في قطاع الذكاء الاصطناعي الحالي، تمثل عملية تصنيف البيانات نسبة كبيرة من تكاليف التطوير. المنصات المركزية التقليدية تواجه مشكلات العزلة بين البيانات، وانخفاض الكفاءة، وتوزيع العائدات بشكل غير شفاف. تسعى Tagger إلى معالجة هذه التحديات عبر بنية لامركزية تجعل إنتاج البيانات أكثر انفتاحًا وكفاءة وقابلية للتحقق.
من منظور البلوكشين والأصول الرقمية، تكمن القيمة الأساسية لـ Tagger في تحويل "البيانات" إلى أصول قابلة للتحقق والتداول، مع استخدام الحوافز الرمزية لتعزيز الإنتاج التعاوني العالمي. بذلك تتحول البيانات من مجرد مورد لتدريب الذكاء الاصطناعي إلى عنصر محوري في النظام الاقتصادي لـ Web3.
نظرة عامة على آلية تصنيف البيانات في Tagger (TAG)
تعمل آلية تصنيف البيانات في Tagger كنظام إنتاج بيانات لامركزي، وهدفها الأساسي تحويل البيانات الخام إلى أصول بيانات منظمة وجاهزة لنماذج الذكاء الاصطناعي. يتكون النظام من أربع مراحل: جمع البيانات، التصنيف، التحقق، والتسليم، ليشكل خط معالجة بيانات متكامل.
تقسم آلية Tagger عملية إنتاج البيانات إلى وحدات: جمع البيانات، التصنيف، والتحقق. كل وحدة ينفذها فريق مختلف من المشاركين، مما يمنع أي جهة من السيطرة الكاملة على العملية. هذا الأسلوب الموزع يعزز الكفاءة ويقوي مرونة النظام.
تدمج Tagger أدوات مدعومة بالذكاء الاصطناعي مثل AI Copilot في التصنيف، مما يتيح للمستخدمين العاديين تنفيذ مهام معقدة. نموذج التعاون بين الإنسان والآلة يقلل حاجز الدخول للتصنيف الاحترافي للبيانات، ويجذب المزيد من المشاركين ويوسع إمداد البيانات بسرعة.
آلية التصنيف في Tagger تتجاوز التعهيد الجماعي التقليدي، إذ تدمج التحقق المستند إلى البلوكشين، والمساعدة بالذكاء الاصطناعي، وآليات الحوافز، لتشكل بنية تحتية جديدة لإنتاج بيانات الذكاء الاصطناعي.
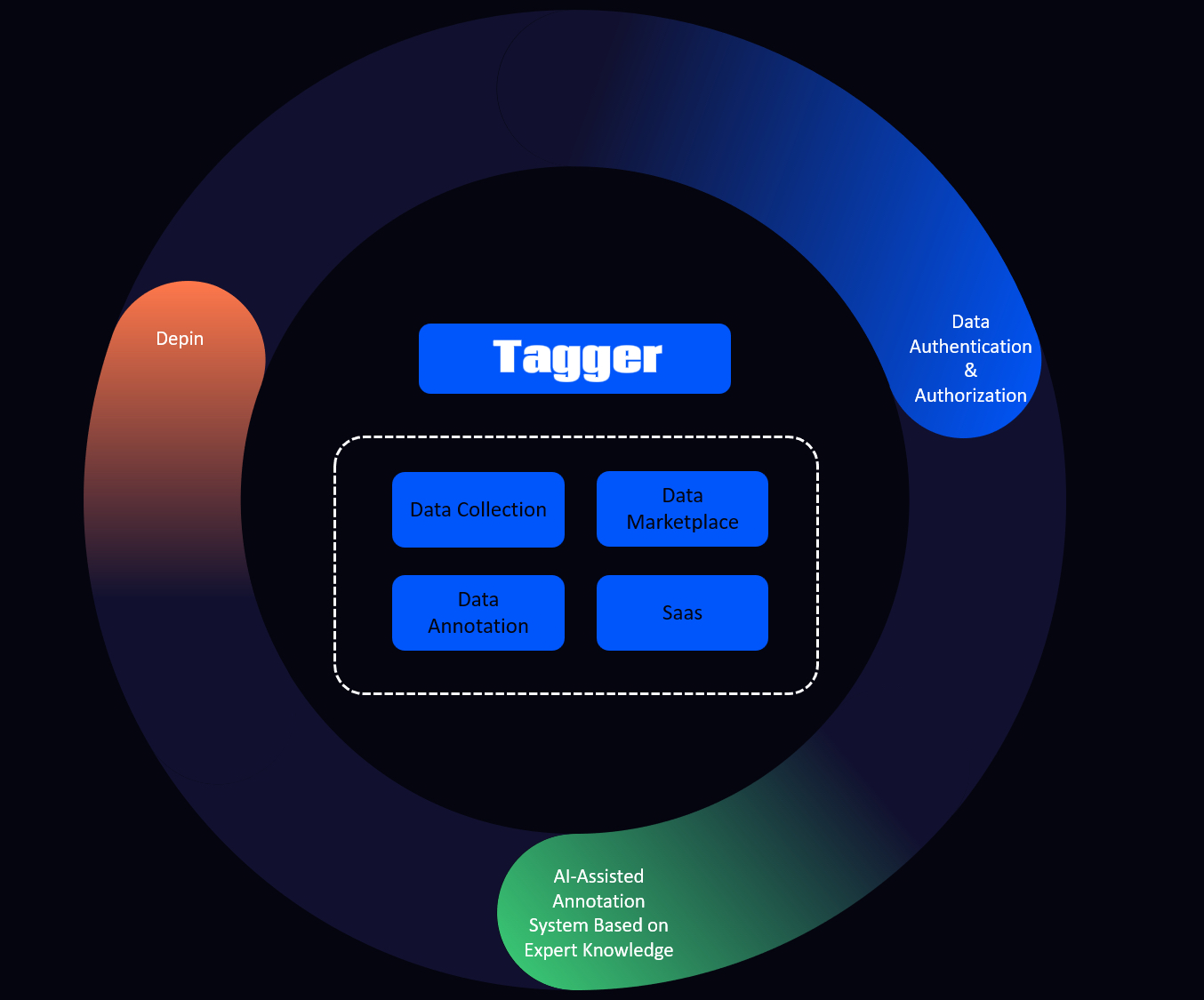
المصدر: tagger.pro
توزيع مهام البيانات في Tagger (TAG): التصنيف الجماعي وتخصيص المهام
في شبكة Tagger، يمثل توزيع مهام البيانات الرابط الرئيسي بين الطلب والعرض. يمكن لمطوري الذكاء الاصطناعي أو الشركات نشر مهام التصنيف على المنصة مع تحديد القواعد والميزانية ومتطلبات الجودة. يقوم النظام بتقسيم المهام إلى مهام فرعية ويوزعها على المشاركين.
يعتمد تخصيص المهام على خوارزميات مطابقة ذكية، حيث يأخذ النظام في الاعتبار نوع المهمة وفئة البيانات وقدرات المشاركين لتعيين كل مهمة إلى العقدة الأنسب. على سبيل المثال، يتم إعطاء الأولوية لمهام تصنيف الصور للمصنفين ذوي الخبرة ذات الصلة، مما يعزز الكفاءة والدقة.
تستخدم Tagger نموذج التعهيد الجماعي لتسريع التوسع. بخلاف فرق التعهيد التقليدية، تستطيع الشبكة اللامركزية تعبئة المستخدمين العالميين في وقت واحد، ما يسرع معالجة البيانات بشكل كبير. وهذا مفيد لمشاريع الذكاء الاصطناعي التي تتطلب معالجة بيانات ضخمة.
أثناء التوزيع، يمكن للعقود الذكية أتمتة تنفيذ المهام والدفع. بعد إكمال المهمة والتحقق منها، يصدر النظام المكافآت تلقائيًا، مما يقلل التدخل اليدوي ويزيد الكفاءة.
التحقق من نتائج التصنيف في Tagger (TAG): مراقبة الجودة والتحقق من البيانات
جودة البيانات أمر أساسي لتدريب الذكاء الاصطناعي، لذا تعتمد Tagger نظام تحقق متعدد الطبقات بعد التصنيف لضمان الدقة والاتساق. يتم التحقق بشكل تعاوني وليس عبر جهة واحدة فقط.
أولًا، يستخدم النظام إجماع المصنفين المتعددين: يتم تصنيف نفس البيانات بشكل مستقل من قبل عدة مشاركين، وتُقبل فقط النتائج المتوافقة أو المتشابهة، ما يقلل تأثير الأخطاء الفردية.
ثانيًا، تدمج Tagger أدوات تحقق مدعومة بالذكاء الاصطناعي لإجراء فحوصات جودة تلقائية. على سبيل المثال، تقوم النماذج بتقييم منطقية التصنيف أو رصد الأخطاء الواضحة، مما يعزز كفاءة مراقبة الجودة.
بالنسبة للبيانات عالية القيمة، قد يتم إدخال آليات السمعة والتخزين. نتائج التصنيف للعقد ذات السمعة العالية تحمل وزنًا أكبر، بينما تؤدي الأعمال منخفضة الجودة إلى عقوبات. هذا يحفز المشاركين على الحفاظ على معايير عالية عبر المكافآت الاقتصادية.
استخدام البيانات المصنفة في Tagger (TAG): تدريب نماذج الذكاء الاصطناعي وتطبيقات البيانات
بعد التصنيف والتحقق، تُستخدم البيانات عمليًا في تدريب وتحسين نماذج الذكاء الاصطناعي. البيانات المصنفة عالية الجودة تعزز دقة النموذج وقدرته على التعميم، ما يجعل هذه المرحلة مركزية في النظام.
في تعلم الآلة، البيانات المصنفة ضرورية للتعلم تحت الإشراف. مثلًا، تتطلب نماذج تصنيف الصور كميات كبيرة من البيانات المصنفة، بينما تعتمد أنظمة التعرف على الكلام على نصوص دقيقة. يمكن استخدام بيانات Tagger مباشرة في هذه الحالات.
بالإضافة إلى التدريب، تُستخدم البيانات المصنفة أيضًا لتقييم النموذج وتحسينه. اختبار النموذج بالبيانات المصنفة يساعد في تقييم الأداء وتعديل المعايير، مما يجعل بيانات Tagger موردًا مهمًا طوال دورة حياة الذكاء الاصطناعي.
تدعم Tagger تداول البيانات والموافقة عليها، ما يسمح بتداول البيانات بين التطبيقات المختلفة. هذا يحول البيانات من مورد يُستخدم مرة واحدة إلى أصل قابل لإعادة الاستخدام، ويزيد من قيمتها الاقتصادية.
تحليل الأداء والكفاءة لآلية التصنيف في Tagger (TAG)
الميزة الأساسية في أداء Tagger هي قابلية التوسع. الشبكة اللامركزية يمكنها توسيع المشاركة ديناميكيًا لتلبية متطلبات معالجة البيانات المختلفة، مما يجعلها مثالية لمشاريع الذكاء الاصطناعي واسعة النطاق.
الأدوات المدعومة بالذكاء الاصطناعي تعزز الكفاءة. التصنيف المسبق والتحقق التلقائي يقللان الأعباء اليدوية، ويتيحان للمصنفين التركيز على القرارات المهمة، مما يزيد الإنتاجية.
ومع ذلك، تفرض اللامركزية بعض التأخير. التحقق متعدد الأطراف يحسن الجودة لكنه قد يطيل أوقات المعالجة، ما يتطلب توازنًا بين الكفاءة والدقة.
في النهاية، يعتمد أداء Tagger على خوارزميات توزيع المهام وآليات التحقق وحجم الشبكة. مع توسع الشبكة، من المتوقع أن تزداد الكفاءة.
مزايا وآفاق آلية التصنيف في Tagger (TAG)
المزايا الرئيسية لـ Tagger هي الانفتاح والتحفيز، حيث تمنح المستخدمين العالميين القدرة على المشاركة في إنتاج البيانات وتوسيع الإمداد بسرعة. التحقق المستند إلى البلوكشين وتتبع البيانات يعزز مصداقية البيانات.
أدوات التصنيف المدعومة بالذكاء الاصطناعي تخفض الحاجز المهني، مما يتيح لغير المتخصصين المساهمة ببيانات عالية الجودة — وهو عامل مهم لمعالجة ندرة البيانات.
ومع ذلك، تبقى بعض التحديات. اختلاف مهارات المشاركين قد يؤثر على اتساق البيانات، ومراقبة الجودة في البيئة اللامركزية أكثر تعقيدًا. وتكون تكاليف تنسيق وإدارة المهام أعلى مقارنة بالأنظمة المركزية.
هناك تصور خاطئ بأن Tagger مجرد "منصة تعهيد جماعي"، لكنها في الواقع اقتصاد بيانات متكامل يشمل الإنتاج والتحقق والتداول والموافقة، مع تعقيد وإمكانات تفوق النماذج التقليدية.
ملخص
Tagger (TAG) تجمع بين البلوكشين والذكاء الاصطناعي والتعهيد الجماعي لبناء شبكة لامركزية لتصنيف البيانات والتحقق منها. ابتكارها الأساسي هو توزيع عملية إنتاج البيانات عالميًا وضمان جودة البيانات عبر أنظمة تحقق وحوافز قوية.
هذا الأسلوب يعزز كفاءة إنتاج البيانات ويوفر إمدادًا مستدامًا للبيانات لتطوير الذكاء الاصطناعي. ومع تحول البيانات إلى أساس الذكاء الاصطناعي، تظهر البنية التحتية اللامركزية للبيانات مثل Tagger كاتجاه رئيسي لدمج Web3 والذكاء الاصطناعي.
الأسئلة الشائعة
كيف تضمن Tagger (TAG) جودة تصنيف البيانات؟
من خلال إجماع المصنفين المتعددين، والتحقق المدعوم بالذكاء الاصطناعي، ونظام السمعة لضمان دقة البيانات.
كيف يختلف تصنيف البيانات في Tagger عن المنصات التقليدية؟
تستخدم Tagger نموذج تعهيد جماعي لامركزي مع التحقق المستند إلى البلوكشين والحوافز، بخلاف المنصات التقليدية التي تسيطر عليها جهات مركزية.
ما دور TAG في عملية تصنيف البيانات؟
يتم استخدام TAG لدفع رسوم المهام وتحفيز المشاركين، وهو المحرك الأساسي لشبكة إنتاج البيانات.
ما هي سيناريوهات التطبيق الرئيسية لبيانات Tagger؟
تدريب نماذج الذكاء الاصطناعي، تحليل البيانات، وتداول البيانات.
هل Tagger مناسبة لمعالجة البيانات واسعة النطاق؟
نعم، بنيتها اللامركزية تتيح التوسع الديناميكي، ما يجعلها مناسبة لمهام البيانات واسعة النطاق.








