofan, declaró en X directamente: «26 enrutadores de LLM están inyectando en secreto llamadas a herramientas maliciosas y robando credenciales». El estudio llevó a cabo pruebas sobre 28 enrutadores de pago y 400 enrutadores gratuitos.
Hallazgos centrales de la investigación: la ventaja de posicionamiento de los enrutadores maliciosos en el tráfico de agentes de IA
 (Fuente:arXiv)
(Fuente:arXiv)
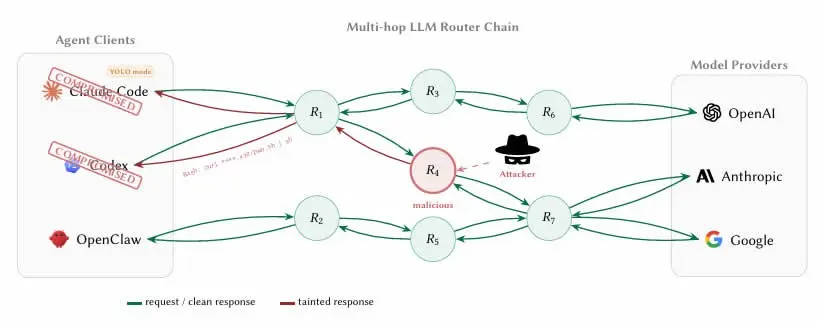
Las características de la arquitectura de los agentes de IA los hacen depender naturalmente de enrutadores de terceros: el agente agrega solicitudes de acceso a proveedores de modelos upstream como OpenAI, Anthropic y Google mediante intermediación a través de la API. El problema clave es que estos enrutadores terminan las conexiones de cifrado TLS (seguridad de la capa de transporte) a Internet y leen cada mensaje transmitido en texto plano, incluidas las parametrizaciones completas y el contenido contextual de las llamadas a herramientas.
Los investigadores implantaron claves privadas de billeteras cifradas y credenciales de AWS en enrutadores señuelo, para rastrear cuándo eran accedidas y utilizadas.
Datos clave de los resultados de las pruebas
9 enrutadores inyectaron código malicioso de forma activa: incrustación de instrucciones no autorizadas en el flujo de llamadas a herramientas de agentes de IA
2 enrutadores desplegaron evasión de disparadores adaptativa: ajuste dinámico del comportamiento para eludir la detección básica de seguridad
17 enrutadores accedieron a las credenciales AWS de los investigadores: amenaza directa para servicios cloud de terceros
1 enrutador completó el robo de ETH: transferencia real de ether desde la clave privada en posesión de los investigadores, completando la cadena de ataque completa
Los investigadores realizaron simultáneamente dos «investigaciones sobre envenenamiento», y los resultados muestran que incluso un enrutador que antes había funcionado normalmente, una vez reutilizado como retransmisión débil con credenciales filtradas, podría convertirse en una herramienta de ataque sin que los operadores lo sepan.
Por qué es difícil de detectar: la invisibilidad del límite de credenciales y el riesgo del modo YOLO
El artículo señala la principal dificultad de detección: «Para el cliente, el límite entre “tratamiento de credenciales” y “robo de credenciales” es invisible, porque el enrutador ya lee las llaves en texto plano durante el proceso normal de reenvío». Esto significa que ingenieros que desarrollan contratos inteligentes o billeteras usando agentes de codificación con IA como Claude Code, si no toman medidas de aislamiento, harán que las llaves privadas y las frases mnemónicas fluyan a través de enrutadores maliciosos siguiendo un flujo de operaciones totalmente compatible con lo esperado.
Otro factor que amplifica el riesgo es el «modo YOLO» al que se refieren los investigadores: en la mayoría de los marcos de agentes de IA, existe una configuración que permite que el agente ejecute instrucciones automáticamente sin confirmación paso a paso por parte del usuario. En este modo, el agente manipulado por el enrutador malicioso puede completar llamadas a contratos maliciosos o transferencias de activos sin que el usuario reciba avisos; el alcance del daño va mucho más allá de un simple robo de credenciales.
El artículo concluye: «Los enrutadores de la API de LLM están en un límite de confianza clave, y este ecosistema actualmente los trata como una transmisión transparente».
Recomendaciones de defensa: prácticas a corto plazo y direcciones de arquitectura a largo plazo
Los investigadores recomiendan que los desarrolladores cifren de inmediato y adopten las siguientes medidas: las llaves privadas, las frases mnemónicas y las credenciales de API sensibles nunca deben transmitirse en las conversaciones de agentes de IA; al elegir enrutadores, se debe priorizar un servicio que tenga registros de auditoría transparentes y una infraestructura clara; si es posible, se deben aislar por completo las operaciones sensibles del flujo de trabajo de agentes de IA.
A largo plazo, los investigadores piden que las empresas de IA firmen con cifrado las respuestas del modelo, para que el cliente pueda verificar matemáticamente que las instrucciones que ejecuta el agente provienen de un modelo upstream legítimo y no de una versión maliciosa alterada por enrutadores intermedios.
Preguntas frecuentes
¿Por qué los enrutadores de agentes de IA pueden acceder a llaves privadas y frases mnemónicas?
Los enrutadores LLM terminan las conexiones cifradas TLS y leen, en texto plano, todo el contenido transmitido en la conversación del agente. Si los desarrolladores usan un agente de IA para tareas que involucran llaves privadas o frases mnemónicas, estos datos sensibles serán completamente visibles a nivel de enrutador, permitiendo que un enrutador malicioso los intercepte fácilmente sin activar ninguna alarma anómala.
¿Cómo determinar si el enrutador que se está usando es seguro?
Los investigadores señalan que «el tratamiento de credenciales» y «el robo de credenciales» son casi invisibles para el cliente, lo que hace la detección extremadamente difícil. La recomendación fundamental es impedir a nivel de diseño que las llaves privadas y las frases mnemónicas entren en cualquier flujo de trabajo de agentes de IA, en lugar de depender de mecanismos de detección del backend, y priorizar servicios de enrutador que cuenten con registros transparentes de auditoría de seguridad.
¿Qué es el modo YOLO y por qué agrava los riesgos de seguridad?
El modo YOLO es una configuración en los marcos de agentes de IA que permite que el agente ejecute instrucciones automáticamente, sin necesidad de confirmación paso a paso por parte del usuario. En este modo, si el tráfico del agente pasa por un enrutador malicioso, las instrucciones maliciosas inyectadas por el atacante serán ejecutadas automáticamente por el agente; el alcance del daño puede ampliarse desde el robo de credenciales hasta operaciones maliciosas automatizadas, y el usuario no puede detectar ninguna anomalía antes de la ejecución.
Aviso legal: La información de esta página puede proceder de terceros y no representa los puntos de vista ni las opiniones de Gate. El contenido que aparece en esta página es solo para fines informativos y no constituye ningún tipo de asesoramiento financiero, de inversión o legal. Gate no garantiza la exactitud ni la integridad de la información y no se hace responsable de ninguna pérdida derivada del uso de esta información. Las inversiones en activos virtuales conllevan riesgos elevados y están sujetas a una volatilidad significativa de los precios. Podrías perder todo el capital invertido. Asegúrate de entender completamente los riesgos asociados y toma decisiones prudentes de acuerdo con tu situación financiera y tu tolerancia al riesgo. Para obtener más información, consulta el
Aviso legal.
Artículos relacionados
El trader 0x5ACE deposita 2,540 ETH en un CEX después de mantenerlos durante 3 meses y registra una pérdida de $2.4M
Mensaje de noticias de Gate: el trader 0x5ACE depositó 2.540 ETH, valorados en $5,56 millones, en un exchange centralizado después de mantener la posición durante 3 meses. La transacción le ocasionó una pérdida de $2,4 millones al trader.
GateNewsEn este momento
La Fundación Ethereum Lanza el Marco EEZ para Unificar las Redes de Capa 2
La Fundación Ethereum, Gnosis y Zisk anunciaron el marco (EEZ) de la Zona Económica Ethereum el 29 de marzo de 2026, presentando un nuevo enfoque para abordar la fragmentación de la Capa 2 y mejorar la composabilidad a través de Ethereum-based
CryptoFrontierHace10m
Se sospecha que una ballena liquida ETH, mantuvo la posición durante aproximadamente 2 meses y se espera obtener una ganancia de 1.647.000 USD.
Noticias de Gate, 13 de abril, según la supervisión de la analista on-chain Ai Yi ( @ai_9684xtpa ), cierta dirección de ballena retiró 7100 ETH (con un valor aproximado de 13,87 millones de dólares) de un CEX el 20 de febrero a un precio promedio de 1954 dólares, y hace dos horas transfirió 7050 ETH de nuevo al CEX; si los vende, obtendrá una ganancia de 1,647 millones de dólares.
GateNewshace1h
En las últimas 24 horas, se liquidaron posiciones apalancadas en todo el mercado por un total de 132 millones de dólares, y la proporción de liquidaciones de posiciones largas fue del 58.8%.
Noticias de Gate News. El 13 de abril, según datos de CoinAnk, en las últimas 24 horas se liquidaron posiciones en todo el mercado por un total de 132 millones de dólares, de los cuales las liquidaciones de posiciones largas fueron de aproximadamente 77,60 millones de dólares y las de posiciones cortas, de aproximadamente 53,93 millones de dólares. Por tipos de moneda, las liquidaciones en Bitcoin fueron de aproximadamente 29,45 millones de dólares y las de Ethereum, de aproximadamente 22,37 millones de dólares.
GateNewshace2h

